=== STORAGE ===
S3
- durable (99.999999999%)
- a best practice is to enable versioning and MFA Delete on S3 buckets
- S3 lifecycle 2 types of actions:
- transition actions (define when to transition to another storage class)
- expiration actions (objects expire, then S3 deletes them on your behalf)
- objects have to be in S3 for > 30 days before lifecycle policy can take effect and move to a different storage class.
- Intelligent Tiering automatically moves data to the most cost-effective storage
- Standard-IA is multi-AZ whereas One Zone-IA is not
- A pre-signed URL gives you access to the object identified in the URL (URL is made up of bucket name, object key, HTTP method, expiration timestamp). If you want to provide an outside partner with an object in S3, providing a pre-signed URL is a more secure (and easier) option than creating an AWS account for them and providing the login, which is more work to then manage and error-prone if you didn’t lock down the account properly.
- You can’t send long-term storage data directly to Glacier, it has to pass through an S3 first
- Accessed via API, if you want to access S3 directly it can require modifying the app to use the API which is extra effort
- Can host a static website but not over HTTPS. For HTTPS use CloudFront+S3 instead.
- Best practice: use IAM policies to grant users fine-grained control to your S3 buckets rather than using bucket ACLs
- Can use multi-part upload to speed up uploads of large files to S3 (>100MB)
- Amazon S3 Transfer Acceleration – leverages Amazon CloudFront’s globally distributed AWS Edge Locations. As data arrives at an AWS Edge Location, data is routed to your Amazon S3 bucket over an optimized network path.
- The name of the bucket used for Transfer Acceleration must be DNS-compliant and must not contain periods (“.”).
- S3 Event Notifications – trigger Lambda functions to do pre-process, like “ObjectCreated:Put” event
- S3 Storage Lens – provide visibility into storage usage and activity trends
- S3 Lifecycle policy – simply manage storage transitions and object expirations
- S3 Object Lambda – only trigger on “object – retrieving”;
- so it’s not ideal for waterproofing unless we want keep S3 objects as untouched as original.
- but it’s good to “redact PII” before sending to application.
- Cross-origin resource sharing (CORS)
- AllowedOrigin – Specifies domain origins that you allow to make cross-domain requests.
- AllowedMethod – Specifies a type of request you allow (GET, PUT, POST, DELETE, HEAD) in cross-domain requests.
- AllowedHeader – Specifies the headers allowed in a preflight request.
- MaxAgeSeconds – Specifies the amount of time in seconds that the browser caches an Amazon S3 response to a preflight OPTIONS request for the specified resource. By caching the response, the browser does not have to send preflight requests to Amazon S3 if the original request will be repeated.
- ExposeHeader – Identifies the response headers that customers are able to access from their applications (for example, from a JavaScript XMLHttpRequest object).
- To upload an object to the S3 bucket, which uses SSE-KMS
- send a request with an x-amz-server-side-encryption header with the value of aws:kms.
- Only with “aws:kms”, it would be SSE-KMS (AWS KMS keys)
- else it may be using (Amazon S3 managed keys), with value “AES256”
- (optional) x-amz-server-side-encryption-aws-kms-key-id header, which specifies the ID of the AWS KMS master encryption key
- If the header is not present in the request, Amazon S3 assumes the default KMS key.
- Regardless, the KMS key ID that Amazon S3 uses for object encryption must match the KMS key ID in the policy, otherwise, Amazon S3 denies the request.
- (optional) supports encryption context with the x-amz-server-side-encryption-context header.
- For a large file uploading (which would use “multipart”)
- The kms:GenerateDataKey permission allows you to initiate the upload.
- The kms:Decrypt permission allows you to encrypt newly uploaded parts with the key that you used for previous parts of the same object.
- send a request with an x-amz-server-side-encryption header with the value of aws:kms.
- Using server-side encryption with customer-provided encryption keys (SSE-C) allows you to set your own encryption keys. With the encryption key you provide as part of your request, Amazon S3 manages both the encryption, as it writes to disks, and decryption, when you access your objects.
- Amazon S3 does not store the encryption key you provide
- only a randomly salted HMAC value of the encryption key in order to validate future requests, which cannot be used to derive the value of the encryption key or to decrypt the contents of the encrypted object
- That means, if you lose the encryption key, you lose the object.
- Headers
- x-amz-server-side-encryption-customer-algorithm – This header specifies the encryption algorithm. The header value must be “AES256”.
- x-amz-server-side-encryption-customer-key – This header provides the 256-bit, base64-encoded encryption key for Amazon S3 to use to encrypt or decrypt your data.
- x-amz-server-side-encryption-customer-key-MD5 – This header provides the base64-encoded 128-bit MD5 digest of the encryption key according to RFC 1321. Amazon S3 uses this header for a message integrity check to ensure the encryption key was transmitted without error.
- Object Integrity
- S3 uses checksum to validate the integrity of uploaded objects
- MD5, MD5 & ETag, SHA-1, SHA-256, CRC32, CRC32C
- ETag – represents a specific version of the object, ETag = MD5 (if SSE-S3)
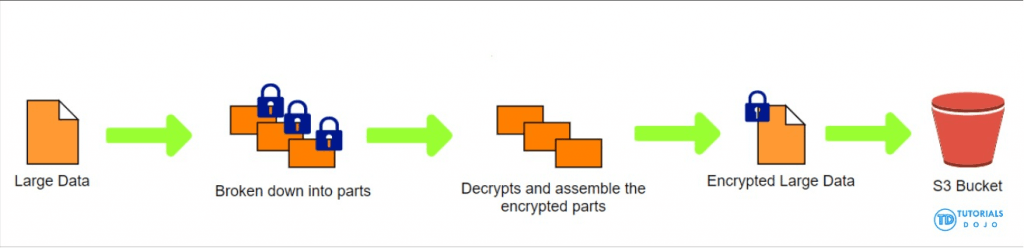
- Replication
- Must enable Versioning in source and destination buckets
- Buckets can be in different AWS accounts
- Copying is asynchronous
- Must give proper IAM permissions to S3
- Use cases:
- Cross-Region Replication (CRR) – compliance, lower latency access, replication across accounts
- Same-Region Replication (SRR) – log aggregation, live replication between production and test accounts
- After you enable Replication, only new objects are replicated
- Optionally, you can replicate existing objects using S3 Batch Replication
- Replicates existing objects and objects that failed replication
- For DELETE operations
- Can replicate delete markers from source to target (optional setting)
- Deletions with a version ID are not replicated (to avoid malicious deletes)
- There is no “chaining” of replication
- If bucket 1 has replication into bucket 2, which has replication into bucket 3
- Then objects created in bucket 1 are not replicated to bucket 3
- By default, Amazon S3 allows both HTTP and HTTPS requests
- To determine HTTP or HTTPS requests in a bucket policy, use a condition that checks for the key “aws:SecureTransport”.
- When this key is true, this means that the request is sent through HTTPS.
- To be sure to comply with the s3-bucket-ssl-requests-only rule, create a bucket policy that explicitly denies access when the request meets the condition “aws:SecureTransport”: “false”. This policy explicitly denies access to HTTP requests.
- To determine HTTP or HTTPS requests in a bucket policy, use a condition that checks for the key “aws:SecureTransport”.
- Granting account access to a group
- Amazon S3 has a set of predefined groups
- -Authenticated Users group – Represented by /AuthenticatedUsers. This group represents all AWS accounts. Access permission to this group allows any AWS account to access the resource. However, all requests must be signed (authenticated).
- -All Users group – Represented by /AllUsers. Access permission to this group allows anyone in the world access to the resource. The requests can be signed (authenticated) or unsigned (anonymous). Unsigned requests omit the Authentication header in the request.
- -Log Delivery group – Represented by /LogDelivery. WRITE permission on a bucket enables this group to write server access logs to the bucket.
- Access control lists (ACLs) are one of resource-based options that you can use to manage access to your buckets and objects. You can use ACLs to grant basic read/write permissions to other AWS accounts
- Amazon S3 has a set of predefined groups
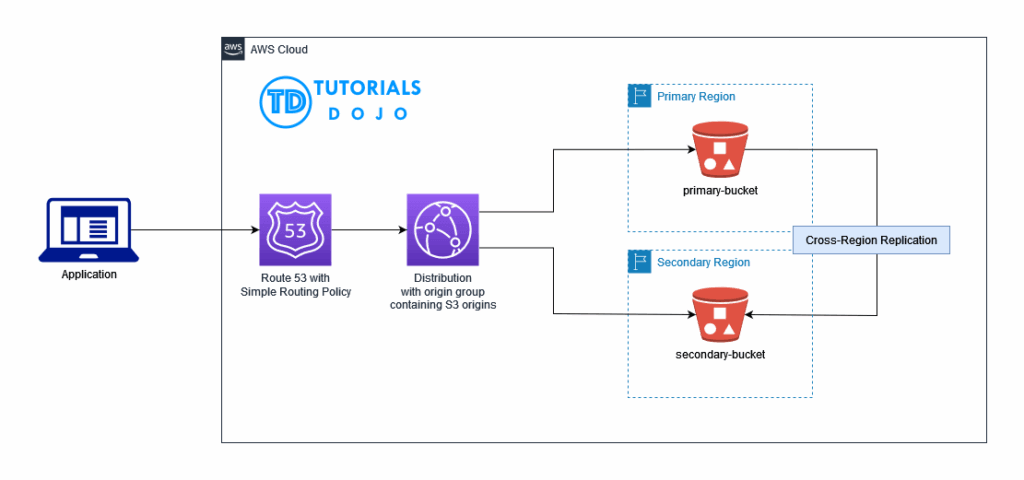
- [ 🧐QUESTION🧐 ] enable the replications across regions and users must use the same endpoint to access the assets, as always be accessible
- AWS CloudFormation StackSets extends the capability of stacks by enabling you to create, update, or delete stacks across multiple accounts and AWS Regions with a single operation.
- S3 Replication enables automatic, asynchronous copying of objects across Amazon S3 buckets. You can replicate objects to a single destination bucket or to multiple destination buckets. The destination buckets can be in different AWS Regions or within the same Region as the source bucket. S3 Replication requires that the source and destination buckets must have versioning enabled.
- CloudFront origin group can be used to configure origin failover for scenarios when you need high availability. Use origin failover to designate a primary origin for CloudFront plus a second origin that CloudFront automatically switches to when the primary origin returns specific HTTP status code failure responses.
- Route 53 has several routing policies to choose from, which determines how Route 53 responds to queries. This includes:
- -Simple routing policy – Use for a single resource that performs a given function for your domain, for example, a web server that serves content for the example.com website. You can use simple routing to create records in a private hosted zone.
- -Failover routing policy – Use when you want to configure active-passive failover. You can use failover routing to create records in a private hosted zone.
- In this scenario, StackSets provides an operationally efficient multi-Region deployment strategy for the Region-specific Amazon S3 buckets. S3 replication then copies new and existing objects in the primary Region to multiple deployment Regions. We can leverage a CloudFront distribution to make a single endpoint available to resolve these multiple S3 origins. Since the CloudFront origin configurations are already handling the failover, we can set Route 53 to use a simple routing policy.
Glacier
- slow to retrieve, but you can use Expedited Retrieval to bring it down to just 1-5min.
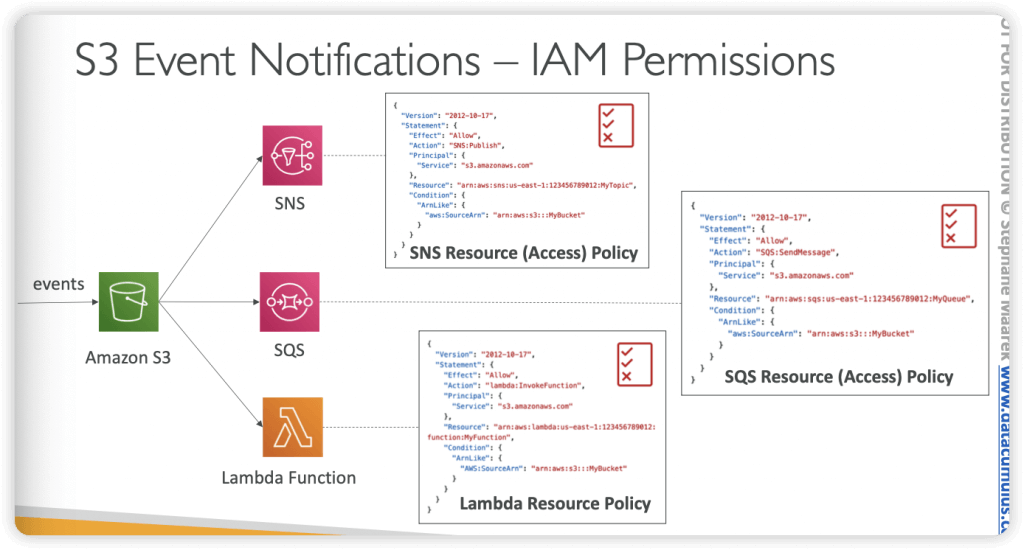
S3 Event Notifications
- S3:ObjectCreated, S3:ObjectRemoved, S3:ObjectRestore, S3:Replication…
- Object name filtering possible (*.jpg)
- Use case: generate thumbnails of images uploaded to S3
- Can create as many “S3 events” as desired
- S3 event notifications typically deliver events in seconds but can sometimes take a minute or longer
- with Amazon EventBridge
- Advanced filtering options with JSON rules (metadata, object size, name…)
- Multiple Destinations – ex Step Functions, Kinesis Streams / Firehose…
- EventBridge Capabilities – Archive, Replay Events, Reliable delivery
Instance Store
- Block-level storage (with EBS disk that is physically attached to the host computer)
- Temporary/ephemeral, ideal for
- temp info that changes frequently such as caches, buffers, scratch data,
- data that is replicated across a fleet of instances where you can afford to lose a copy once in a while and the data is still replicated across other instances
- Very high performance and low latency
- Can be cost effective since the cost is included in the instance cost
- You can hibernate the instance to keep what’s in memory and in the EBS, but if you stop or terminate the instance then you lose everything in memory and in the EBS storage.
EBS
- General Purpose SSD (gp2, gp3) – for low-latency interactive apps, dev&test environments.
- Can have bursts of CPU performance but not sustained.
- Provisioned IOPS SSD (io1, io2) – for sub-millisecond latency, sustained IOPS performance.
- Be sure to distinguish: IOPS solves I/O aka disk wait time, not CPU performance
- IOPS is related to volume size, specifically per GB.
- These are more $
- In contrast to SSD volumes, EBS also offers HDD volumes:
- EBS Cold HDD (sc1) lowest cost option for infrequently accessed data and use cases like sequential data access
- EBS Throughput Optimized HDD (st1) which is for frequent access and throughput intensive workloads such as MapReduce, Kafka, log processing, data warehouse and ETL workloads. Higher $ than sc1.
- however note that the HDD volumes have no IOPS SLA.
- EBS can’t attach to multiple AZs (there is a new EBS multi-attach feature but it’s only single AZ, and only certain SSD volumes such as iop1, iop2). EBS is considered a “single point of failure”.
- To implement a shared storage layer of files, you could replace multiple EBS with a single EFS
- Not fully managed, doesn’t auto-scale (as opposed to EFS)
- Use EBS Data Lifecycle Manager (DLM) to manage backup snapshots. Backup snapshots are incremental, but the deletion process is design so that you only need to retain the most recent snapshot.
- iSCSI is block protocol, whereas NFS is a file protocol
- EBS supports encryption of data at rest and encryption of data in transit between the instance and the EBS volume.
EFS
- can attach to many instances across multiple AZ, whereas EBS cannot (there is a new EBS multi-attach feature but it’s only single AZ, and only certain SSD volumes such as iop1, iop2)
- fully managed, auto-scales (whereas EBS is not)
- Linux only, not Windows!
- Since it is Linux, use POSIX permissions to restrict access to files
- After a period up to 90 days, you can transition unused data to EFS IA
- Protected by EFS Security Groups to control network traffic and act as firewall
Amazon FSx
- to replace Microsoft Windows file server
- can be multi-AZ
- supports DFS (distributed file system) protocol
- integrates with AD
- FSx for Lustre is for high-performance computing (HPC) and machine learning workloads – does not support Windows
- efficiently handles the high I/O operations required for processing high-resolution videos
- optimized for both sequential and random access workloads
=== DATABASE ===
DynamoDB
- Fully managed, highly available with replication across multiple AZs
- NoSQL database – not a relational database – with transaction support
- Scales to massive workloads, distributed database
- Millions of requests per seconds, trillions of row, 100s of TB of storage
- Fast and consistent in performance (single-digit millisecond)
- auto-scaling capabilities
- No maintenance or patching, always available
- Standard & Infrequent Access (IA) Table Class
- DynamoDB is made of Tables
- Each table has a Primary Key (must be decided at creation time)
- Each table can have an infinite number of items (= rows)
- Each item has attributes (can be added over time – can be null)
- Maximum size of an item is 400KB
- Data types supported are:
- Scalar Types – String, Number, Binary, Boolean, Null
- Document Types – List, Map
- Set Types – String Set, Number Set, Binary Set
- Therefore, in DynamoDB you can rapidly evolve schemas
- Read/Write Capacity Modes
- Provisioned Mode (default)
- You specify the number of reads/writes per second
- You need to plan capacity beforehand
- Pay for provisioned Read Capacity Units (RCU) & Write Capacity Units (WCU)
- Possibility to add auto-scaling mode for RCU & WCU
- On-Demand Mode
- Read/writes automatically scale up/down with your workloads
- No capacity planning needed
- Pay for what you use, more expensive ($$$)
- Great for unpredictable workloads, steep sudden spikes
- Provisioned Mode (default)
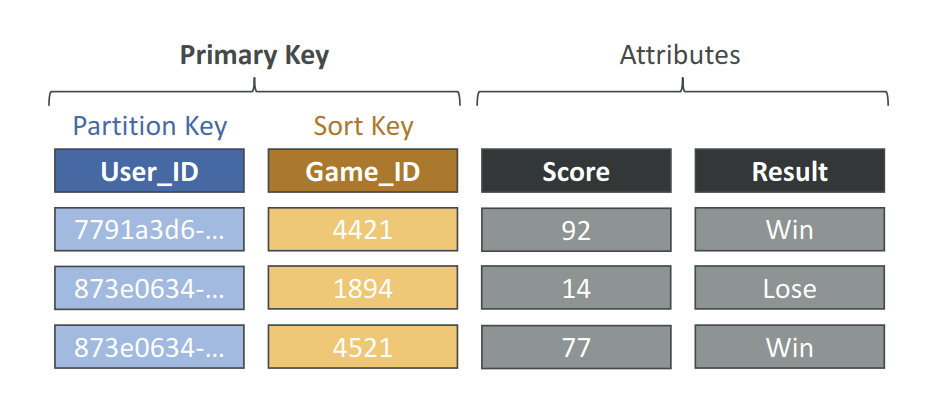
- Time To Live (TTL) for DynamoDB allows you to define when items in a table expire so that they can be automatically deleted from the database.
- DynamoDB returns all of the item attributes by default. To get just some, rather than all of the attributes, use a projection expression
- condition expressions – is used to determine which items should be modified for data manipulation operations such as PutItem, UpdateItem, and DeleteItem calls
- expression attribute names – a placeholder that you use in a projection expression as an alternative to an actual attribute name
- filter expressions – determines which items (and not the attributes) within the Query results should be returned
- Throughput Capacity
- One read request unit represents one strongly consistent read operation per second, or two eventually consistent read operations per second, for an item up to 4 KB in size.
- One write request unit represents one write operation per second, for an item up to 1 KB in size.
- For any “transactional” operation (read or write), double the request units needed.
- Partitions throttled
- Increase the amount of read or write capacity (RCU and WCU) for your table to anticipate short-term spikes or bursts in read or write operations.
- Cons: manual config, also expensive
- Implement error retries and exponential backoff.
- Distribute your read operations and write operations as evenly as possible across your table.
- Implement a caching solution, such as DynamoDB Accelerator (DAX) or Amazon ElastiCache.
- Cons: only works for massive read; also expensive
- Increase the amount of read or write capacity (RCU and WCU) for your table to anticipate short-term spikes or bursts in read or write operations.
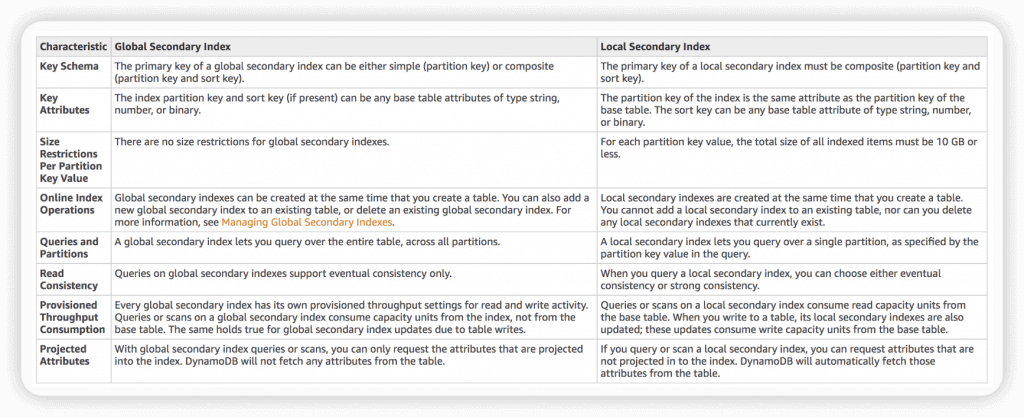
- Global Secondary Index is an index with a partition key and a sort key that can be different from those on the base table.
- To speed up queries on non-key attributes
- Can span all of the data in the base table, across all partitions.
- “CreateTable” operation with the “GlobalSecondaryIndexes” parameter
- 20 global secondary indexes (default limit) per table
- only “eventual consistency”
- Local Secondary Index cannot add into existing table; but Global Secondary Index can.

- DynamoDB Global Tables
- Make a DynamoDB table accessible with low latency in multiple-regions
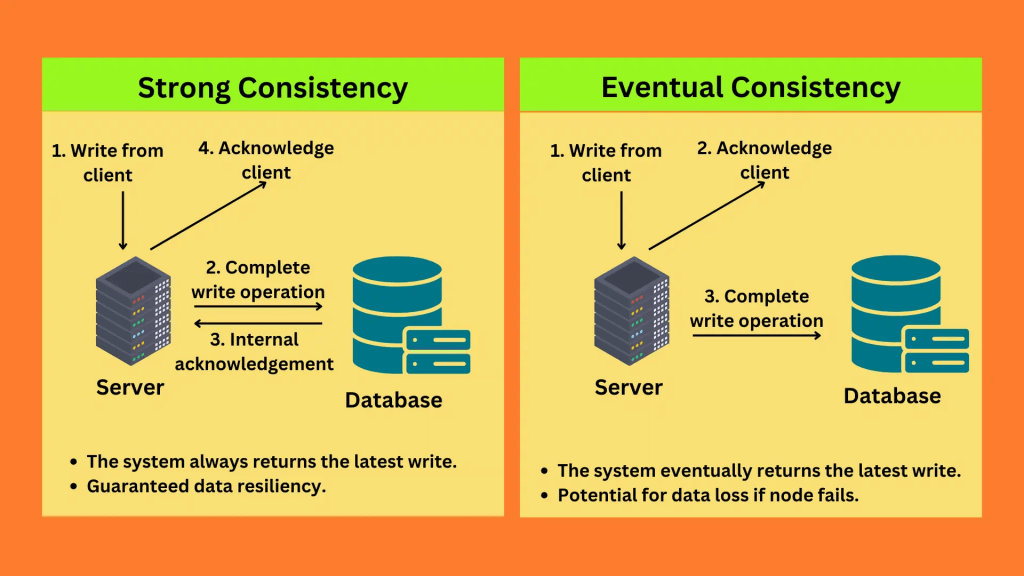
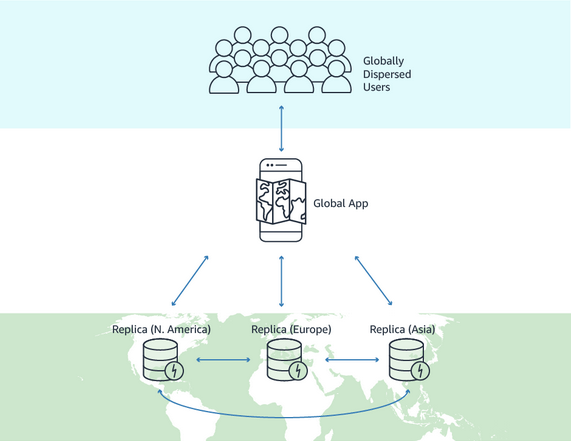
- a fully managed, multi-Region, and multi-active database option that delivers fast and localized read and write performance for massively scaled global applications.
- Global tables provide automatic multi-active replication to AWS Regions worldwide.
- Active-Active replication
- Applications can READ and WRITE to the table in any region
- Must enable DynamoDB Streams as a pre-requisite
- Make a DynamoDB table accessible with low latency in multiple-regions
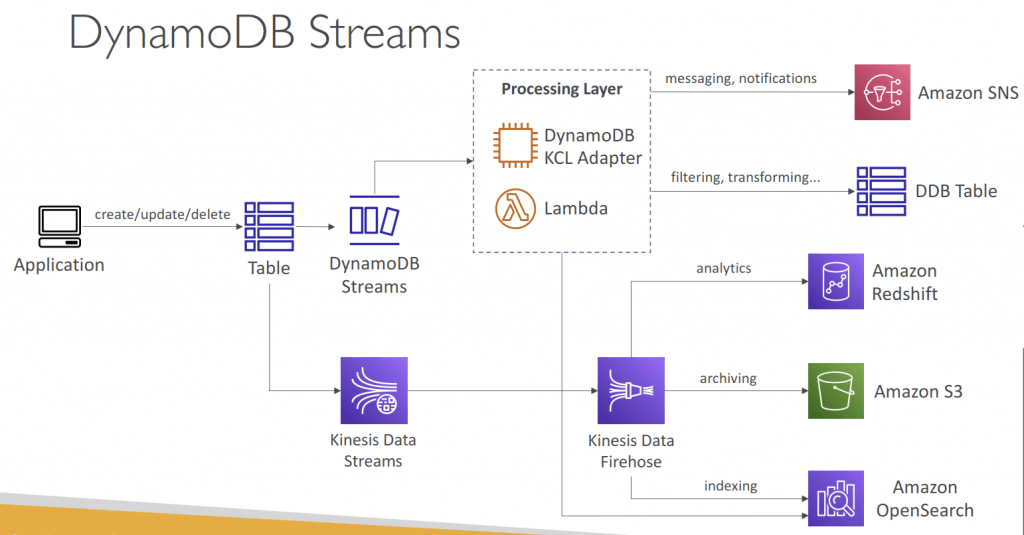
- Amazon DynamoDB Streams
- Process using AWS Lambda Triggers, or DynamoDB Stream Kinesis adapter
- All data in DynamoDB Streams is subject to a 24-hour lifetime.
- Ordered stream of item-level modifications (create/update/delete) in a table
- Use cases:
- React to changes in real-time (welcome email to users)
- Real-time usage analytics
- Inser t into derivative tables
- Implement cross-region replication
- Invoke AWS Lambda on changes to your DynamoDB table
- StreamEnabled (Boolean)
- StreamViewType (string)
- KEYS_ONLY – Only the key attributes of the modified items are written to the stream.
- NEW_IMAGE – The entire item, as it appears after it was modified, is written to the stream.
- OLD_IMAGE – The entire item, as it appeared before it was modified, is written to the stream.
- NEW_AND_OLD_IMAGES – Both the new and the old item images of the items are written to the stream.
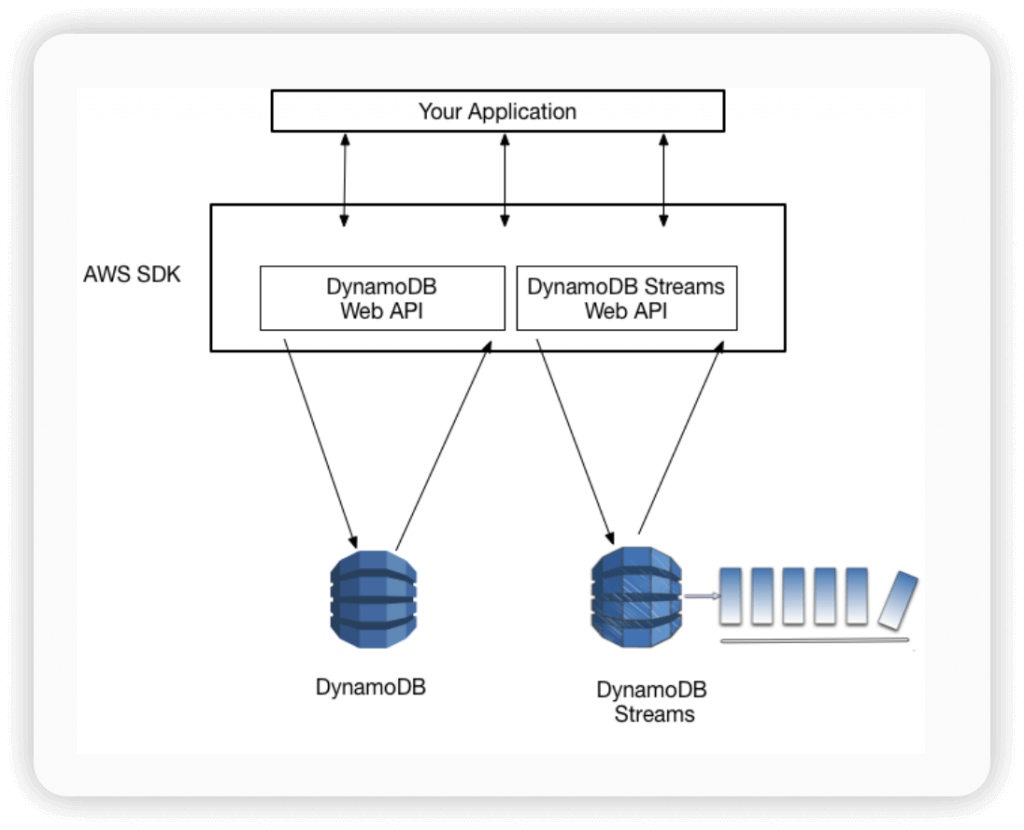
- Amazon DynamoDB Accelerator (DAX) is a fully managed, highly available, in-memory cache for DynamoDB
- Help solve read congestion by caching
- Microseconds latency for cached data
- 5 minutes TTL for cache (default)
- works transparently with existing DynamoDB API calls, and the application code does not need to be modified to take advantage of the caching layer.
- Item Cache — Used to store results of GetItem and BatchGetItem operations
- Query Cache —Used to store results of Query and Scan operations
- – As an in-memory cache, DAX reduces the response times of eventually consistent read workloads by an order of magnitude, from single-digit milliseconds to microseconds.
- – DAX reduces operational and application complexity by providing a managed service that is API-compatible with DynamoDB. Therefore, it requires only minimal functional changes to use with an existing application.
- – For read-heavy or bursty workloads, DAX provides increased throughput and potential operational cost savings by reducing the need to over-provision read capacity units. This is especially beneficial for applications that require repeated reads for individual keys

- For massive read requests
- using “Query” rather than “Scan” operation
- reducing page size (because Scan operation reads an entire page (default 1MB)
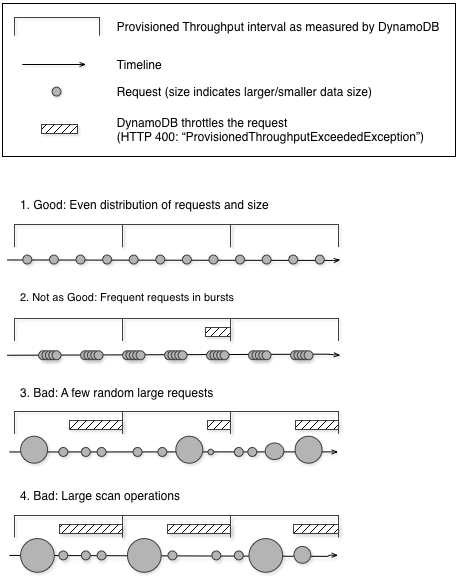
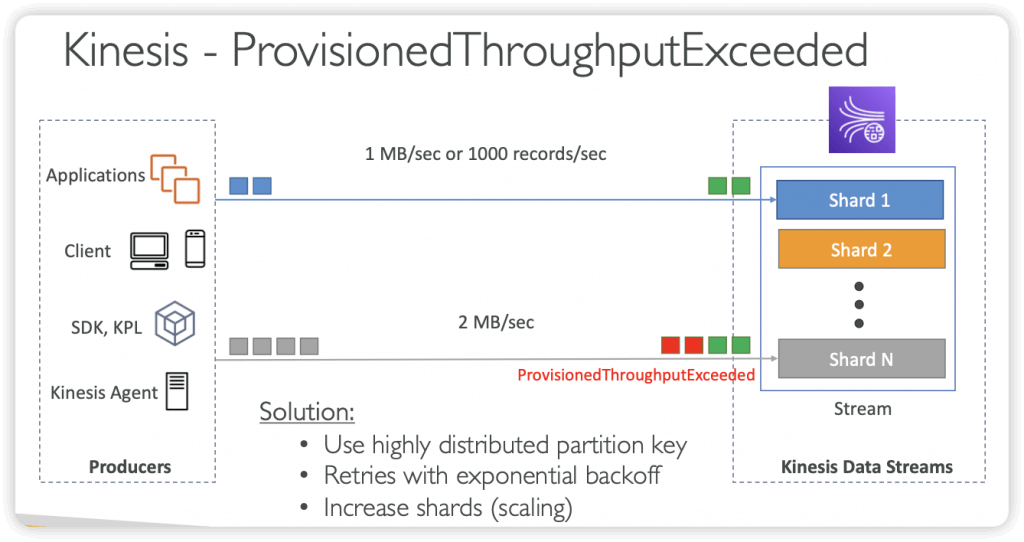
- ProvisionedThroughputExceededException means that your request rate is too high. The AWS SDKs for DynamoDB automatically retries requests that receive this exception.
- Reduce the frequency of requests using error retries and exponential backoff
- Backups for disaster recovery
- Continuous backups using point-in-time recovery (PITR)
- Optionally enabled for the last 35 days
- Point-in-time recovery to any time within the backup window
- The recovery process creates a new table
- On-demand backups
- Full backups for long-term retention, until explicitely deleted
- Doesn’t affect performance or latency
- Can be configured and managed in AWS Backup (enables cross-region copy)
- The recovery process creates a new table
- Continuous backups using point-in-time recovery (PITR)
- Integration with Amazon S3
- Export to S3 (must enable PITR)
- Works for any point of time in the last 35 days
- Doesn’t affect the read capacity of your table
- Perform data analysis on top of DynamoDB
- Retain snapshots for auditing
- ETL on top of S3 data before importing back into DynamoDB
- Export in DynamoDB JSON or ION format
- Import from S3
- Import CSV, DynamoDB JSON or ION format
- Doesn’t consume any write capacity
- Creates a new table
- Import errors are logged in CloudWatch Logs
- Export to S3 (must enable PITR)
- —–
- Use when the question talks about key/value storage, near-real time performance, millisecond responsiveness, and very high requests per second
- Not compatible with relational data such as what would be stored in a MySQL or RDS DB
- DynamoDB measures RCUs (read capacity units, basically reads per second) and WCUs (write capacity units)
- DynamoDB auto scaling uses the AWS Application Auto Scaling service to dynamically adjust throughput capacity based on traffic.
- Best practices:
- keep item sizes small (<400kb) otherwise store in S3 and use pointers from DynamoDB
- store more frequently and less frequently accessed data in different tables
- if storing data that will be accessed by timestamp, use separate tables for days, weeks, months

RDS & Aurora
- Transactional DB (OLTP)
- If too much read traffic is clogging up write requests, create an RDS read replica and direct read traffic to the replica. The read replica is updated asynchronously. Multi-AZ creates a read replica in another AZ and synchronously replicates to it
- RDS is a managed database, not a data store. Careful in some questions if they ask about migrating a data store to AWS, RDS would not be suitable.
- To encrypt an existing RDS database, take a snapshot, encrypt a copy of the snapshot, then restore the snapshot to the RDS instance. Since there may have been data changed during the snapshot/encrypt/load operation, use the AWS DMS (Database Migration Service) to sync the data.
- RDS can be restored to a backup taken as recent as 5min ago using point-in-time restore (PITR). When you restore, a new instance is created from the DB snapshot and you need to point to the new instance.
- RDS Enhanced Monitoring metrics – get the specific percentage of the CPU bandwidth and total memory consumed by each database process
- Amazon RDS supports using Transparent Data Encryption (TDE) to encrypt stored data on your DB instances running Microsoft SQL Server. TDE automatically encrypts data before it is written to storage, and automatically decrypts data when the data is read from storage.
- RDS encryption uses the industry standard AES-256 encryption algorithm to encrypt your data on the server that hosts your RDS instance. With TDE, the database server automatically encrypts data before it is written to storage and automatically decrypts data when it is read from storage.
- RDS Proxy helps you manage a large number of connections from Lambda to an RDS database by establishing a warm connection pool to the database.
- Notifications
- Amazon RDS uses the Amazon Simple Notification Service (Amazon SNS) to provide notification when an Amazon RDS event occurs. These notifications can be in any notification form supported by Amazon SNS for an AWS Region, such as an email, a text message, or a call to an HTTP endpoint.
- For Amazon Aurora, events occur at both the DB cluster and the DB instance level, so you can receive events if you subscribe to an Aurora DB cluster or an Aurora DB instance.
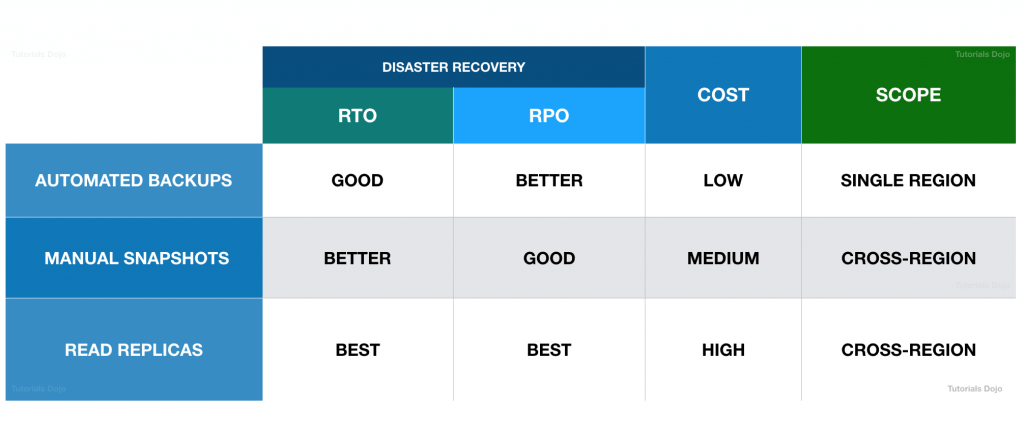
- Read Replicas
- Read Scalibility
- Up to 15 Read Replicas
- Within AZ, Cross AZ or Cross Region
- Replication is ASYNC, so reads are eventually consistent
- Replicas can be promoted to their own DB
- Applications must update the connection string to leverage read replicas
- Use Cases
- You have a production database that is taking on normal load
- You want to run a reporting application to run some analytics
- You create a Read Replica to run the new workload there
- The production application is unaffected
- Read replicas are used for SELECT (=read) only kind of statements (not INSERT, UPDATE, DELETE)
- Cost
- same region, no “data transfer fee”
- cross regions, the async replication would incur the transfer fee
- a cross-region snapshot doesn’t provide a high RPO compared with a Read Replica since the snapshot takes significant time to complete. Although this is better than Multi-AZ deployments since you can replicate your database across AWS Regions, using a Read Replica is still the best choice for providing a high RTO and RPO for disaster recovery.
- RDS Multi AZ (Disaster Recovery)
- SYNC replication
- One DNS name – automatic app failover to standby
- Increase availability
- Failover in case of loss of AZ, loss of network, instance or storage failure
- No manual intervention in apps
- Not used for scaling
- Aurora multi-master & Amazon RDS Multi-AZ
- has its data replicated across multiple Availability Zones only but not to another AWS Region
- still experience downtime in the event of an AWS Region outage
- To prevent Regions failure
- Cross Region Read Replicas
- or Aurora Global Database
- Note: The Read Replicas be setup as Multi AZ for Disaster Recovery (DR)
- Steps for From Single-AZ to Multi-AZ
- Zero downtime operation (no need to stop the DB)
- Just click on “modify” for the database, then these would be automatically running
- A snapshot is taken
- A new DB is restored from the snapshot in a new AZ
- Synchronization is established between the two databases
- Amazon RDS scheduled instance lifecycle events
- Engine Version End-of-Support
- Certificate Authority (CA) Certificate Expiration
- Instance Type Upgrades
- Minor Version Upgrades (if enabled)
- Major Version Deprecation
- But, cannot create a snapshot !
- [ 🧐QUESTION🧐 ] the LOWEST recovery time and the LEAST data loss
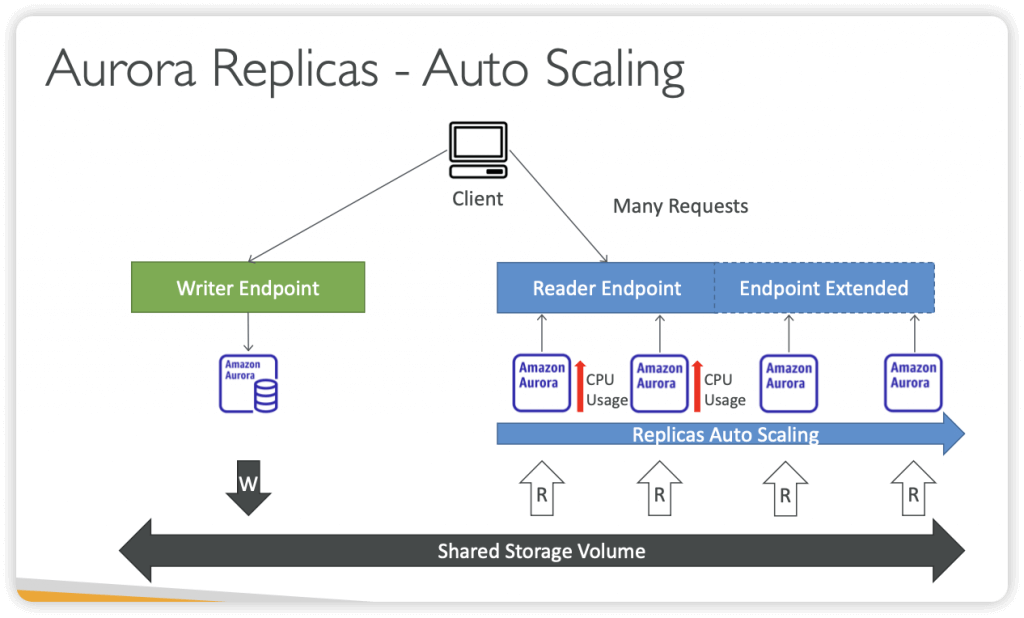
- Read replicas can also be promoted when needed to become standalone DB instances.
- Read replicas in Amazon RDS for MySQL, MariaDB, PostgreSQL, and Oracle provide a complementary availability mechanism to Amazon RDS Multi-AZ Deployments. You can promote a read replica if the source DB instance fails. You can also replicate DB instances across AWS Regions as part of your disaster recovery strategy, which is not available with Multi-AZ Deployments since this is only applicable in a single AWS Region. This functionality complements the synchronous replication, automatic failure detection, and failover provided with Multi-AZ deployments.
- When you copy a snapshot to an AWS Region that is different from the source snapshot’s AWS Region, the first copy is a full snapshot copy, even if you copy an incremental snapshot. A full snapshot copy contains all of the data and metadata required to restore the DB instance. After the first snapshot copy, you can copy incremental snapshots of the same DB instance to the same destination region within the same AWS account.
- Depending on the AWS Regions involved and the amount of data to be copied, a cross-region snapshot copy can take hours to complete. In some cases, there might be a large number of cross-region snapshot copy requests from a given source AWS Region. In these cases, Amazon RDS might put new cross-region copy requests from that source AWS Region into a queue until some in-progress copies complete. No progress information is displayed about copy requests while they are in the queue. Progress information is displayed when the copy starts.
- This means that a cross-region snapshot doesn’t provide a high RPO compared with a Read Replica since the snapshot takes significant time to complete. Although this is better than Multi-AZ deployments since you can replicate your database across AWS Regions, using a Read Replica is still the best choice for providing a high RTO and RPO for disaster recovery.
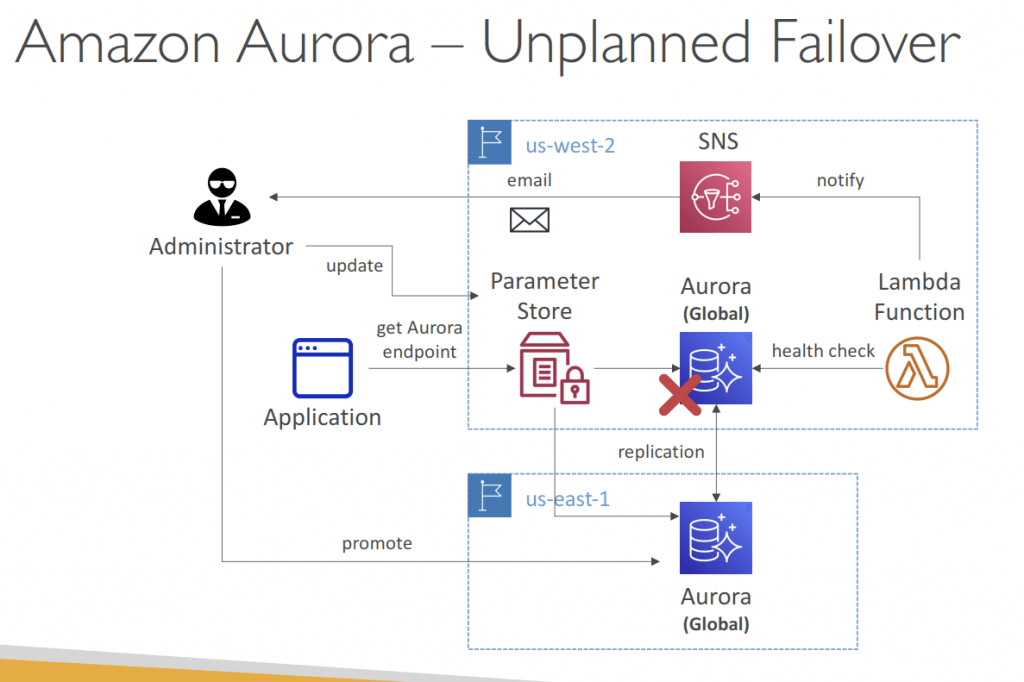
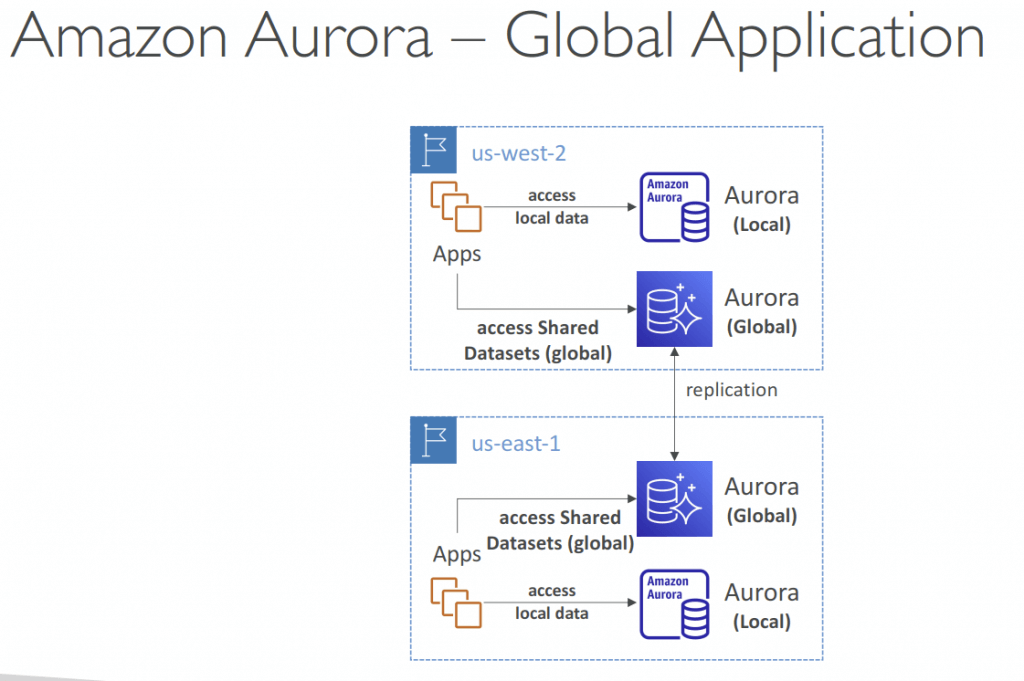
Amazon Aurora Global Database
- for globally distributed applications. 1 DB can span multiple regions
- If too much read traffic is clogging up write requests, create an Aurora replica and direct read traffic to the replica. The replica serves as both standby instance and target for read traffic.
- “Amazon Aurora Serverless” is different from “Amazon Aurora” – it automatically scales capacity and is ideal for infrequently used applications.
- in summary
- 1 Primary Region (read / write)
- Up to 5 secondary (read-only) regions, replication lag is less than 1 second
- Up to 16 Read Replicas per secondary region
- Helps for decreasing latency
- Promoting another region (for disaster recovery) has an RTO of < 1 minute
- Typical cross-region replication takes less than 1 second
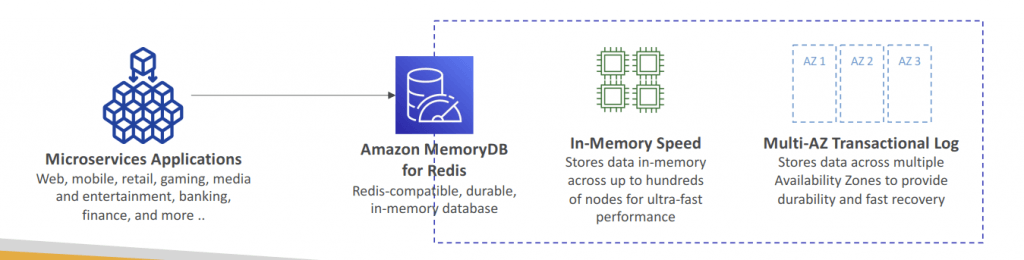
Amazon MemoryDB
- Delivering both in-memory performance and Multi-AZ durability
- Ultra-fast performance with over 160 millions requests/second
- Durable in-memory data storage with Multi-AZ transactional log
- Automatic snapshots in Amazon S3 with retention for up to 35 days
- Support for up to 500 nodes and more than 100 TB of storage per cluster (with 1 replica per shard).
- Use cases: web and mobile apps, online gaming, media streaming, …
- engines: Valkey OSS or Redis OSS
AWS Elemental MediaStore
- Disable on November 2025
- Store and deliver video assets for live streaming media workflows
- making it unsuitable for caching static web content like images and PDFs
- a video origination and just-in-time (JIT) packaging service that allows video providers to securely and reliably deliver live streaming content at scale

=== DATA (STREAM) ===
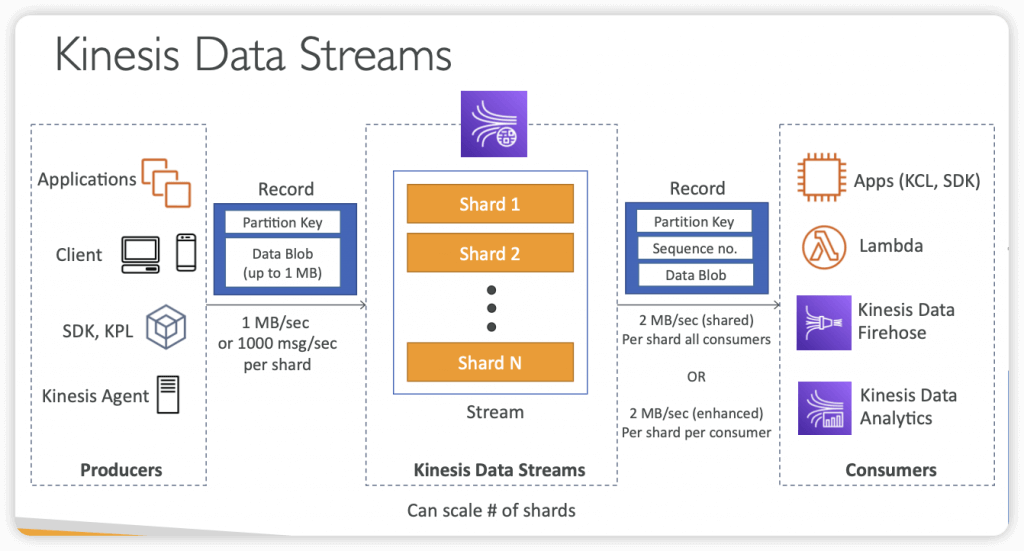
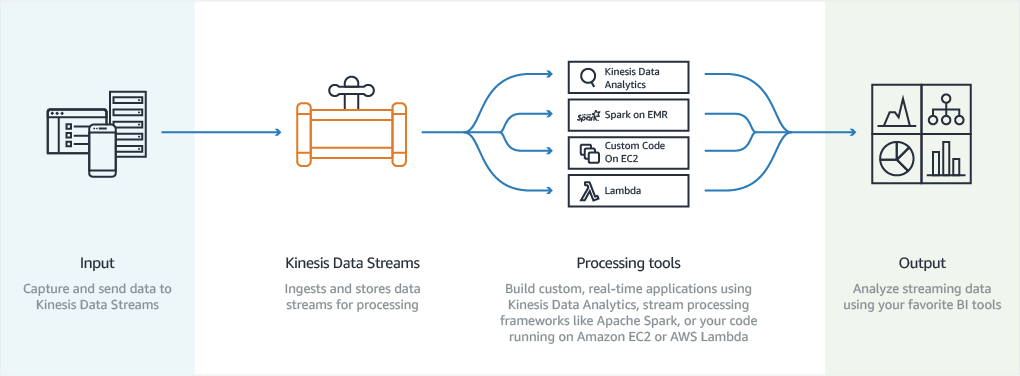
Kinesis Data Streams
- Collect and store streaming data in real-time
- data retention, data replication, and automatic load balancing
- Ability to reprocess (replay) data
- Once data is inserted in Kinesis, it can’t be deleted (immutability)
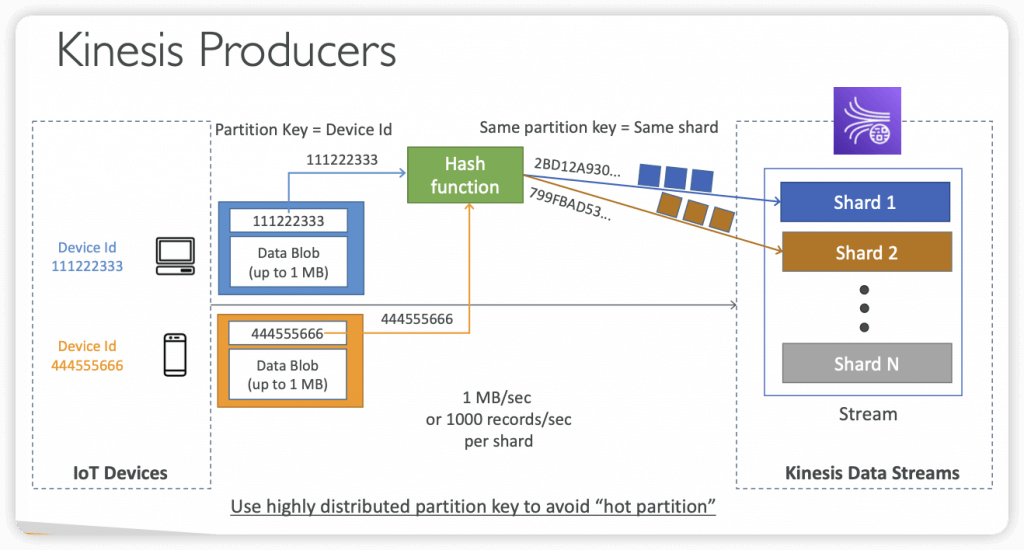
- Data that shares the same partition goes to the same shard (ordering)
- Retention between 24 hours up to 365 days
- Data up to 1MB (typical use case is lot of “small” real-time data)
- Data ordering guarantee for data with the same “Partition ID”
- Capacity Modes
- Provisioned mode
- Each shard gets 1MB/s in (or 1000 records per second)
- Each shard gets 2MB/s out
- On-demand mode
- Default capacity provisioned (4 MB/s in or 4000 records per second)
- So if there are 8KB JSON as 1000 transactions per second to ingest, it means about 8MB/sec input, which would needs 8 shards in provisioned mode.
- Provisioned mode
- Security
- Control access / authorization using IAM policies
- Encryption (default)
- in flight using HTTPS endpoints
- at rest using KMS
- VPC Endpoints available for Kinesis to access within VPC
- Monitor API calls using CloudTrail
- Producers
- Puts data records into data streams
- Data record consists of:
- Sequence number (unique per partition-key within shard)
- Partition key (must specify while put records into stream)
- Data blob (up to 1 MB)
- Sources:
- AWS SDK: simple producer
- Kinesis Producer Library (KPL): C++, Java, batch, compression, retries
- Kinesis Agent: monitor log files
- Write throughput: 1 MB/sec or 1000 records/sec per shard
- PutRecord API
- Use batching with PutRecords API to reduce costs & increase throughput
- Consumers
- Get data records from data streams and process them
- Types
- Write your own
- AWS SDK
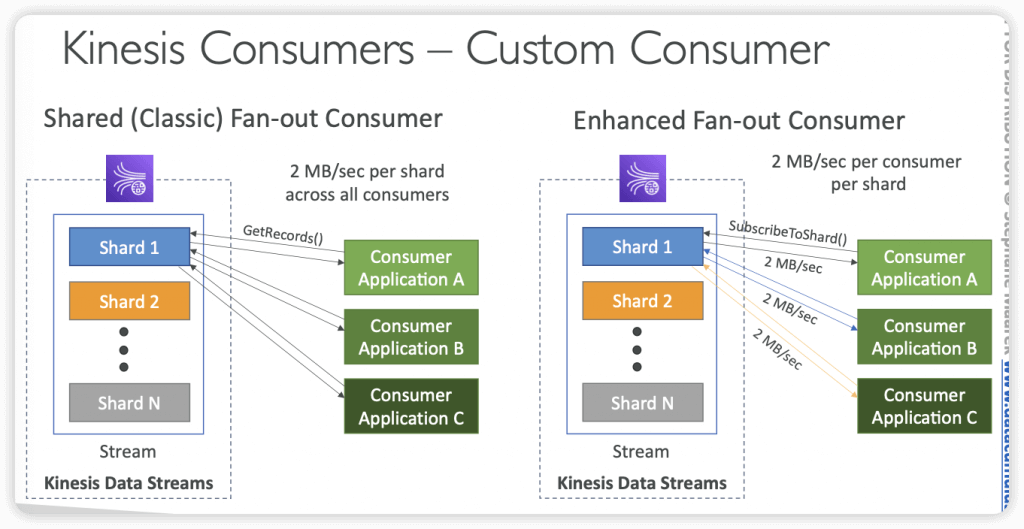
- Shared/Classic Fan-out Consumer
- Low number of consuming applications
- Read throughput: 2 MB/sec per shard across all consumers
- Max. 5 GetRecords API calls/sec
- Latency ~200 ms
- Minimize cost ($)
- Consumers poll data from Kinesis using GetRecords API call
- Returns up to 10 MB (then throttle for 5 seconds) or up to 10000 records
- Enhanced Fan-out Consumer
- Multiple consuming applications for the same stream
- 2 MB/sec per consumer per shard
- Latency ~70 ms
- Higher costs ($$$)
- Kinesis pushes data to consumers over HTTP/2 (SubscribeToShard API)
- Soft limit of 5 consumer applications (KCL) per data stream (default)
- Shared/Classic Fan-out Consumer
- Kinesis Client Library (KCL)
- Java library, read record from a KDS with distributed applications sharing the read workload
- Each shard is to be read by only one KCL instance
- 4 shards = max. 4 KCL instances
- 6 shards = max. 6 KCL instances
- Progress is checkpointed into DynamoDB (needs IAM access)
- Track other workers and share the work amongst shards using DynamoDB
- KCL can run on EC2, Elastic Beanstalk, and on-premises
- Records are read in order at the shard level
- Versions: KCL 1.x (shared), KCL 2.x (shared & enhanced fan-out consumer)
- AWS SDK
- Managed:
- AWS Lambda
- Supports Classic & Enhanced fan-out consumers
- Read records in batches
- Can configure batch size and batch window
- If error occurs, Lambda retries until succeeds or data expired
- Can process up to 10 batches per shard simultaneously
- Kinesis Data Firehose, Kinesis Data Analytics
- AWS Lambda
- Write your own
- Shard Splitting
- Used to increase the Stream capacity (1 MB/s data in per shard)
- Used to divide a “hot shard”
- The old shard is closed and will be deleted once the data is expired
- No automatic scaling (manually increase/decrease capacity)
- Can’t split into more than two shards in a single operation
- Merge Shards
- Decrease the Stream capacity and save costs
- Can be used to group two shards with low traffic (cold shards)
- Old shards are closed and will be deleted once the data is expired
- Can’t merge more than two shards in a single operation
- [ML] create real-time machine learning applications
- by using “Amazon Redshift streaming ingestion”, which simplifies the streaming architecture by providing native integration between Amazon Redshift and the streaming engines in AWS, which are Amazon Kinesis Data Streams and Amazon Managed Streaming for Apache Kafka (Amazon MSK).
- While you can configure Redshift as a destination for an Amazon Data firehose, Kinesis does not actually load the data directly into Redsfhit. Under the hood, Kinesis stages the data first in Amazon S3 and copies it into Redshift using the COPY command.
- The Amazon Kinesis Client Library (KCL) is different from the Kinesis Data Streams APIs that are available in the AWS SDKs. The Kinesis Data Streams APIs help you manage many aspects of Kinesis Data Streams, including creating streams, resharding, and putting and getting records. The KCL provides a layer of abstraction around all these subtasks, specifically so that you can focus on your consumer application’s custom data processing logic.
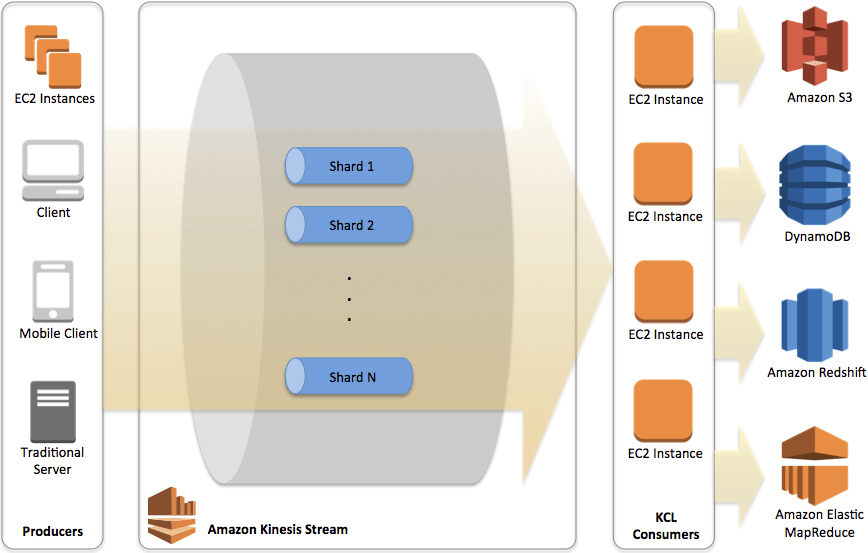
- Real-time Streaming model, enables the collection, processing, and analysis of real-time data at a massive scale, allowing applications to react to new information almost immediately
- for use cases that require ingestion of real-time data (e.g. IoT sensor data, payment processing application with fraud detection)
- Kinesis data stream is made up of shards, which are made up of data records, which each have a sequence #. Then you map devices to partition keys which group data by shard.
- Resharding
- decrease the stream’s capacity by merging shards
- increase the stream’s capacity by splitting shards
- se metrics to determine which are your “hot” or “cold” shards, that is, shards that are receiving much more data, or much less data, than expected.
- Since the Lambda function is using a poll-based event source mapping for Kinesis, the number of shards is the unit of concurrency for the function.
- embed a primary key within the record to remove duplicates later when processing
- Amazon Kinesis Agent is a lightweight software that helps send log and event data from on-premises servers to Amazon Kinesis Data Streams or Data Firehose
- Kinesis Client Library (KCL)
- ensures that for every shard there is a record processor running and processing that shard. It also tracks the shards in the stream using an Amazon DynamoDB table.
- ensure that the number of instances does not exceed the number of shards
- Each shard is processed by exactly one KCL worker and has exactly one corresponding record processor
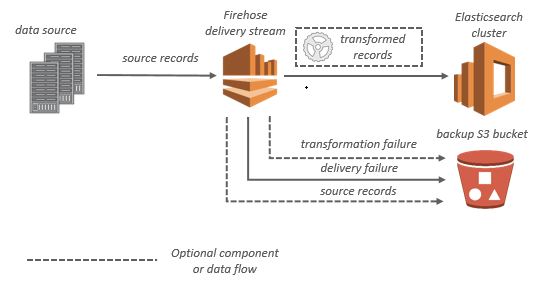
Amazon Data Firehose
- aka Kinesis Data Firehose
- Collect and store streaming data in real-time
- buffers incoming streaming data to a certain size and for a certain period of time before delivering it to the specified destinations
- Buffer size
- Buffer interval
- buffers incoming streaming data to a certain size and for a certain period of time before delivering it to the specified destinations
- Near Real-Time; in another words, suitable for batch processing
- Custom data transformations
- Conversions to Parquet / ORC, compressions with gzip / snappy
- Custom data transformations using AWS Lambda (ex: CSV to JSON)
- It enables on-the-fly data transformation using AWS Lambda and supports automatic scaling to handle varying data loads.
- [ML] ingest massive data near-real time
- Kinesis Data Streams is for when you want to “real-time” control and manage the flow of data yourself, while Kinesis Data Firehose is for when you want the data to be “near-real-time” automatically processed and delivered to a specific destination(Redshift, S3, Splunk, etc.)

| Destination | Details |
|---|---|
| Amazon S3 | For data delivery to Amazon S3, Firehose concatenates multiple incoming records based on the buffering configuration of your Firehose stream. It then delivers the records to Amazon S3 as an Amazon S3 object. By default, Firehose concatenates data without any delimiters. If you want to have new line delimiters between records, you can add new line delimiters by enabling the feature in the Firehose console configuration or API parameter. Data delivery between Firehose and Amazon S3 destination is encrypted with TLS (HTTPS). |
| Amazon Redshift | For data delivery to Amazon Redshift, Firehose first delivers incoming data to your S3 bucket in the format described earlier. Firehose then issues an Amazon Redshift COPY command to load the data from your S3 bucket to your Amazon Redshift provisioned cluster or Amazon Redshift Serverless workgroup. Ensure that after Amazon Data Firehose concatenates multiple incoming records to an Amazon S3 object, the Amazon S3 object can be copied to your Amazon Redshift provisioned cluster or Amazon Redshift Serverless workgroup. For more information, see Amazon Redshift COPY Command Data Format Parameters. |
| OpenSearch Service and OpenSearch Serverless | For data delivery to OpenSearch Service and OpenSearch Serverless, Amazon Data Firehose buffers incoming records based on the buffering configuration of your Firehose stream. It then generates an OpenSearch Service or OpenSearch Serverless bulk request to index multiple records to your OpenSearch Service cluster or OpenSearch Serverless collection. Make sure that your record is UTF-8 encoded and flattened to a single-line JSON object before you send it to Amazon Data Firehose. Also, the rest.action.multi.allow_explicit_index option for your OpenSearch Service cluster must be set to true (default) to take bulk requests with an explicit index that is set per record. For more information, see OpenSearch Service Configure Advanced Options in the Amazon OpenSearch Service Developer Guide. |
| Splunk | For data delivery to Splunk, Amazon Data Firehose concatenates the bytes that you send. If you want delimiters in your data, such as a new line character, you must insert them yourself. Make sure that Splunk is configured to parse any such delimiters. To redrive the data that was delivered to S3 error bucket (S3 backup) back to Splunk, follow the steps mentioned in the Splunk documentation. |
| HTTP endpoint | For data delivery to an HTTP endpoint owned by a supported third-party service provider, you can use the integrated Amazon Lambda service to create a function to transform the incoming record(s) to the format that matches the format the service provider’s integration is expecting. Contact the third-party service provider whose HTTP endpoint you’ve chosen for your destination to learn more about their accepted record format. |
| Snowflake | For data delivery to Snowflake, Amazon Data Firehose internally buffers data for one second and uses Snowflake streaming API operations to insert data to Snowflake. By default, records that you insert are flushed and committed to the Snowflake table every second. After you make the insert call, Firehose emits a CloudWatch metric that measures how long it took for the data to be committed to Snowflake. Firehose currently supports only single JSON item as record payload and doesn’t support JSON arrays. Make sure that your input payload is a valid JSON object and is well formed without any extra double quotes, quotes, or escape characters. |
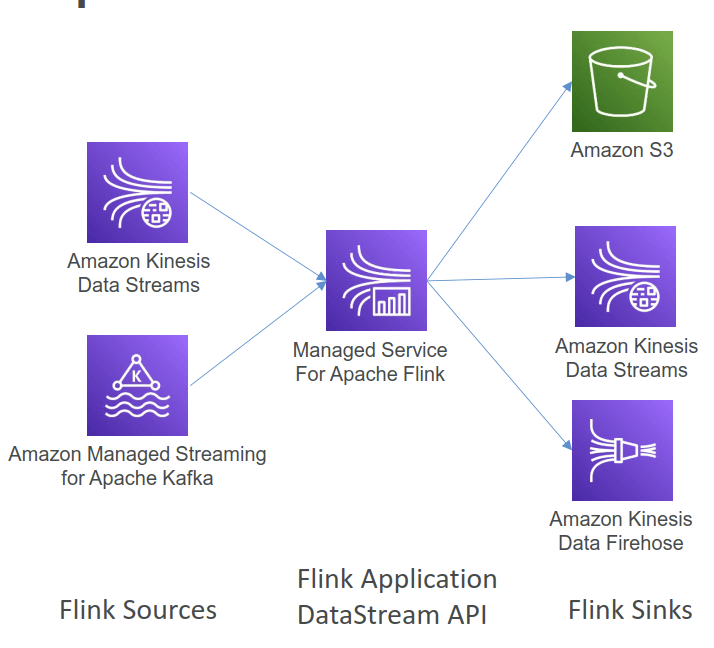
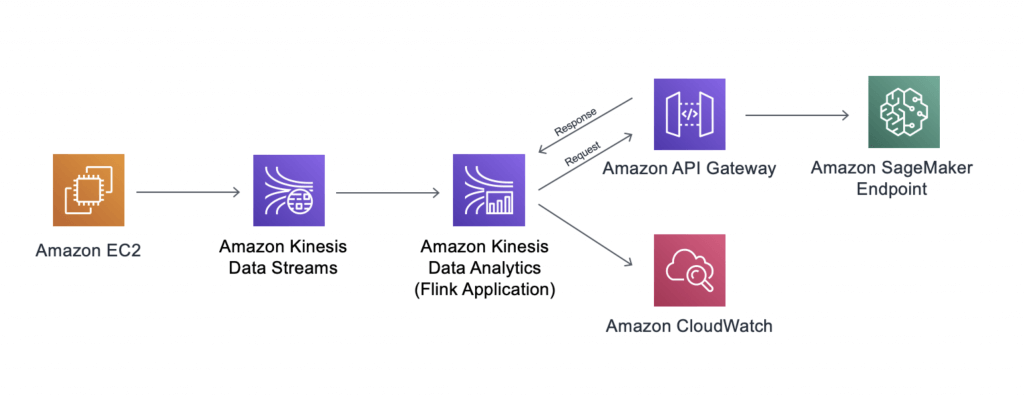
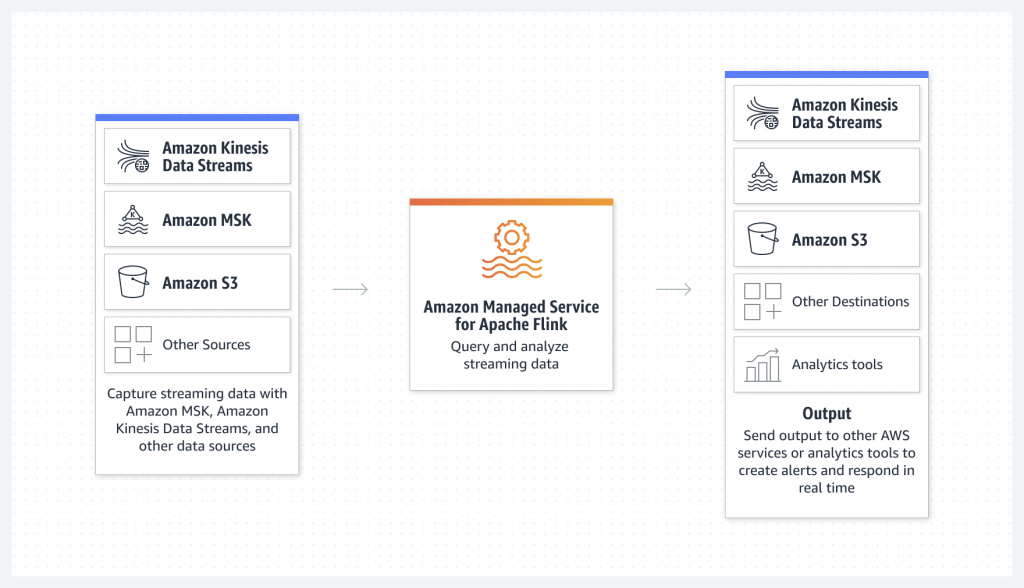
Amazon Kinesis Data Analytics
- aka Amazon Managed Service for Apache Flink
- Apache Flink is an open-source distributed processing engine for stateful computations over data streams. It provides a high-performance runtime and a powerful stream processing API that supports stateful computations, event-time processing, and accurate fault-tolerance guarantees.
- real-time data transformations, filtering, and enrichment
- Flink does not read from Amazon Data Firehose
- AWS Apache Flink clusters
- EC2 instances
- Apache Flink runtime
- Apache ZooKeeper
- Serverless
- Common cases
- Streaming ETL
- Continuous metric generation
- Responsive analytics
- building a real-time anomaly detection system for click-through rates
- with “RANDOM_CUT_FOREST”
- Use IAM permissions to access streaming source and destination(s)
- Schema discovery
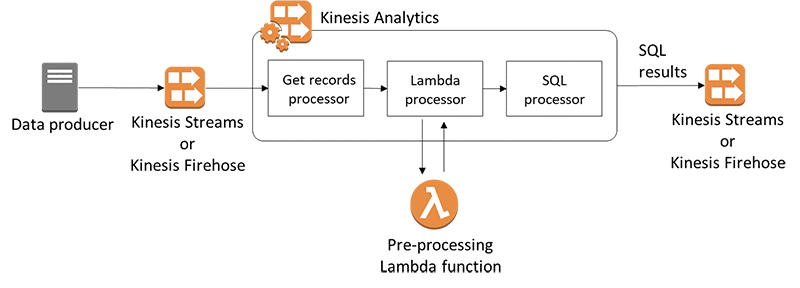
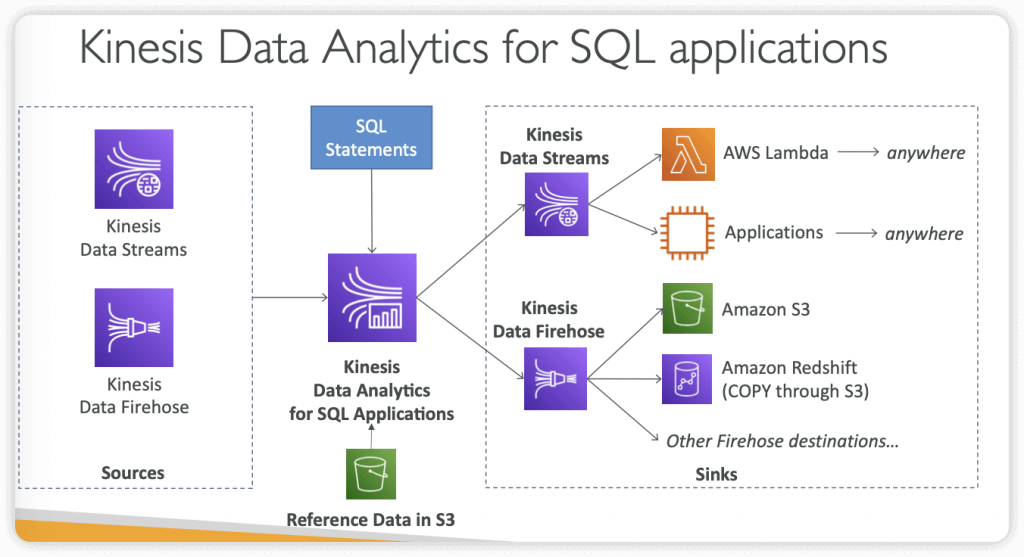
- Kinesis Data Analytics (SQL application)
- Real-time analytics on Kinesis Data Streams & Firehose using SQL
- Add reference data from Amazon S3 to enrich streaming data
- Output:
- Kinesis Data Streams: create streams out of the real-time analytics queries
- Kinesis Data Firehose: send analytics query results to destinations
- Use cases: Time-series analytics, Real-time dashboards, Real-time metrics
- [ML] real-time ETL / ML algorithms on streams
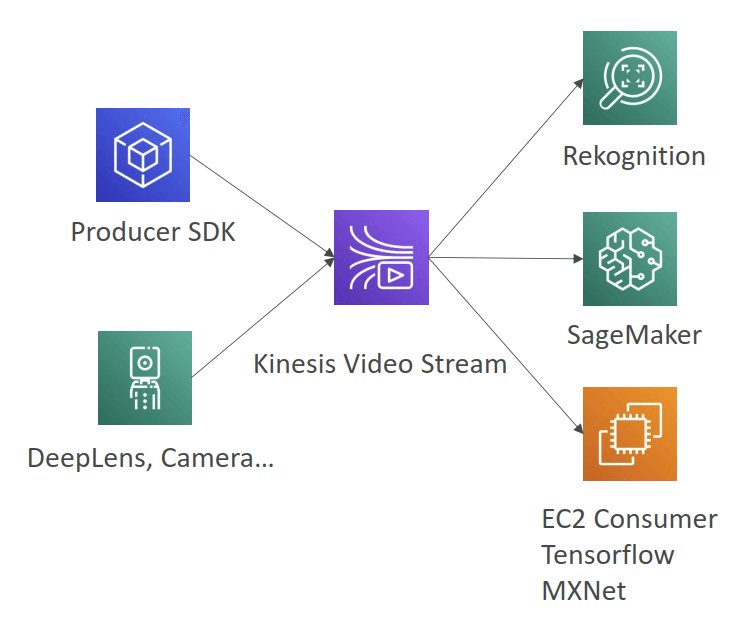
Kinesis Video Stream
- Video playback capability
- Keep data for 1 hour to 10 years
- [ML] real-time video stream to create ML applications
| Data Streams | Data Firehose | Data Analytics (Amazon Managed Service for Apache Flink) | Video Streams | |
| Short definition | Scalable and durable real-time data streaming service. | Capture, transform, and deliver streaming data into data lakes, data stores, and analytics services. | Transform and analyze streaming data in real time with Apache Flink. | Stream video from connected devices to AWS for analytics, machine learning, playback, and other processing. |
| Data sources | Any data source (servers, mobile devices, IoT devices, etc) that can call the Kinesis API to send data. | Any data source (servers, mobile devices, IoT devices, etc) that can call the Kinesis API to send data. | Amazon MSK, Amazon Kinesis Data Streams, servers, mobile devices, IoT devices, etc. | Any streaming device that supports Kinesis Video Streams SDK. |
| Data consumers | Kinesis Data Analytics, Amazon EMR, Amazon EC2, AWS Lambda | Amazon S3, Amazon Redshift, Amazon Elasticsearch Service, generic HTTP endpoints, Datadog, New Relic, MongoDB, and Splunk | Analysis results can be sent to another Kinesis stream, a Firehose stream, or a Lambda function | Amazon Rekognition, Amazon SageMaker, MxNet, TensorFlow, HLS-based media playback, custom media processing application |
| Use cases | – Log and event data collection – Real-time analytics – Mobile data capture – Gaming data feed | – IoT Analytics – Clickstream Analytics – Log Analytics – Security monitoring | – Streaming ETL – Real-time analytics – Stateful event processing | – Smart technologies – Video-related AI/ML – Video processing |
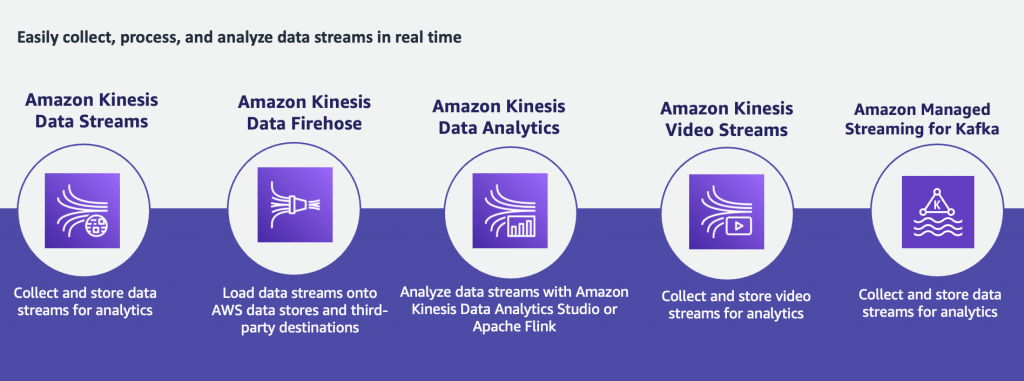
Ordering data into Kinesis
- Imagine you have 100 trucks (truck_1, truck_2, … truck_100) on the road sending their GPS positions regularly into AWS.
- You want to consume the data in order for each truck, so that you can track their movement accurately.
- How should you send that data into Kinesis?
- Answer: send using a “Partition Key” value of the “truck_id”
- The same key will always go to the same shard
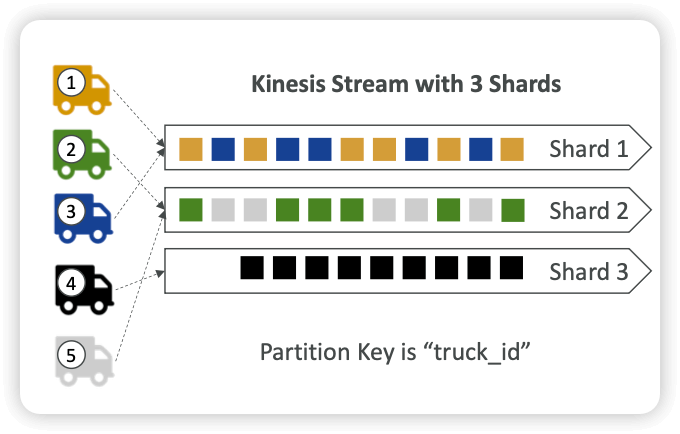
Ordering data into SQS
- For SQS standard, there is no ordering.
- For SQS FIFO, if you don’t use a Group ID, messages are consumed in the order they are sent, with only one consumer
- You want to scale the number of consumers, but you want messages to be “grouped” when they are related to each other
- Then you use a Group ID (similar to Partition Key in Kinesis)

Kinesis vs SQS ordering
- Let’s assume 100 trucks, 5 kinesis shards, 1 SQS FIFO
- Kinesis Data Streams:
- On average you’ll have 20 trucks per shard
- Trucks will have their data ordered within each shard
- The maximum amount of consumers in parallel we can have is 5
- Can receive up to 5 MB/s of data
- SQS FIFO
- You only have one SQS FIFO queue
- You will have 100 Group ID
- You can have up to 100 Consumers (due to the 100 Group ID)
- You have up to 300 messages per second (or 3000 if using batching)
=== CACHE ===
ElastiCache
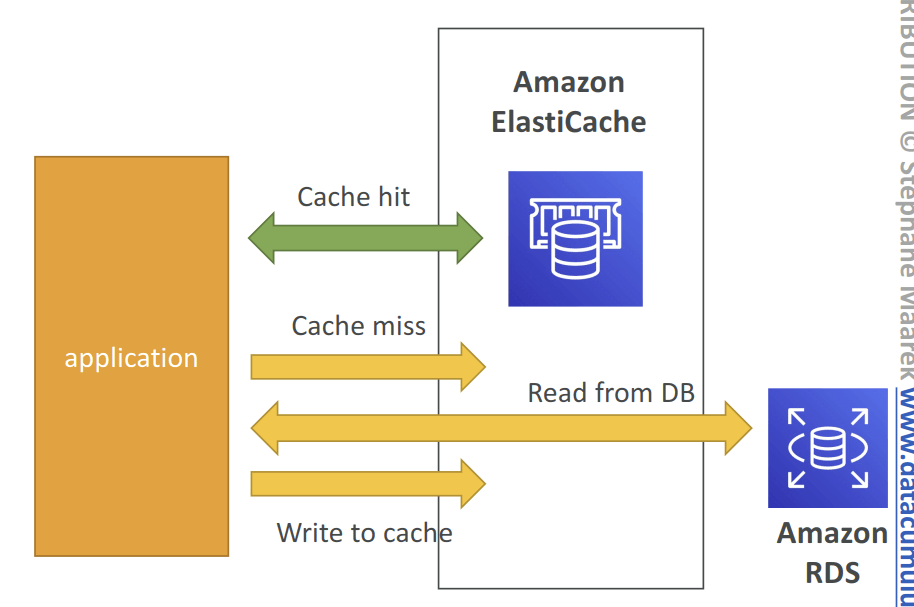
- Database cache. Put in front of DBs such as RDS or Redshift, or in front of certain types of DB data in S3, to improve performance
- reduce load off of databases for read intensive workloads
- make your application stateless
- Cache must have an invalidation strategy to make sure only the most current data is used in there.
- Using ElastiCache involves heavy application code changes
- As a cache, it is an in-memory key/value store database (more OLAP than OLTP)
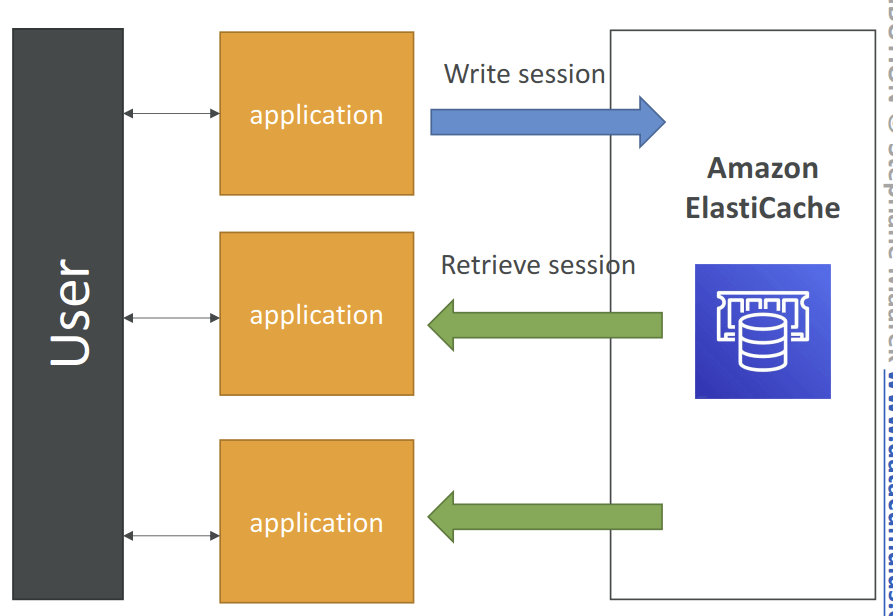
- Work as User Session Store
- User logs into any of the application
- The application writes the session data into ElastiCache
- The user hits another instance of our application
- The instance retrieves the data and the user is already logged in
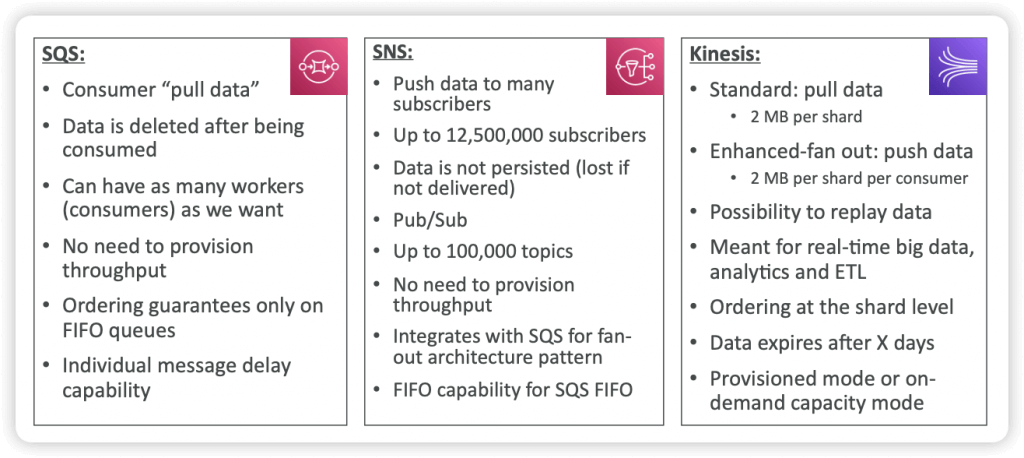
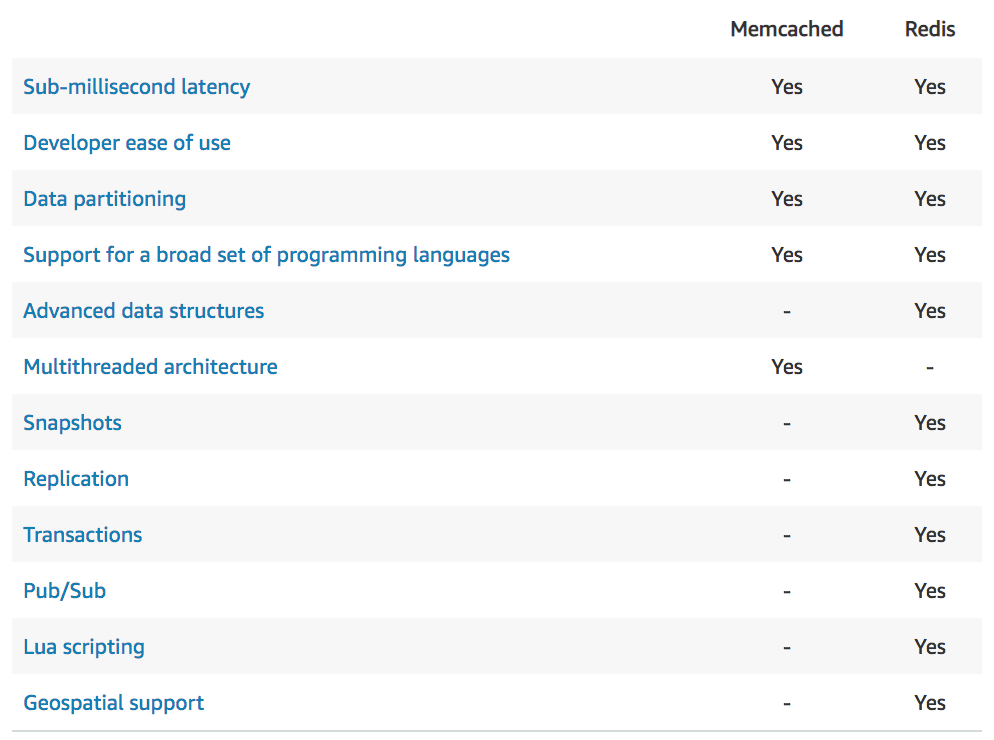
- Redis vs. Memcached
- Redis has replication and high availability, whereas Memcached does not. Memcached allows multi-core multi-thread however.
- Redis can be token-protected (i.e. require a password). Use the AUTH command when you create the Redis instance, and in all subsequent commands.
- For Redis, ElastiCache in-transit encryption is an optional feature to increase security of data in transit as it is being replicated (with performance trade-off)
- Valkey is the open-source version of Redis
- Use case: accelerate autocomplete in a web page form
| Redis | Memcached |
|---|---|
| Replication | Sharding |
| Multi AZ with Auto-Failover | Multi-node for partitioning of data (sharding) |
| Read Replicas to scale reads and have high availability | No high availability (replication) |
| Data Durability using AOF persistence | Non persistent |
| Backup and restore features | Backup and restore (Serverless) |
| Supports Sets and Sorted Sets | Multi-threaded architecture |
- for Valkey/Redis OSS
- Standalone node (without any replicas)
- One endpoint for read and write operations
- Cluster mode enabled (CME)
- works as a distributed database with multiple shards and nodes
- Data is partitioned across shards (helpful to scale writes)
- Each shard has a primary and up to 5 replica nodes (same concept as before)
- Multi-AZ capability
- Up to 500 nodes per cluster
- Auto Scaling
- Automatically increase/decrease the desired shards or replicas
- Supports both Target Tracking and Scheduled Scaling Policies
- Works only for Redis with Cluster Mode Enabled
- Recommended: update apps to use the Cluster’s Configuration Endpoint
- Configuration Endpoint – for all read/write operations that support Cluster Mode Enabled commands
- Node Endpoint – for read operations
- Cluster mode disabled (CMD)
- Valkey and Redis OSS work as a single node, with replicas
- Primary Endpoint – for all write operations
- Reader Endpoint – evenly split read operations across all read replicas
- Node Endpoint – for read operations
- Replication
- One primary node, up to 5 replicas
- Asynchronous Replication
- The primary node is used for read/write, the other nodes are read-only
- One shard, all nodes have all the data
- Guard against data loss if node failure
- Multi-AZ enabled by default for failover
- Helpful to scale read performance
- Scaling
- Horizontal (add more shards)
- Scale out/in by adding/removing read replicas (max. 5 replicas)
- Vertical (expand/change shards)
- Scale up/down to larger/smaller node type
- ElastiCache will internally create a new node group, then data replication and DNS update
- Horizontal (add more shards)
- Standalone node (without any replicas)
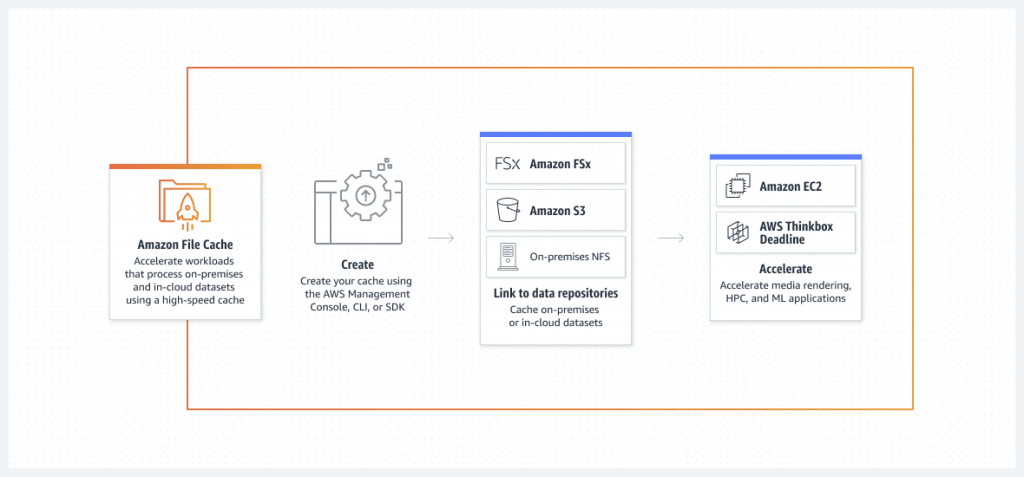
Amazon File Cache
- provides a high-speed cache on AWS that makes it easier to process file data, regardless of where it’s stored
- used to cache frequently accessed data
Caching design patterns
- Lazy caching / Lazy population / Cache-aside
- Laziness should serve as the foundation of any good caching strategy. The basic idea is to populate the cache only when an object is actually requested by the application. The overall application flow goes like this:
- Your app receives a query for data, for example the top 10 most recent news stories.
- Your app checks the cache to see if the object is in cache.
- If so (a cache hit), the cached object is returned, and the call flow ends.
- If not (a cache miss), then the database is queried for the object. The cache is populated, and the object is returned.
- Pros
- Only requested data is cached (the cache isn’t filled up with unused data)
- Node failures are not fatal (just increased latency to warm the cache)
- Cons
- Cache miss penalty that results in 3 round trips, noticeable delay for that request
- Stale data: data can be updated in the database and outdated in the cache
- Laziness should serve as the foundation of any good caching strategy. The basic idea is to populate the cache only when an object is actually requested by the application. The overall application flow goes like this:
- Write-through
- In a write-through cache, the cache is updated in real time when the database is updated. So, if a user updates his or her profile, the updated profile is also pushed into the cache. You can think of this as being proactive to avoid unnecessary cache misses, in the case that you have data that you absolutely know is going to be accessed. A good example is any type of aggregate, such as a top 100 game leaderboard, or the top 10 most popular news stories, or even recommendations. Because this data is typically updated by a specific piece of application or background job code, it’s straightforward to update the cache as well.
- Pros:
- Data in cache is never stale, reads are quick
- Write penalty vs Read penalty (each write requires 2 calls)
- Cons:
- Missing Data until it is added / updated in the DB. Mitigation is to implement Lazy Loading strategy as well
- Cache churn – a lot of the data will never be read
- Time-to-live
- Cache expiration can get really complex really quickly. In our previous examples, we were only operating on a single user record. In a real app, a given page or screen often caches a whole bunch of different stuff at once—profile data, top news stories, recommendations, comments, and so forth, all of which are being updated by different methods.
- Evictions
- Evictions occur when memory is over filled or greater than max memory setting in the cache, resulting into the engine to select keys to evict in order to manage its memory. The keys that are chosen are based on the eviction policy that is selected.
- You delete the item explicitly in the cache
- Item is evicted because the memory is full and it’s not recently used (LRU)
- You set an item time-to-live (or TTL)
- Evictions occur when memory is over filled or greater than max memory setting in the cache, resulting into the engine to select keys to evict in order to manage its memory. The keys that are chosen are based on the eviction policy that is selected.
- The thundering herd
- Also known as dog piling, the thundering herd effect is what happens when many different application processes simultaneously request a cache key, get a cache miss, and then each hits the same database query in parallel. The more expensive this query is, the bigger impact it has on the database. If the query involved is a top 10 query that requires ranking a large dataset, the impact can be a significant hit.
=== MIGRATION ===
AWS DataSync
- on-premises -> AWS storage services
- A DataSync Agent is deployed as a VM and connects to your internal storage (NFS, SMB, HDFS)
- Encryption and data validation
AWS Snowball
- a data transfer service designed for moving large amounts of data into and out of AWS using physical storage devices
- ideal in situations where there is limited or no internet connectivity, or where network bandwidth is insufficient for large data transfers.
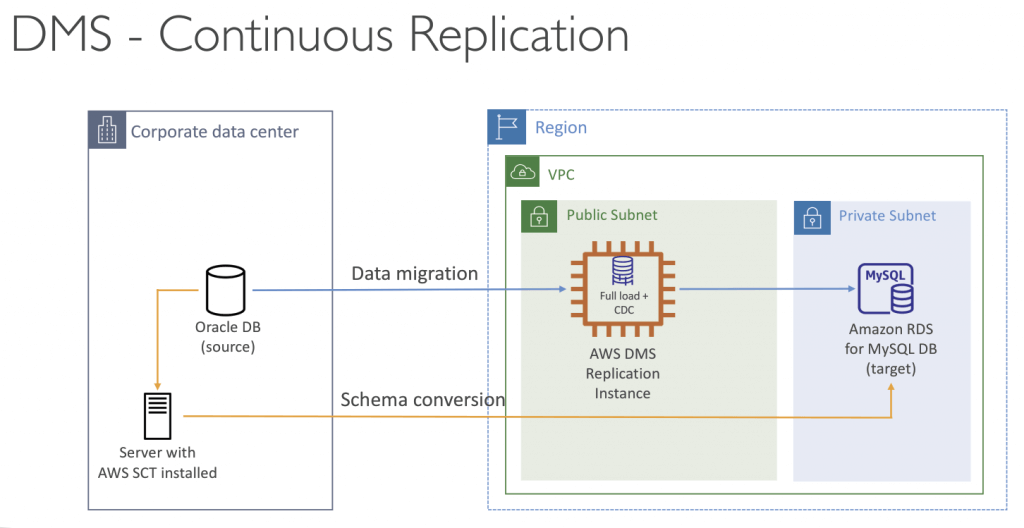
AWS Database Migration Service (AWS DMS)
- a managed migration and replication service
- The source database remains available during the migration
- must create an EC2 instance to perform the replication tasks
- Supports
- Homogeneous migrations: ex Oracle to Oracle
- Heterogeneous migrations: ex Microsoft SQL Server to Aurora
- primarily better suited for one-time migrations, ensuring consistency during the transition
- But also supports real-time data replication (or called as Continuous Data Replication) using change data capture (CDC) from source to target
- Continuous synchronization can introduce latency and potential data consistency issues
- Multi-AZ Deployment
- When Multi-AZ Enabled, DMS provisions and maintains a synchronously stand replica in a
different AZ - Advantages:
- Provides Data Redundancy
- Eliminates I/O freezes
- Minimizes latency spikes
- When Multi-AZ Enabled, DMS provisions and maintains a synchronously stand replica in a
- Replication Task Monitoring
- Task Status
- Indicates the condition of the Task (e.g., Creating, Running, Stopped…)
- Task Status Bar – gives an estimation of the Task’s progress
- Table State
- Includes the current state of the tables (e.g., Before load, Table completed…)
- Number of inserts, deletions, and updates for each table
- Task Status
- CloudWatch Metrics
- Host Metrics
- Performance and utilization statistics for the replication host
- CPUUtilization, FreeableMemory, FreeStorageSpace, WriteIOPS…
- Replication Task Metrics
- Statistics for Replication Task including incoming and committed changes, latency between the Replication Host and both source and target databases
- FullLoadThroughputRowsSource, FullLoadThroughputRowsTarget, CDCThroughputRowsSource, CDCThroughputRowsTarget…
- Table Metrics
- Statistics for tables that are in the process of being migrated, including the number of insert, update, delete, and DDL statements completed
- Host Metrics
| Source | Target |
|---|---|
| On-Premises and EC2 instances databases: Oracle, MS SQL Server, MySQL, MariaDB, PostgreSQL, MongoDB, SAP, DB2 | On-Premises and EC2 instances databases: Oracle, MS SQL Server, MySQL, MariaDB, PostgreSQL, SAP |
| Azure: Azure SQL Database | |
| Amazon RDS: all including Aurora | Amazon RDS |
| Amazon S3 | Redshift, DynamoDB, S3 |
| DocumentDB | DocumentDB & Amazon Neptune |
| OpenSearch Service | |
| Kinesis Data Streams | |
| Apache Kafka | |
| Redis & Babelfish |
Copying and Converting
- Use AWS Schema Conversion Tool (SCT) to convert a DB schema from one type of DB to another, e.g. from Oracle to Redshift
- Use Database Migration Service (DMS) to copy database. Sometimes you do SCT convert, then DMS copy.
- Use AWS DataSync to copy large amount of data from on-prem to S3, EFS, FSx, NFS shares, SMB shares, AWS Snowcone (via Direct Connect). For copying data, not databases.
AWS Schema Conversion Tool (SCT)
- Convert your Database’s Schema from one engine to another
- Example OLTP: (SQL Server or Oracle) to MySQL, PostgreSQL, Aurora
- Example OLAP: (Teradata or Oracle) to Amazon Redshift
- Prefer compute-intensive instances to optimize data conversions
- You do not need to use SCT if you are migrating the same DB engine
- Ex: On-Premise PostgreSQL => RDS PostgreSQL
- The DB engine is still PostgreSQL (RDS is the platform)
| Feature | OLTP | OLAP |
|---|---|---|
| Focus | Transactions | Analysis |
| Data Volume | Small, current data | Large, historical data |
| Query Complexity | Simple, frequent | Complex, less frequent |
| Response Time | Fast (milliseconds) | Slower (seconds or minutes) |
| Data Model | Normalized | Star or Snowflake schema |
| Typical Users | Frontline workers, customers | Analysts, managers |
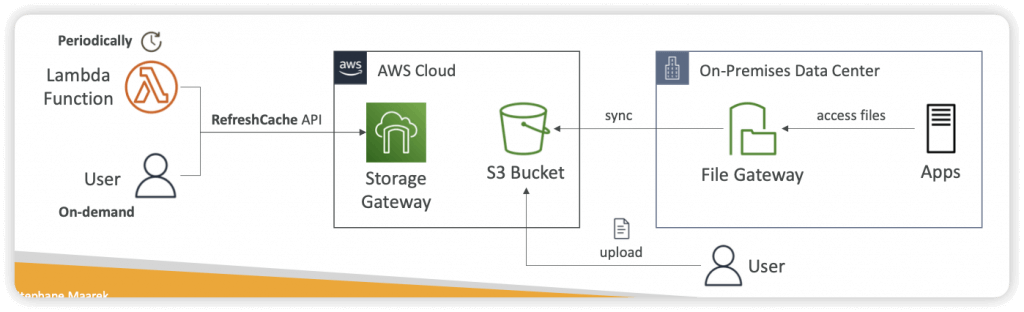
AWS Storage Gateway
- Hybrid Cloud for Storage
- Connect on-premises environments to AWS storage services; replace on-premises without changing workflow
- Hybrid storage service to allow on-premises to seamlessly use the AWS Cloud
- primary use case is for data backup, archiving, and hybrid cloud storage scenarios
- Types:
- File Gateway (for NFS and SMB)
- Storage Gateway updates the File Share Cache automatically when you write files to the File Gateway
- When you upload files directly to the S3 bucket, users connected to the File Gateway may not see the files on the File Share (accessing stale data)
- You need to invoke the RefreshCache API
- Automated Cache Refresh
- a File Gateway feature that enables you to automatically refresh File Gateway cache to stay up to date with the changes in their S3 buckets
- Ensure that users are not accessing stale data on their file shares
- No need to manually and periodically invoke the RefreshCache API
- Although the on-premises data center is using a tape gateway, you can still set up a solution to use a file gateway in order to properly process the videos using Amazon Rekognition
- Volume Gateway
- Tape Gateway
- With a tape gateway, you can cost-effectively and durably archive backup data in GLACIER or DEEP_ARCHIVE.
- A tape gateway provides a virtual tape infrastructure that scales seamlessly with your business needs and eliminates the operational burden of provisioning, scaling, and maintaining a physical tape infrastructure.
- the tape gateway in AWS Storage Gateway service is primarily used as an archive solution
- File Gateway (for NFS and SMB)
- Stores data in S3 (e.g. for file gateway type, it stores files as objects in S3)
- Provides a cache that can be accessed at low latency, whereas EFS and EBS do not have a cache
Amazon Redshift
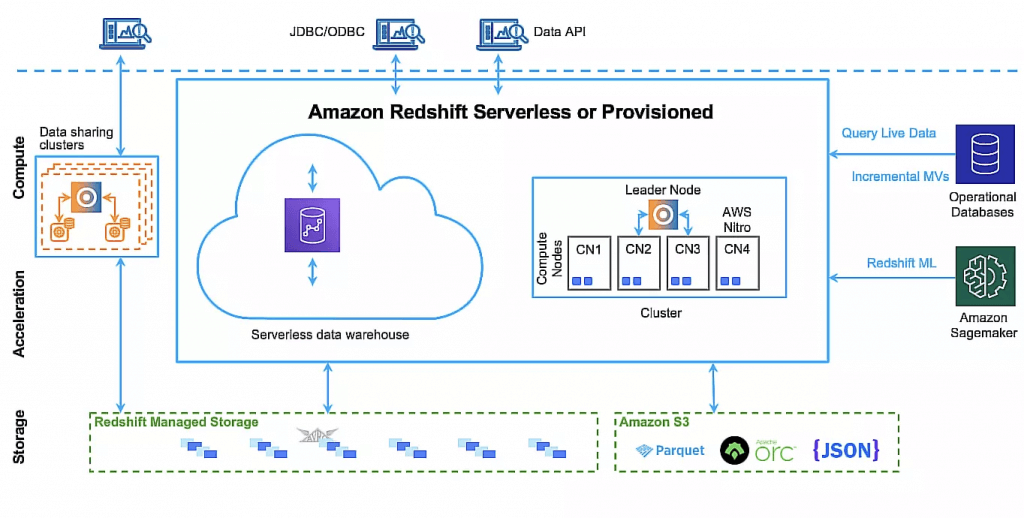
- a fast, fully managed, petabyte-scale data warehouse service that makes it simple and cost-effective to efficiently analyze all your data
- uses Massively Parallel Processing (MPP) technology to process massive volumes of data at lightning speeds
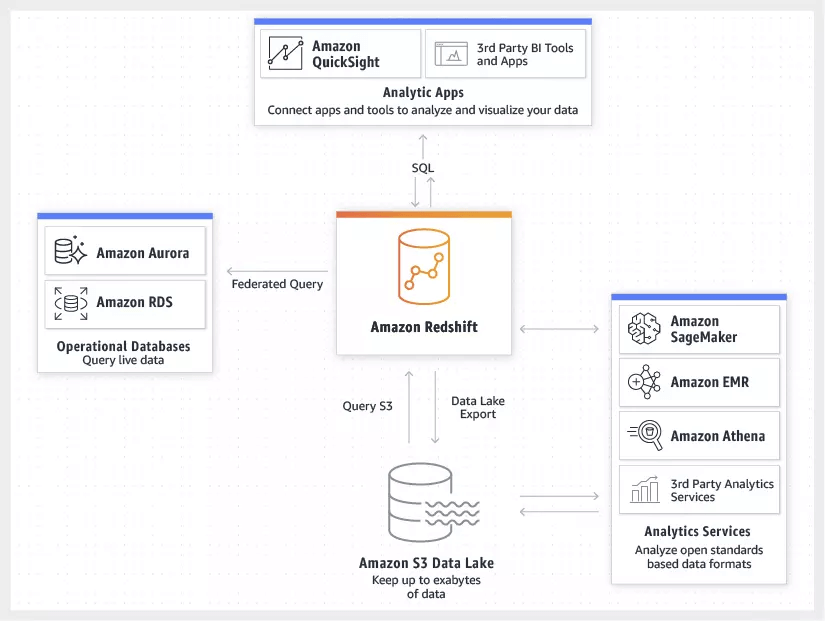
Analytics (OLAP)
- Redshift is a columnar data warehouse that you can use for complex querying across petabytes of structured data. It’s not serverless, it uses EC2 instances that must be running. Use Amazon RedShift Spectrum to query data from S3 using a RedShift cluster for massive parallelism
- Athena is a serverless (aka inexpensive) solution to do SQL queries on S3 data and write results back. Works natively with client-side and server-side encryption. Not the same as QuickSight which is just a BI dashboard.
- Amazon S3 Select – analyze and process large amounts of data faster with SQL, without moving it to a data warehouse