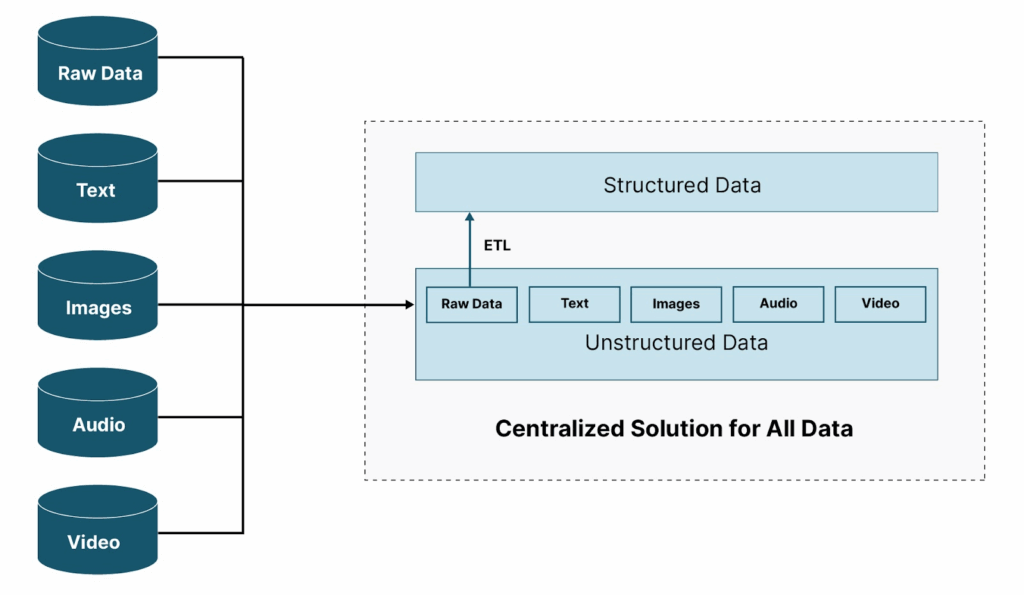
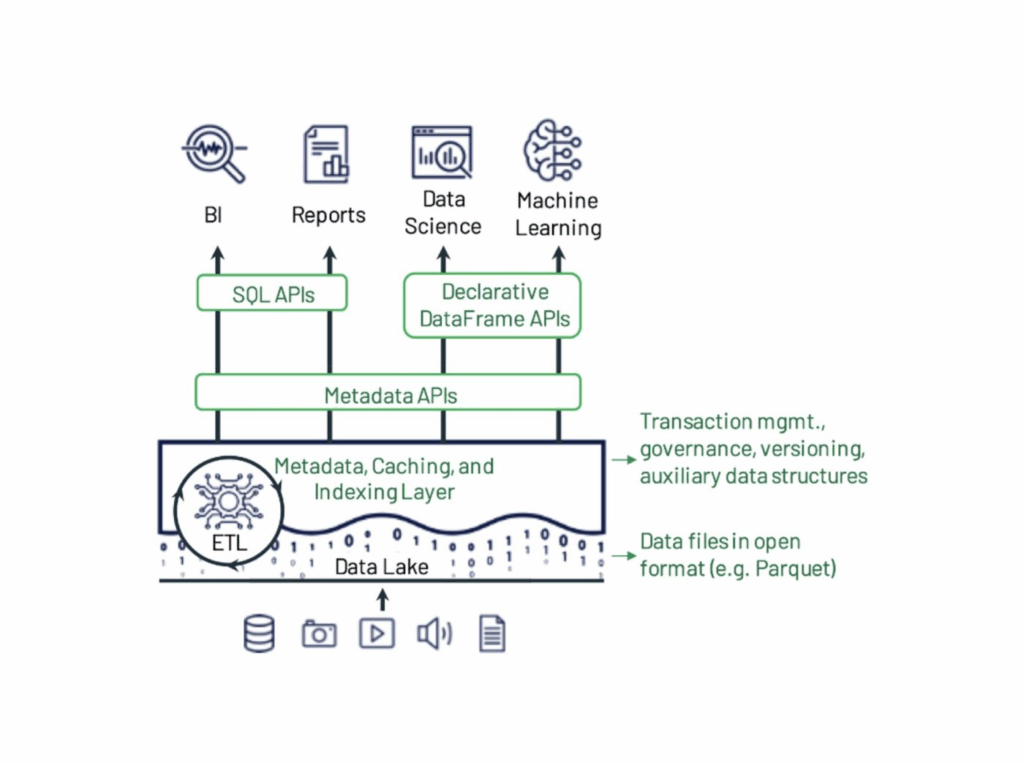
Unity Catalog
Delta Sharing
(Apache) Iceberg
- Iceberg aimed to bring database-like reliability, consistency, and manageability to data lakes built on open file formats like Parquet, Avro, or ORC.
- Think of Iceberg as a modern table format that sits on top of your files and manages them like a relational database would—with support for versioning, transactions, and intelligent metadata management.
- True Schema Evolution (Without File Rewrites): Iceberg stores schema information in its own metadata layer
- Full ACID Transactions at Scale: Iceberg supports serializable isolation through snapshot-based transactional writes
- Time Travel and Snapshot Isolation: Every write in Iceberg creates a new snapshot, recorded in the metadata.
- Partitioning Without Pain
| Feature | Apache Parquet (Columnar Storage Format) | Apache Iceberg (Table Format) |
|---|---|---|
| Storage Format | Stores data in a highly efficient, columnar, binary format. | Organizes Parquet/ORC/Avro files into structured tables using rich metadata. |
| Schema Evolution | Limited: adding columns is easy, but renaming/reordering requires rewriting files. | Fully supports add/drop/rename/reorder, without rewriting underlying files. |
| ACID Transactions | Not supported. Updates/deletes require rewriting files manually. | Full transactional support with isolation and atomicity across operations. |
| Time Travel | Not natively supported. Manual versioning needed. | Built-in snapshot-based versioning for point-in-time queries and rollback. |
| Performance | Optimized for scan-heavy, read-mostly workloads. | Optimized for dynamic datasets with concurrent writes, updates, and schema changes. |
| Best For | Analytical queries, static datasets, feature stores. | Data lakes, CDC pipelines, evolving schemas, and transactional workloads. |
Parquet
- an open columnar data type that is common in big data environments and great for automated workflows and storage. If your team uses Hadoop then this is most likely their favorite format. Parquet is self-describing in that it includes metadata that includes the schema and structure of the file.
- Good on
- Read Speed
- File Size, with compression and encoding
- Splittable
- Included Data Types
- Schema Evolution – support to adding or dropping fields
- Bad on
- Not Human-readable
- Write Overhead and Latency
- Inefficient on row-lv access
- Tooling overhead
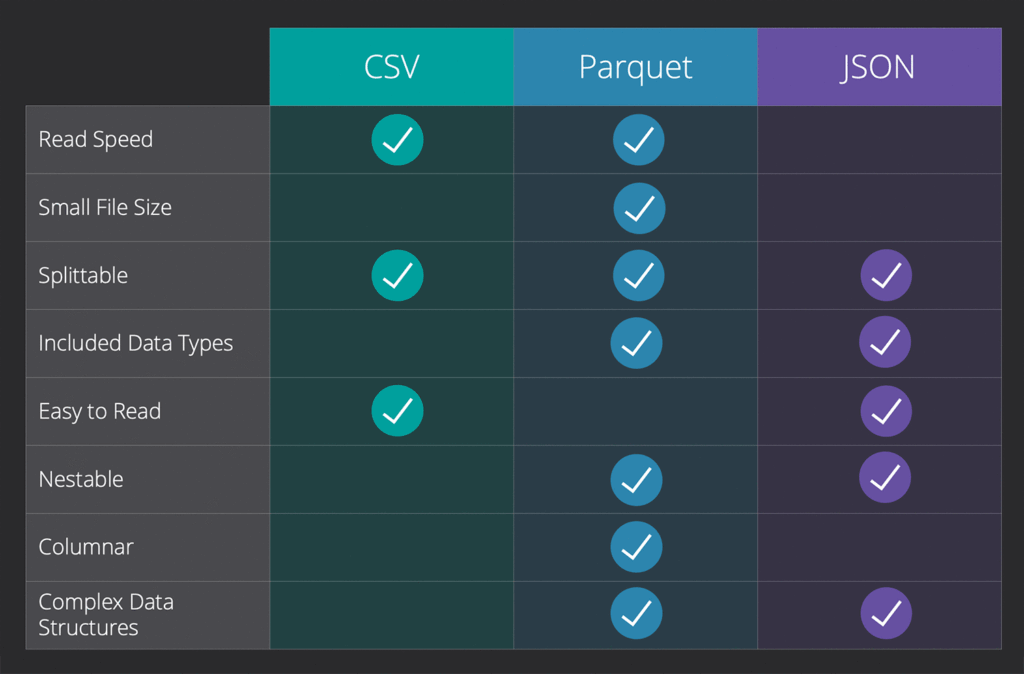
| Feature | Parquet | CSV | JSON | Avro | ORC |
| Storage Type | Columnar | Row-based | Row-based | Row-based | Columnar |
| Compression | High (Snappy, Gzip, Brotli) | None (manual) | Moderate (manual) | Moderate (Deflate) | Very High (Zlib, LZO) |
| Read Performance | Excellent (esp. for selective columns) | Poor | Poor | Moderate | Excellent |
| Write Performance | Moderate to Slow (due to encoding) | Fast | Fast | Fast | Moderate |
| Schema Support | Strong (with evolution) | None | Weak (schema-less) | Strong (with evolution) | Strong (with evolution) |
| Nested Data Support | Excellent (via Arrow) | None | Good (but inefficient) | Moderate | Excellent |
| Human Readable | No | Yes | Yes | No | No |
| Best Use Cases | Analytics, Data Lakes, BI Tools | Quick Inspection, Debugging | Logging, Config Files | Streaming, Serialization | Data Warehousing (esp. Hive) |
| Cloud Compatibility | Universal (AWS, Azure, GCP) | Universal | Universal | Universal | Mostly Hadoop Ecosystems |
Delta Lake
- Delta Lake builds a metadata layer on top of existing data files, which are typically in the Parquet format.
- This metadata layer, or transaction log, records all changes to the table.
- The transaction log allows Delta Lake to perform ACID transactions and track data versions, which is the foundation for features like time travel and schema enforcement.
- It is fully compatible with Apache Spark APIs, allowing it to integrate easily into existing big data and streaming workflows.
- Lakehouse: https://www.cidrdb.org/cidr2021/papers/cidr2021_paper17.pdf
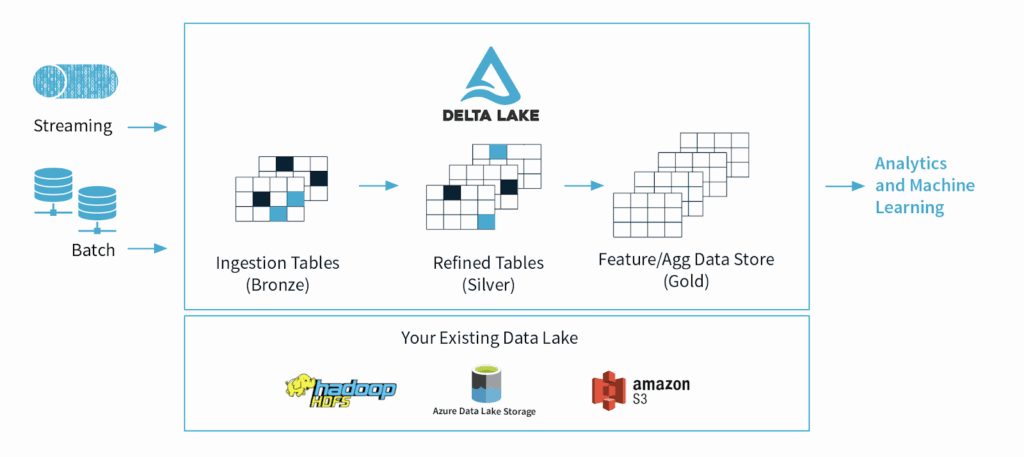
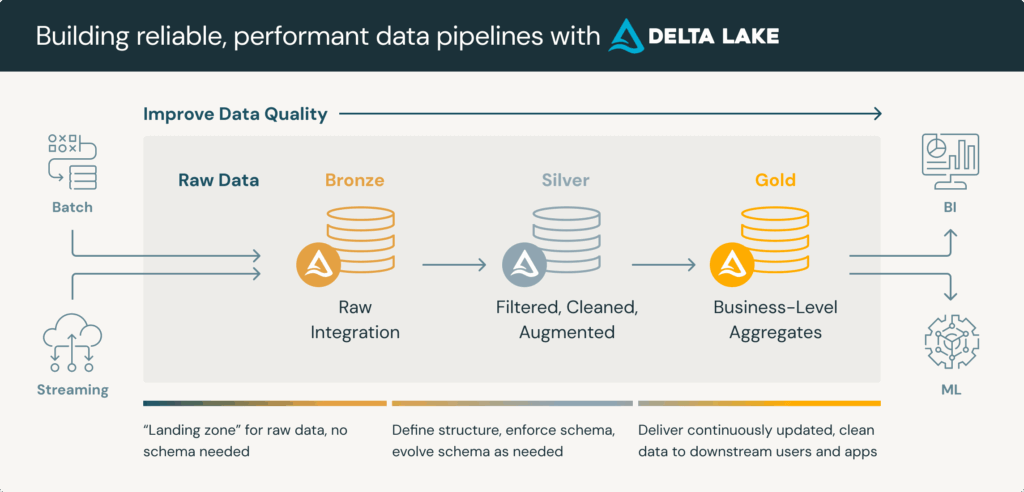
Medallion Architecture
- A medallion architecture is a data design pattern used to logically organize data in a lakehouse, with the goal of incrementally and progressively improving the structure and quality of data as it flows through each layer of the architecture (from Bronze ⇒ Silver ⇒ Gold layer tables). Medallion architectures are sometimes also referred to as “multi-hop” architectures.
- Data Quality Levels/Layers
- Bronze
- raw data
- and all the data from external source systems. The table structures in this layer correspond to the source system table structures “as-is,” along with any additional metadata columns that capture the load date/time, process ID, etc. The focus in this layer is quick Change Data Capture and the ability to provide an historical archive of source (cold storage), data lineage, auditability, reprocessing if needed without rereading the data from the source system.
- Silver
- cleansed and conformed data
- the data from the Bronze layer is matched, merged, conformed and cleansed (“just-enough”) so that the Silver layer can provide an “Enterprise view” of all its key business entities, concepts and transactions.
- Speed and agility to ingest and deliver the data in the data lake is prioritized, and a lot of project-specific complex transformations and business rules are applied while loading the data from the Silver to Gold layer.
- From a data modeling perspective, the Silver Layer has more 3rd-Normal Form like data models.
- Gold
- curated business-level tables
- for reporting and uses more de-normalized and read-optimized data models with fewer joins
TPC
- The TPC (Transaction Processing Performance Council) is a non-profit corporation focused on developing data-centric benchmark standards and disseminating objective, verifiable data to the industry.
- TPC-DI: Data Integration (DI), also known as ETL, is the analysis, combination, and transformation of data from a variety of sources and formats into a unified data model representation. Data Integration is a key element of data warehousing, application integration, and business analytics.
- TPC-DS is the de-facto industry standard benchmark for measuring the performance of decision support solutions including, but not limited to, Big Data systems. The current version is v2. It models several generally applicable aspects of a decision support system, including queries and data maintenance. Although the underlying business model of TPC-DS is a retail product supplier, the database schema, data population, queries, data maintenance model and implementation rules have been designed to be broadly representative of modern decision support systems. This benchmark illustrates decision support systems that:
- Examine large volumes of data
- Give answers to real-world business questions
- Execute queries of various operational requirements and complexities (e.g., ad-hoc, reporting, iterative OLAP, data mining)
- Are characterized by high CPU and IO load
- Are periodically synchronized with source OLTP databases through database maintenance functions
- Run on “Big Data” solutions, such as RDBMS as well as Hadoop/Spark based systems
- TPC-E: TPC Benchmark™ E (TPC-E) is a new On-Line Transaction Processing (OLTP) workload developed by the TPC. The TPC-E benchmark uses a database to model a brokerage firm with customers who generate transactions related to trades, account inquiries, and market research. The brokerage firm in turn interacts with financial markets to execute orders on behalf of the customers and updates relevant account information.
- The benchmark is “scalable,” meaning that the number of customers defined for the brokerage firm can be varied to represent the workloads of different-size businesses. The benchmark defines the required mix of transactions the benchmark must maintain. The TPC-E metric is given in transactions per second (tps). It specifically refers to the number of Trade-Result transactions the server can sustain over a period of time.
- Although the underlying business model of TPC-E is a brokerage firm, the database schema, data population, transactions, and implementation rules have been designed to be broadly representative of modern OLTP systems.
- TCP-H: The TPC Benchmark-H (TPC-H) is a decision support benchmark. It consists of a suite of business oriented ad-hoc queries and concurrent data modifications. The queries and the data populating the database have been chosen to have broad industry-wide relevance. This benchmark illustrates decision support systems that examine large volumes of data, execute queries with a high degree of complexity, and give answers to critical business questions.
- The performance metric reported by TPC-H is called the TPC-H Composite Query-per-Hour Performance Metric (QphH@Size), and reflects multiple aspects of the capability of the system to process queries. These aspects include the selected database size against which the queries are executed, the query processing power when queries are submitted by a single stream, and the query throughput when queries are submitted by multiple concurrent users. The TPC-H Price/Performance metric is expressed as $/QphH@Size.