Following the progress recorded in my earlier post last November (https://blog.yannicklin.net/diary/2025/11/5813), where I outlined the initial structure of the project and several early-stage concerns, this month’s work focused on consolidating the system and resolving the issues that have accumulated since then. January has been about tightening the fundamentals — removing outdated components, correcting inconsistencies, and strengthening both code and documentation to support future development.
Below is a structured summary of the main updates applied throughout January 2026.
OpenCode Format Migration
The previously mentioned Gemini-based workflow has now been fully replaced with the OpenCode format. This shift addresses several of the limitations highlighted in the earlier post, particularly around predictability and maintenance overhead.
Key changes
Complete removal of Gemini-specific parsing logic
Unified and simplified ingestion and validation behaviour
Cleaned and updated record structure handling
Elimination of redundant or outdated sample files
Consistent naming and file-processing rules across modules
This transition provides a more stable base for upcoming features and aligns the internal workflow with the direction outlined last November.
Documentation Restructuring
In the previous post, I noted that documentation at the time was fragmented and partially experimental. This cycle focused on addressing exactly that problem.
Improvements
Rewrote several sections to eliminate conflicting explanations
Normalised formatting and structure across all documents
Removed partial drafts and legacy artifacts
Clarified what is implemented, what remains open, and what is intentionally out of scope
Performed consistency checks to ensure terminology does not drift
The documentation now reflects the actual state of the system, without speculative or leftover content.
UI, Responsiveness, and Behavioural Improvements
Some of the UI issues mentioned earlier — especially inconsistent rendering and mobile behaviour — were addressed in a dedicated cleanup effort.
Updates
Improved mobile responsiveness
Corrected layout inconsistencies
Streamlined template behaviour
Refined search logic for more predictable results
Updated Excel/PDF export functionality and removed outdated placeholder documents
These changes make the application feel more stable and predictable, regardless of device or workflow.
Code Cleanup and Minor Fixes
The accumulated debris of earlier development phases has now been cleared out.
Cleanup actions
Removed obsolete debugging comments
Eliminated unused or duplicated code blocks
Corrected a small lingering logic bug
Standardised comment style so explanations describe intent, not history
This cleanup helps maintain clarity and reduces friction for future development.
Development Environment Improvements
A notable upgrade this month was the addition of pre‑commit hooks, which enforce:
automatic linting,
code formatting,
and basic static security checks.
This directly addresses workflow issues I hinted at in the previous post, where consistency and code cleanliness were recurring concerns.
With this change, low‑quality or inconsistent commits are automatically blocked, improving the reliability of the codebase.
Ongoing Work
Current work continues in the areas of:
additional refinement of search behaviour,
validation logic improvements,
deeper integration of the OpenCode pipeline,
and incremental documentation corrections where necessary.
These updates extend the foundation built this month and will support the next functional steps of the project.
Notes on Spec‑Kits and Developer Tools
As mentioned previously, I have been working alongside AI‑assisted documentation tools. Recent observations reinforce earlier concerns:
unreliable work‑hour estimations,
unnecessary creation of supplementary documents,
inconsistent formatting between outputs,
internally contradictory messages,
corruption caused by partial updates,
and GitHub Copilot’s inability to perform proper research or maintain global consistency across documentation.
These limitations continue to highlight the gap between code-level assistance (where AI tools perform well) and specification‑level consistency (where significant manual intervention remains unavoidable).
Conclusion
Building on the direction outlined in my previous post, January 2026 delivered consistent and meaningful progress for flask-records-management. The system now has:
a unified data format (OpenCode),
cleaner and more accurate documentation,
improved UI behaviour,
better export reliability,
code cleanup across the board,
and pre‑commit hook enforcement for long‑term maintainability.
With these fundamentals in place, the next iterations can shift back toward feature expansion instead of infrastructure correction.
When I started this project, the idea sounded simple: build a web application to manage personal accounts and records. The data was already there—an Excel file with three worksheets: Generic, Systems, and Finance. This wasn’t random; it was intentional. I wanted the web app to treat these three sheets as separate tabs, each with its own logic and presentation. That was part of the design from day one.
I also had a principle in mind: combine vibe coding with Spec-Driven Development (SDD). Vibe coding is fast and creative—it lets you jump in and start building without overthinking. SDD, on the other hand, is structured and disciplined. It forces you to define specifications before writing code. Most developers pick one approach and stick with it. I wanted to see what happens when you mix them. Could I keep the flexibility of vibe coding while enjoying the clarity of specs? That was the experiment.
Choosing GitHub SPEC-Kit was deliberate. I didn’t have private access to AWS Kiro, which was one option for spec management. SPEC-Kit, on the other hand, is open-license and widely shared among communities as a solid starting point. That openness mattered to me—it felt like building on something trusted and collaborative. Plus, it aligned with my principle: start with specs, but don’t lose the creative flow.
The AI Experiment: Gemini vs Claude
Then came the twist: I decided to mix AI tools. On my private laptop, I had Gemini CLI, while my work laptop had GitHub Copilot with an enterprise license. I wanted to see how these two could work together—or if they even could. It turned out to be one of the most interesting parts of the journey.
Gemini and Claude felt like two very different personalities. Gemini 2.5 was like an old gentleman—slow, stubborn, and obsessed with correctness. It followed instructions religiously, always trying to update the spec before moving forward. If something wasn’t documented, Gemini would stop and insist on fixing the spec first. Claude 4, powering Copilot, was the opposite: quick, action-oriented, and well-organized. Claude wanted to get things done. Sometimes it respected the rule of “update the spec before coding,” but other times—maybe 50-50—it ignored the instructions and dove straight into implementation.
Watching them interact was fascinating. When Gemini looked at Claude’s work, it always tried to “correct” it, sticking strictly to the specs. Claude, meanwhile, prioritized completing tasks. Specs were evolving, and Gemini wanted everything perfect before moving on. Claude just wanted to ship features. Managing that tension felt like managing two developers with completely different work styles. It taught me something unexpected: AI tools aren’t just technical helpers—they have tendencies, almost like personalities. Understanding those tendencies can make collaboration smoother.
The Human Role in AI Development
Here’s where my added challenge comes in: it’s not an easy job for me to present as a not-so-experienced engineer with design skills, while acting like a project manager or product ideator. I had to guide AI without sounding overly technical, using language that was clear and actionable. Especially for UI changes, basic tech stack decisions, and security issues, I couldn’t just throw jargon at the AI and hope for the best.
This balancing act—between technical precision and accessible language—was harder than I expected. AI doesn’t “think” like us; it interprets patterns. If I said, “Make the UI more intuitive,” that was too vague. If I said, “Apply responsive design principles with Tailwind CSS and ensure accessibility compliance,” that was too rigid and sometimes misinterpreted. I had to find the sweet spot: simple, structured prompts that conveyed intent without overwhelming detail.
The Tech Stack and Deployment Vision
From the beginning, I wanted this app to feel modern and scalable. The stack I chose was Flask for the backend, Vue.js for the frontend, and Tailwind CSS for styling. Why this combination? Flask is lightweight and flexible, perfect for rapid prototyping. Vue.js gives me reactive components without the complexity of heavier frameworks. Tailwind CSS makes styling efficient and consistent.
The long-term vision is to deploy the app as a Docker container on Portainer, making it easy to manage and scale. That’s why I started thinking about containerization early—even though it added complexity to local development.
The Database Journey: From TinyDB to MontyDB
Here’s where things got messy. My initial choice for the database was TinyDB. It’s simple, lightweight, and great for quick setups. But then I realized something critical: TinyDB stores everything as clear text in JSON. For an app that manages personal records—including login credentials for multiple websites—that’s a huge security risk. I couldn’t ignore that.
So I switched to MongoDB, the most popular NoSQL database. It felt like the right move for scalability and security. But this switch wasn’t easy. MongoDB in my setup was pure Docker-based, which made local development and testing a burden. Setting up the environment, configuring containers, and ensuring connectivity took more than two full days. And even after that, the workflow felt heavy for a project that was still in its early stages.
Finally, I decided to switch again—this time to MontyDB, a lightweight fork of MongoDB designed for local development. It gave me the MongoDB-like API without the overhead of running full Docker containers. But even this switch wasn’t painless. Migrating data caused duplicates and corruption issues, and fixing them took another full day. These database transitions taught me a hard lesson: choosing the right tools early matters, but flexibility matters even more.
The App So Far: 50–60% Complete
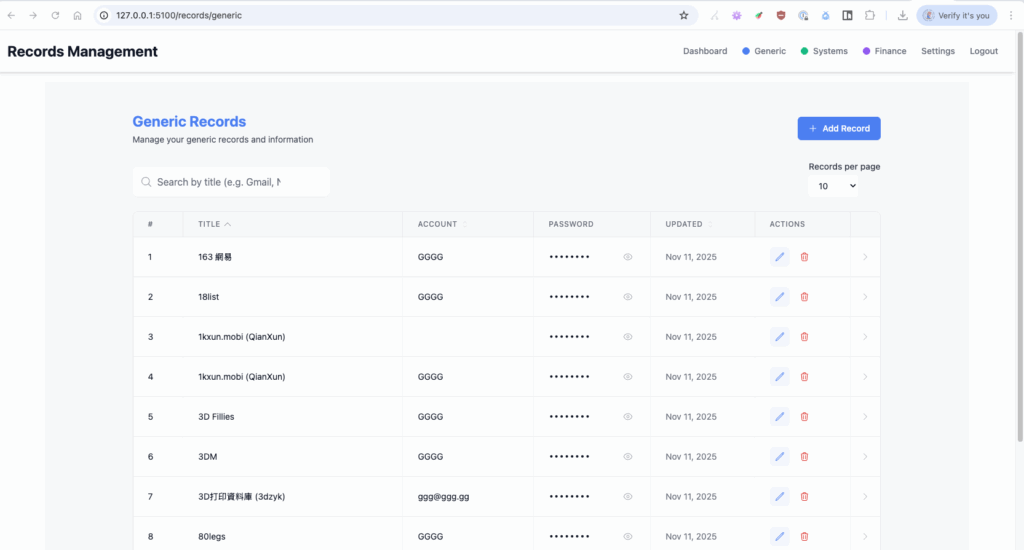
The app itself is still only about 50–60% complete, but it already has some core features in place. The first thing you see is a login screen with predefined account/email and password. After a successful login, the first screen is a dashboard. From there, you can navigate to the three main tabs: Generic, Systems, and Finance. Each tab presents its data in different columns but shares common fields like title, account, and password.
For usability, the password field has a toggle to show or hide the value, while other fields include a “copy to clipboard” tool. These small details matter because they make the app feel practical and user-friendly. Each category also supports search by title, and export functions to PDF or Excel. That was important to me—if you’re managing records, you need easy ways to share or back them up.
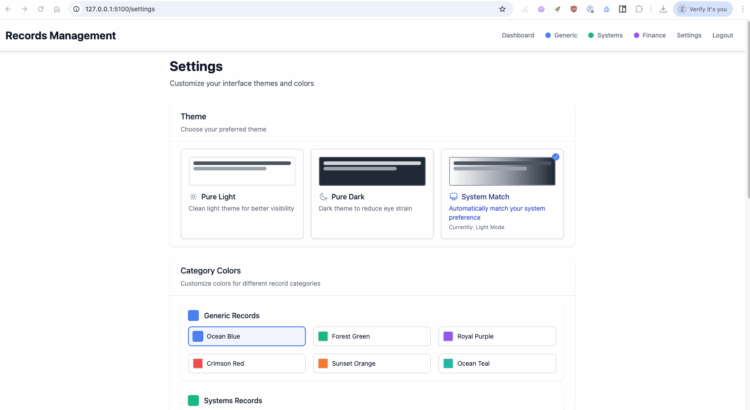
There’s also a Settings tab, which handles overall theme (dark, light, or system default), category color customization, and password reset/modify. These features might sound minor, but they add a layer of personalization that makes the app feel polished. I wanted users to feel like they could make the app their own.
The Hardest Part: PDF Generation and Non-English Text
One of the last major hurdles was PDF generation. It sounded simple at first—just export the records into a clean PDF format. But the reality was far from easy. Many of the records contained non-English characters, including CJK (Chinese, Japanese, Korean) text. When I tried to generate PDFs, the output was a mess: mojibake, question marks, or solid black boxes instead of readable text.
The root of the problem? Fonts. Embedding CJK fonts in PDFs is not straightforward. Many fonts you download aren’t “true” TTF (TrueType Font) files, and libraries like ReportLab have limitations when it comes to handling complex scripts and font embedding. Even when I thought I had the right font, the rendering failed because the font wasn’t fully compatible or lacked proper glyph support.
Explaining this issue to AI tools was another challenge. How do you tell an AI that the font rendering is wrong when it doesn’t “see” the output the way we do? I tried different libraries, custom font paths, and encoding tweaks, but it was a frustrating process. This part reminded me of something critical: AI accelerates development, but it doesn’t replace human judgment—especially for nuanced issues like multilingual text rendering and font embedding.
Additional Pain Points
There were other challenges that made this journey even more interesting:
Stability issues: Both AI models were prone to hanging. Gemini almost never ran stably for more than an hour without needing a terminal restart. Claude was better, but still had occasional freezes.
Memory loss and oversight: Claude’s tendency to forget context was not limited to rules in the instructions. Sometimes it even forgot or misled itself about the agent to-do list it had set minutes earlier. This meant I couldn’t simply “set and forget.” I had to continuously monitor and intervene, making sure its operations didn’t drift too far from the original scope. Without human oversight, the risk of over-designing or introducing unnecessary complexity was high.
Bug fixing reality: Drafting the application with AI was exciting—the speed and completeness were beyond expectations. But once I moved to bug fixes and UI enhancements, the story changed. With SDD in place, resolving issues became harder because the AI struggled to adapt to evolving specs without breaking something else.
Reflections on AI Collaboration
This project taught me something important about AI-human collaboration. AI tools are powerful, but they’re not magic. They need guidance. Gemini and Claude didn’t just follow my commands—they interpreted them, sometimes in ways I didn’t expect. Gemini stuck to the rules like a perfectionist. Claude bent the rules when it thought speed mattered more. Neither was wrong, but both needed context.
And here’s the human side: I had to act as a translator between ideas and implementation. Sometimes I felt like a designer, other times like a product manager, and occasionally like a security consultant. All while trying to keep my language simple enough for AI to understand. That’s not easy when you’re still growing as an engineer. But it’s necessary. Because AI doesn’t just need instructions—it needs clarity, intent, and sometimes empathy.
Mixing AI tools also showed me that diversity matters—even in software development. Gemini’s strictness kept me from cutting corners. Claude’s speed kept me from getting stuck in planning forever. Together, they balanced each other out. It wasn’t always smooth, but it was productive.
Why This Is Just the Beginning
The app isn’t finished yet, and that’s okay. It’s about 50–60% complete, and the next steps include refining the UI, adding more customization options, and improving export features. I also want to explore how AI can help with testing and optimization. Claude is great at generating code, but can it write meaningful tests? Gemini is good at specs, but can it help with performance tuning? These are questions I’m excited to answer.
Would I do it again? Absolutely. But next time, I’ll start with specs from day one—and maybe keep experimenting with AI personalities. Because building with clarity and a little help from two very different “assistants” turned out to be more interesting than I expected.
This isn’t the end of the story. It’s just a pause—a checkpoint before the next sprint. There’s more to build, more to learn, and more to share. And honestly? I can’t wait to see where this journey goes next.
In June 2025, I passed the AWS Certified Machine Learning – Specialty exam—my third AWS certification. Unlike the previous two (Solutions Architect – Associate and Developer – Associate), this one opened the door to a completely new domain: machine learning and applied data science on AWS.
The shift wasn’t just technical—it was conceptual. I went from managing infrastructure and deploying APIs to preparing datasets, evaluating model performance, and experimenting with SageMaker pipelines.
🧭 Why I Took the Leap into ML
While working through architectural and serverless designs, I often came across problems that felt deeply data-driven—fraud detection, user behavior prediction, personalization. I realized that cloud fluency alone wasn’t enough; I wanted to learn how to build intelligent systems with the power of ML.
The Machine Learning Specialty exam offered a structured path to build that capability.
⚙️ A Different Kind of Challenge
Compared to Associate-level exams, the ML Specialty dives deep into:
Core ML Concepts Supervised vs. unsupervised learning, classification vs. regression, feature engineering, model tuning, and overfitting detection.
Model Evaluation Understanding metrics like precision, recall, F1 score, ROC AUC, confusion matrices—and when to use which.
End-to-End ML Pipelines Data collection → processing → training → deployment → monitoring—using services like S3, Glue, SageMaker, CloudWatch, and Model Monitor.
Bias, Explainability, and Governance Using SageMaker Clarify and managing fairness, transparency, and responsible AI design.
📚 Learning Notes
Rather than creating a separate section, I’ve continued adding to the existing AWS directory.
Some of the notes now live under:
📘 Data Prepration Cleaning, transforming, and splitting datasets using Pandas, SageMaker Processing, and AWS Glue.
📘 DataModel Training Covers training models in SageMaker (built-in + custom), using Estimators, handling imbalanced datasets, and hyperparameter tuning.
📘 Modelling Evaluation Detailed walkthroughs of evaluation metrics, model selection strategies, and overfitting/underfitting signals.
📘 Machine Learning Implementation Endpoints, autoscaling, versioning, and deploying models with real-time inference + A/B testing.
📘 Machine Learning Governance Bias detection, explainability, and model monitoring using Clarify and Model Monitor.
🔍 Study Strategy & Tools
This cert took a different kind of discipline:
Hands-on Jupyter Labs in SageMaker I used real datasets (from UCI, Kaggle) to train XGBoost, Linear Learner, and NLP models with BlazingText.
Model Lifecycle Practice Practiced full ML lifecycles: data → processing → model training → endpoint deployment → monitoring.
Lots of Theory Repetition Concepts like recall vs. precision or when to use PCA required more time and real examples to solidify.
ML-Focused Mock Exams Focused on real-world case studies and use-case reasoning—not just configurations.
🧠 Key Takeaway
This was the most conceptually intense of all three certifications I’ve taken so far. While the Associate-level exams were about knowing how AWS works, this one required understanding why certain ML methods apply in specific scenarios.
And most importantly—it made me more confident as I take my first serious steps into the data science world.
🙌 Final Thoughts
Three certifications in—each one pushed me in a new direction. And the Machine Learning – Specialty was a powerful reminder that learning doesn’t stop at architecture or automation. If you’re cloud-native but curious about ML, or a developer looking to bridge into data science, I hope these notes and reflections help make that path less intimidating.
In early March 2025, I earned my second AWS certification: the AWS Certified Developer – Associate. This built on the foundation I laid with the Solutions Architect – Associate, but with a much deeper dive into serverless development, event-driven design, and developer tooling on AWS.
Instead of creating a new section, I’ve continued updating and expanding the existing AWS knowledge collection with Developer-specific topics, keeping everything in one place for a cohesive learning path.
🔥 Focus: Serverless, APIs, and Automation
This certification emphasized building, securing, and deploying cloud-native applications—especially using AWS’s serverless offerings. I focused my preparation on:
AWS Lambda Building scalable, efficient functions with environment configs, permissions, and concurrency controls.
API Gateway Integrating REST and WebSocket APIs with Lambda, adding request transformations, and securing endpoints with JWT-based custom authorizers.
EventBridge & SQS/SNS Designing event-driven applications using EventBridge rules, SQS queues, DLQs, and SNS topics to decouple and scale workflows.
CI/CD Automation Automating deployments with CodePipeline, CodeBuild, and SAM templates—integrated with Git-based workflows.
Observability & Debugging Using CloudWatch Logs, metrics, alarms, and X-Ray to trace Lambda executions, API behavior, and message flow through event pipelines.
📝 Developer Topics Now in AWS
I’ve integrated all new Developer Associate–relevant material directly into the existing AWS notes section, including updates to:
Serverless Expanded to include advanced Lambda patterns, handler design tips, concurrency tuning, and architectural diagrams.
DevTools New content added covering CodePipeline, CodeBuild setups for serverless projects, and how to define full workflows using SAM CLI.
Database Storage Now includes DynamoDB tips relevant for developers—indexes, partition key planning, TTL, and DynamoDB Streams with Lambda triggers.
Security and Compliance More examples of IAM roles for Lambda, scoped permissions for developer workflows, and secure access patterns for Parameter Store & Secrets Manager.
🙌 Final Thoughts
The Developer Associate certification challenged me in new ways—from writing code to managing real-world deployments. It’s more than theory—it’s how AWS apps are actually built. If you’re studying or just exploring serverless, feel free to explore my updated AWS section, or reach out with questions or feedback.
Last December, I finally earned the AWS Certified Solutions Architect – Associate certification. It wasn’t a simple weekend prep session—it was the culmination of months of dedication: early mornings before work, late nights after dinner, and countless hours of hands-on practice across real-world scenarios.
To capture every milestone and make review easier, I documented my learning journey with a well-structured set of knowledge notes—hosted on my AWS section. Here’s a deep dive into that journey.
📚 Core Topics & My Note Collections
These posts served as the backbone of my study plan—check them out for summaries, diagrams, code snippets, and exam-style flashcards:
CloudFormation & Architecture Patterns Modular stack design, nested stacks, parameter input strategies, and template best practices. I included sample templates to showcase blue/green deployments, cross-stack references, and rollback behaviors.
Networking & VPC Subnet types, route tables, NAT gateways, VPC endpoints, cross‑account and cross‑region networking. I experimented with transit gateways and published flow diagrams for clarity.
Security & Compliance IAM roles, policies, fine‑grained permissions, STS, KMS, and service‑linked roles. I also covered AWS Config rules and CloudTrail integration—foundational for both exam success and real-world security.
Serverless Architecture (Lambda, EventBridge, CloudWatch) From writing Lambda functions to architecting event‑driven workflows with EventBridge and designing resilient retry patterns with dead‑letter queues. I shared CLI recipes and monitoring hacks.
Data & Storage Options S3, EBS, RDS, DynamoDB — lifecycle policies, provisioned capacities, encryption, and backup strategies. Got hands-on with lifecycle transitions and RDS read replicas.
🔍 How My Notes Transformed the Study Experience
Active Learning Through Writing Turning course material and documentation into blog‑style notes pushed me from passive reading to active recall.
Modular Review System Each topic living on its own page helped me target weak areas and do quick refreshers before mock exams.
Hands-On Templates & Diagrams The reusable CloudFormation snippets and network visuals were invaluable—both in the exam simulation and in post-cert projects.
🙌 Final Thought
Embarking on the AWS certification path was challenging—but creating this knowledge base made it rewarding, repeatable, and shareable. If you’re preparing for the AWS Certified Solutions Architect path, I hope my notes give you a headstart. Interested in walkthroughs on specific modules? Just drop a comment below!