== IMPLEMENTATIONS ==
Model Customization
- Steps
- Prepare a labeled dataset and, if needed, a validation dataset. Ensure the training data is in the required format, such as JSON Lines (JSONL), for structured input and output pairs.
- Configure IAM permissions to access the S3 buckets containing your data. You can either use an existing IAM role or let the console create a new one with the necessary permissions.
- Optionally set up KMS keys and/or a VPC for additional security to protect your data and secure communication.
- Start a training job by either fine-tuning a model on your dataset or continuing pre-training with additional data. Adjust hyperparameters to optimize performance.
- Start a training job by either fine-tuning a model on your dataset or continuing pre-training with additional data. Adjust hyperparameters to optimize performance.
- Buy Provisioned Throughput for the fine-tuned model to support high-throughput deployment and handle the expected load.
- Deploy the customized model and use it for inference tasks in Amazon Bedrock. The model will now have enhanced capabilities tailored to your specific needs.
- As summarised
- Prepare a labeled dataset in JSONL format with fraud examples
- Adjust hyperparameters and create a Fine-tuning job
- Analyze the results by reviewing training or validation metrics
- Purchase provisioned throughput for the fine-tuned model
- Use the customized model in Amazon Bedrock tasks
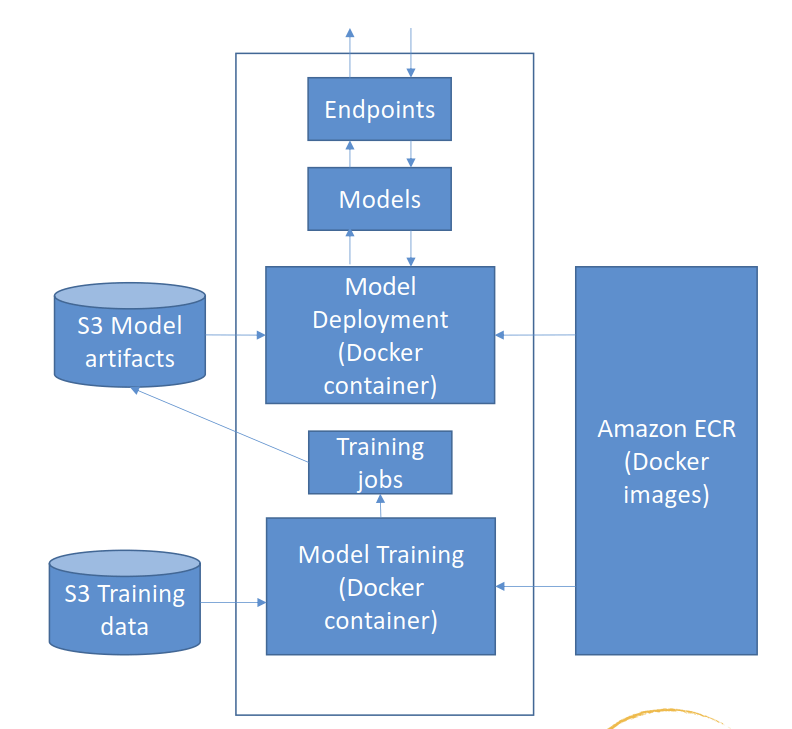
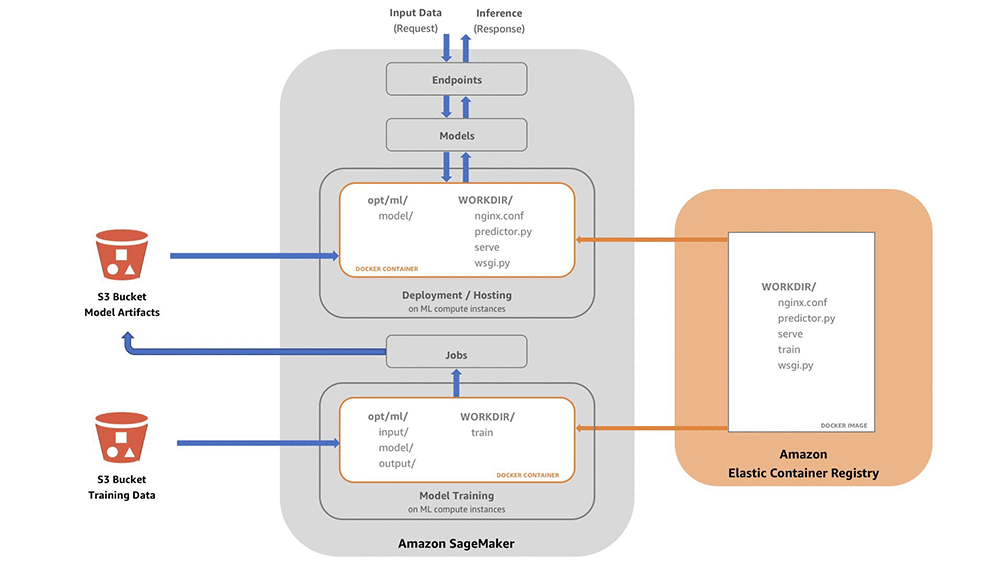
— Docker Container —
SageMaker and Docker Containers
- All models in SageMaker are hosted in Docker containers
- Docker containers are created from images
- Images are built from a Dockerfile
- Images are saved in a repository
- Amazon Elastic Container Registry (ECR)
- Recommended to wrap the custom codes into custom Docker container, push it to the Amazon Elastic Container Registry (Amazon ECR), and use it as a processing container in SageMaker AI
- Amazon SageMaker Containers
- Library for making containers compatible with SageMaker
- RUN
pip install sagemaker-containersin your Dockerfile
- Environment variables
- SAGEMAKER_PROGRAM
- Run a script inside /opt/ml/code
- The SageMaker containers library places the scripts that the container will run in the
/opt/ml/code/directory. Your script should write the model generated by your algorithm to the/opt/ml/model/directory. (where the final model artifacts are written) - After copying the script to the location inside the container that is expected by SageMaker, you must define it as the script entry point in the
SAGEMAKER_PROGRAMenvironment variable. When training starts, the interpreter executes the entry point defined bySAGEMAKER_PROGRAM.
- SAGEMAKER_TRAINING_MODULE
- SAGEMAKER_SERVICE_MODULE
- SM_MODEL_DIR
- SM_CHANNELS / SM_CHANNEL_*
- SM_HPS / SM_HP_*
- SM_USER_ARGS
- SAGEMAKER_PROGRAM
- Production Variants
- test out multiple models on live traffic using Production Variants
- Variant Weights tell SageMaker how to distribute traffic among them
- So, you could roll out a new iteration of your model at say 10% variant weight
- Once you’re confident in its performance, ramp it up to 100%
- do A/B tests, and to validate performance in real-world settings
- Offline validation isn’t always useful
- Shadow Variants
- Deployment Guardrails
- test out multiple models on live traffic using Production Variants
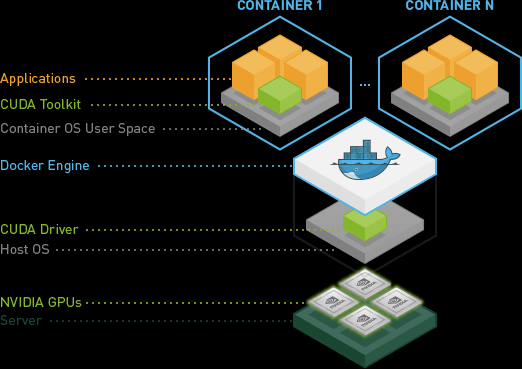
- If you plan to use GPU devices for model training, make sure that your containers are nvidia-docker compatible. Include only the CUDA toolkit on containers; don’t bundle NVIDIA drivers with the image.
/opt/ml
├── input
│ ├── config
│ │ ├── hyperparameters.json
│ │ └── resourceConfig.json
│ └── data
│ └── <channel_name>
│ └── <input data>
├── model
│
├── code
│
├── output
│
└── failure
— Machine Learning Operations (MLOps) —
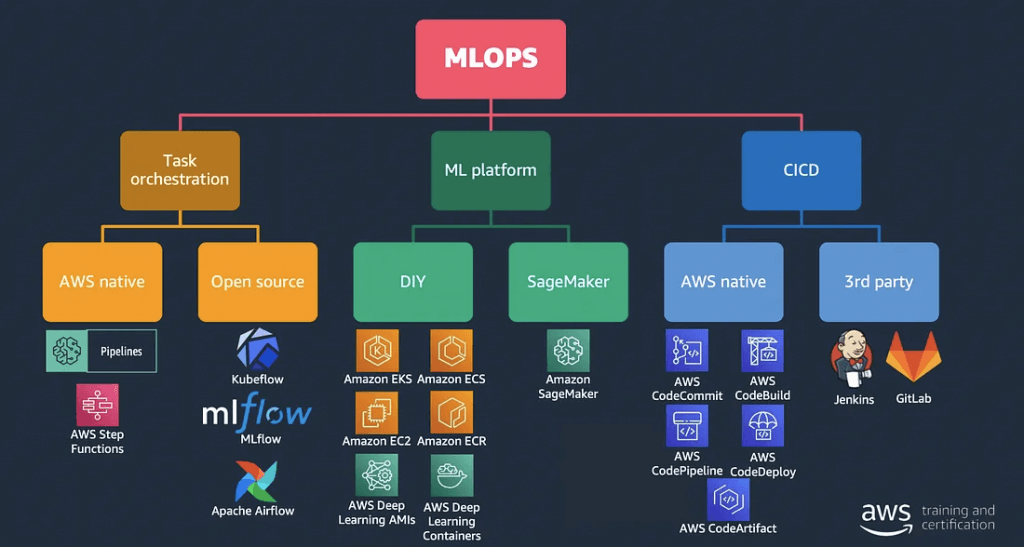
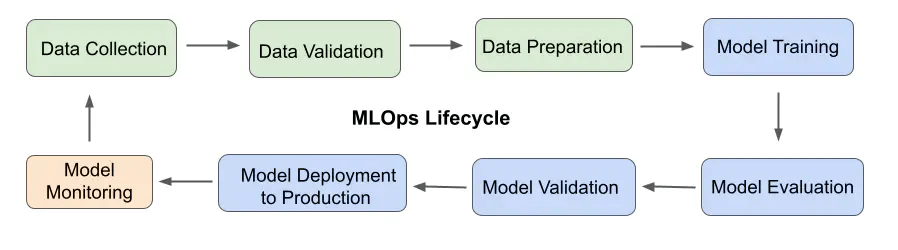
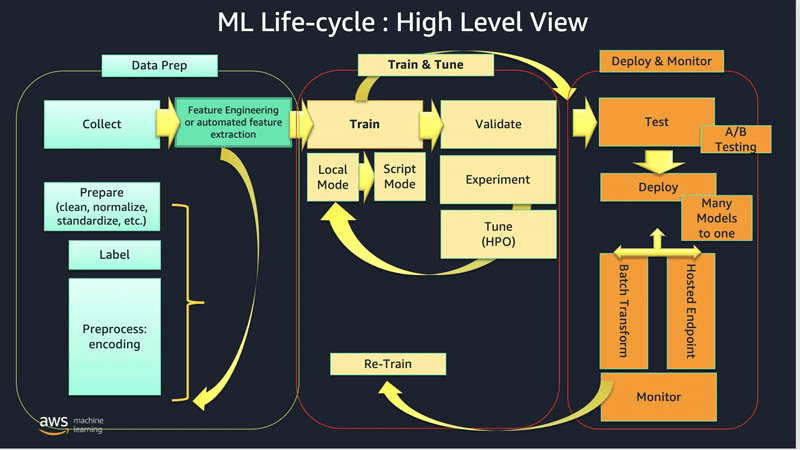
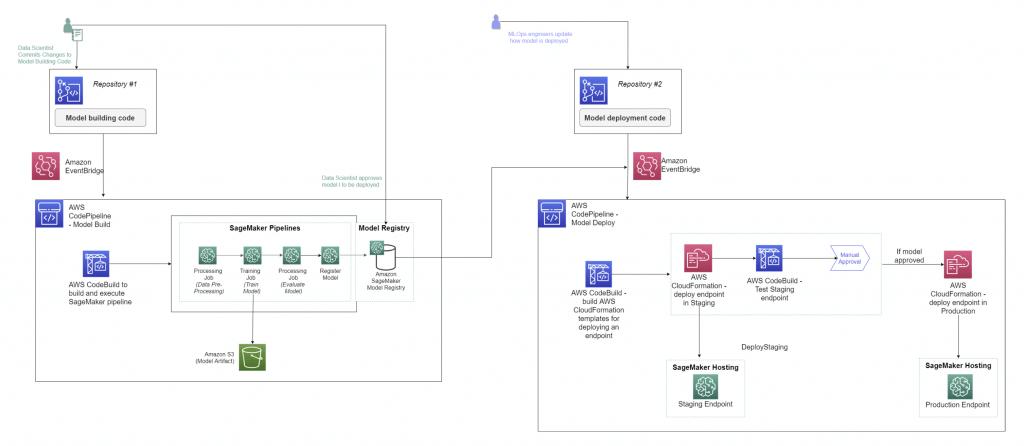
SageMaker Projects
- set up dependency management, code repository management, build reproducibility, and artifact sharing
- SageMaker Studio’s native MLOps solution with CI/CD
- Build images
- Prep data, feature engineering
- Train models
- Evaluate models
- Deploy models
- Monitor & update models
- Uses code repositories for building & deploying ML solutions
- Uses SageMaker Pipelines defining steps
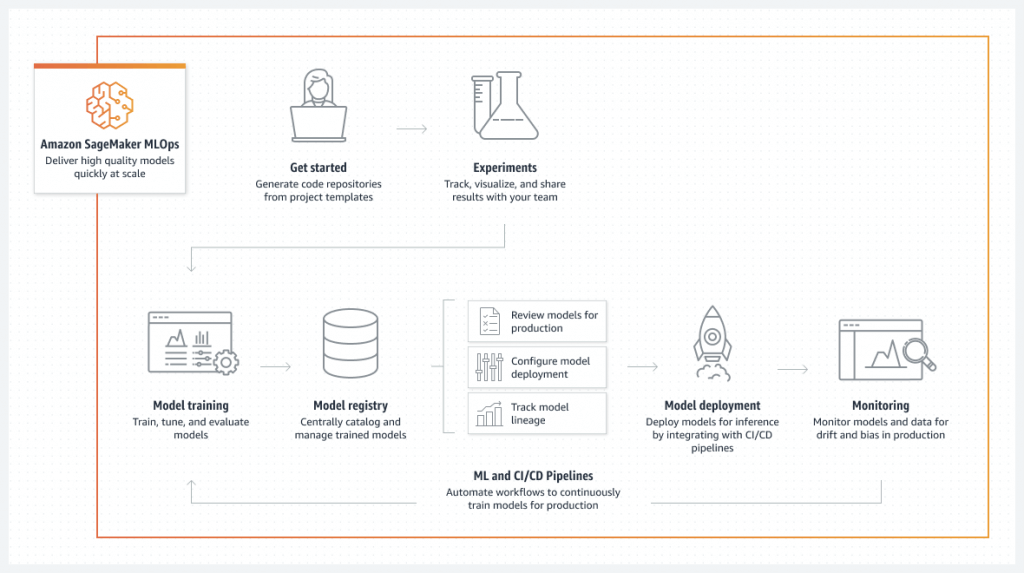

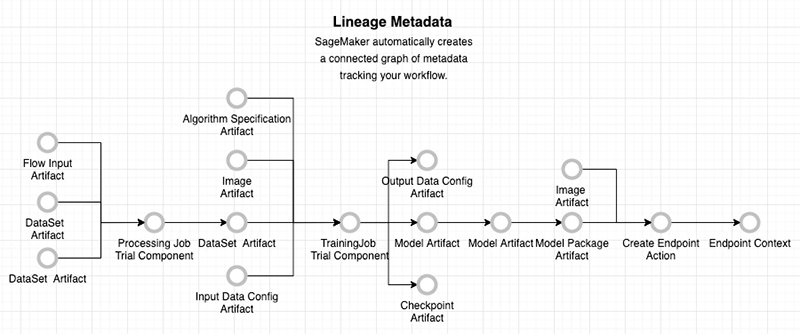
SageMaker ML Lineage Tracking (EOL on 2024/25)
- Model lineage graphs
- Creates & stores your ML workflow (MLOps)
- a visualization of your entire ML workflow from data preparation to deployment
- use entities to represent individual steps in your workflow
- Keep a running history of your models
- Tracking for auditing and compliance
- Automatically or manually-created tracking entities
- Integrates with AWS Resource Access Manager for cross-account lineage
- Entities
- Trial component (processing jobs, training jobs, transform jobs)
- Trial (a model composed of trial components)
- Experiment (a group of Trials for a given use case)
- Context (logical grouping of entities)
- Action (workflow step, model deployment
- Artifact (Object or data, such as an S3 bucket or an image in ECR)
- Association (connects entities together) – has optional AssociationType:
- ContributedTo
- AssociatedWith
- DerivedFrom
- Produced
- SameAs
- Querying
- Use the LineageQuery API from Python
- Part of the Amazon SageMaker SDK for Python
- Do things like find all models / endpoints / etc. that use a given artifact
- Produce a visualization
- Requires external Visualizer helper class
- Use the LineageQuery API from Python
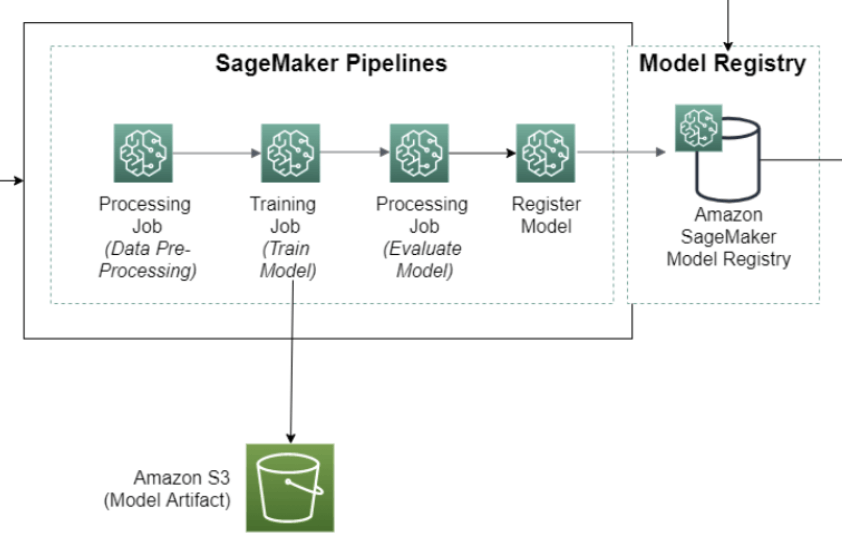
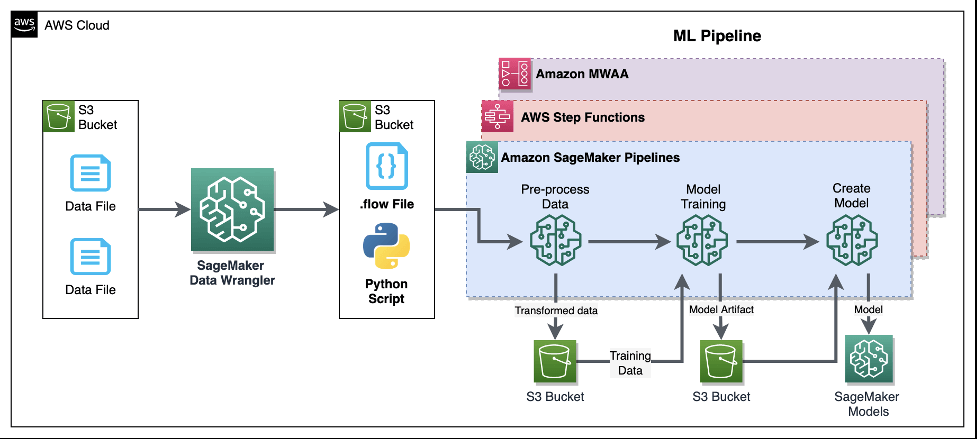
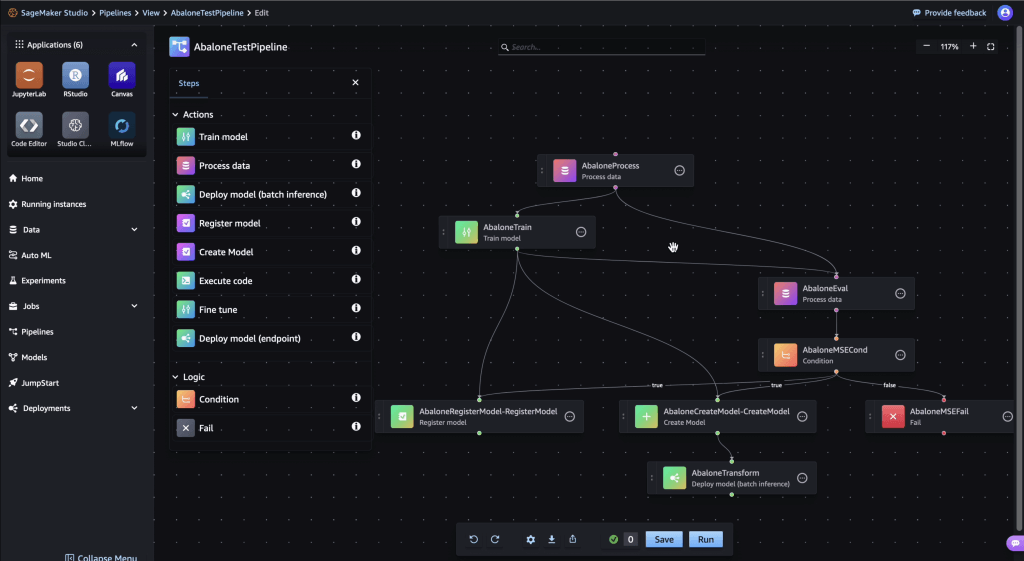
Amazon SageMaker (ML) Pipeline
- allows you to create, automate, and manage end-to-end ML workflows
- consists of multiple steps, each representing a specific task or operation in the ML workflow.
- data processing
- model training
- model evaluation
- model deployment
- series of interconnected steps in directed acyclic graph (DAG)
- UI or can using the pipeline definition JSON schema
- composed of
- name
- parameters
- steps
- A step property is an attribute of a step that represents the output values from a step execution
- For a step that references a SageMaker job, the step property matches the attributes of that SageMaker job
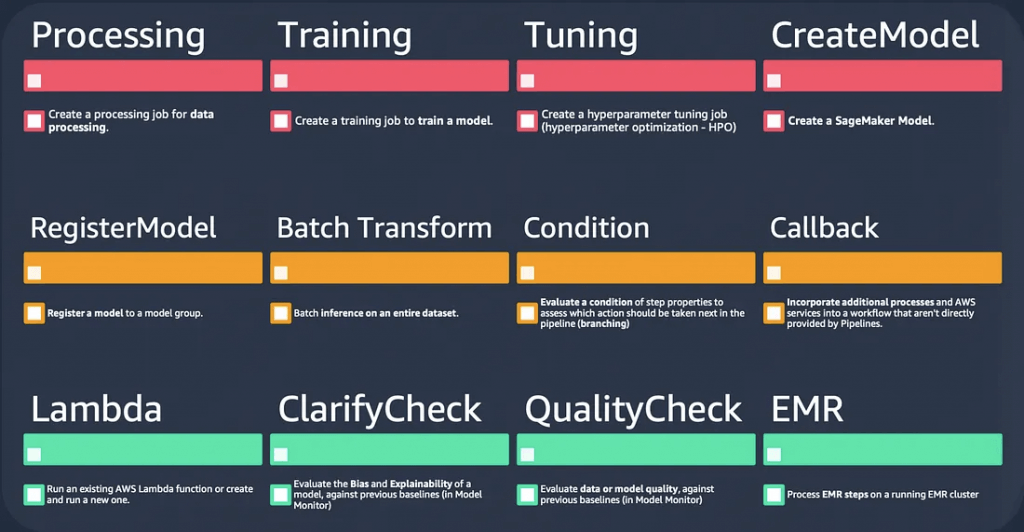
- ProcessingStep
- TrainingStep
- TransformStep
- TuningStep
- AutoMLStep
- ModelStep
- CallbackStep
- LambdaStep
- ClarifyCheckStep
- QualityCheckStep
- EMRStep
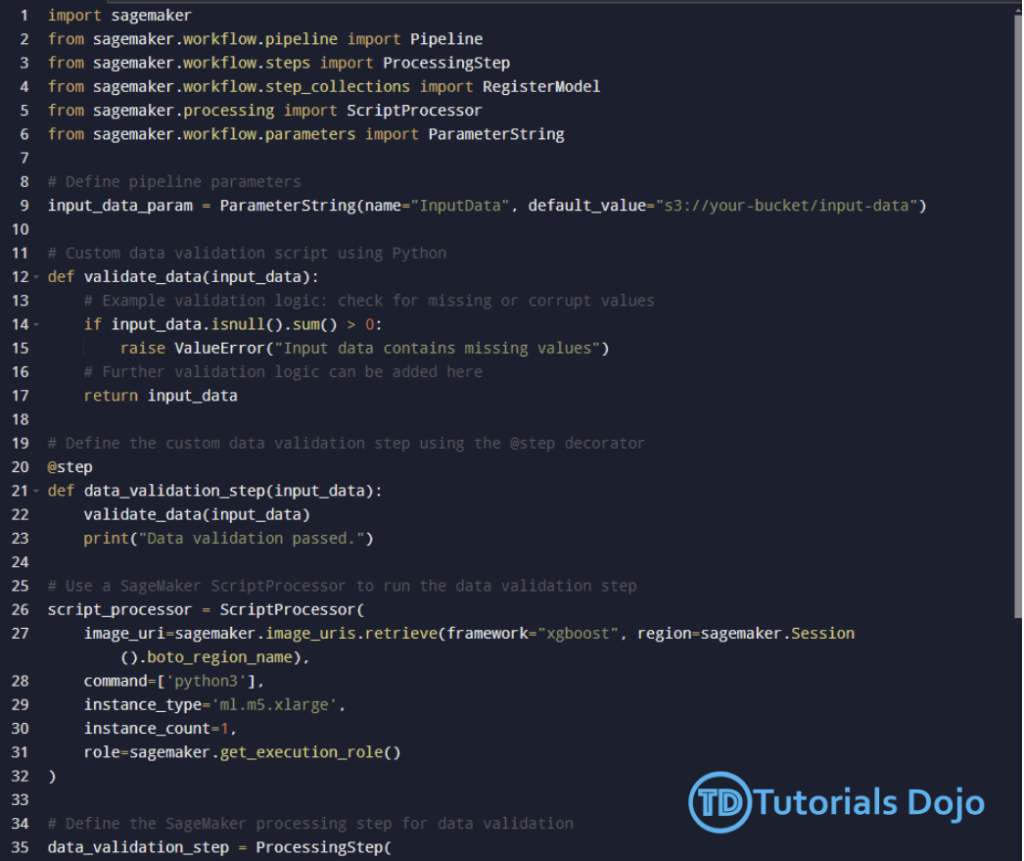
- @step decorator : custom ML job
- define custom logic within a pipeline step and ensure it works seamlessly within the workflow
- example, create a simple python function to do data validation
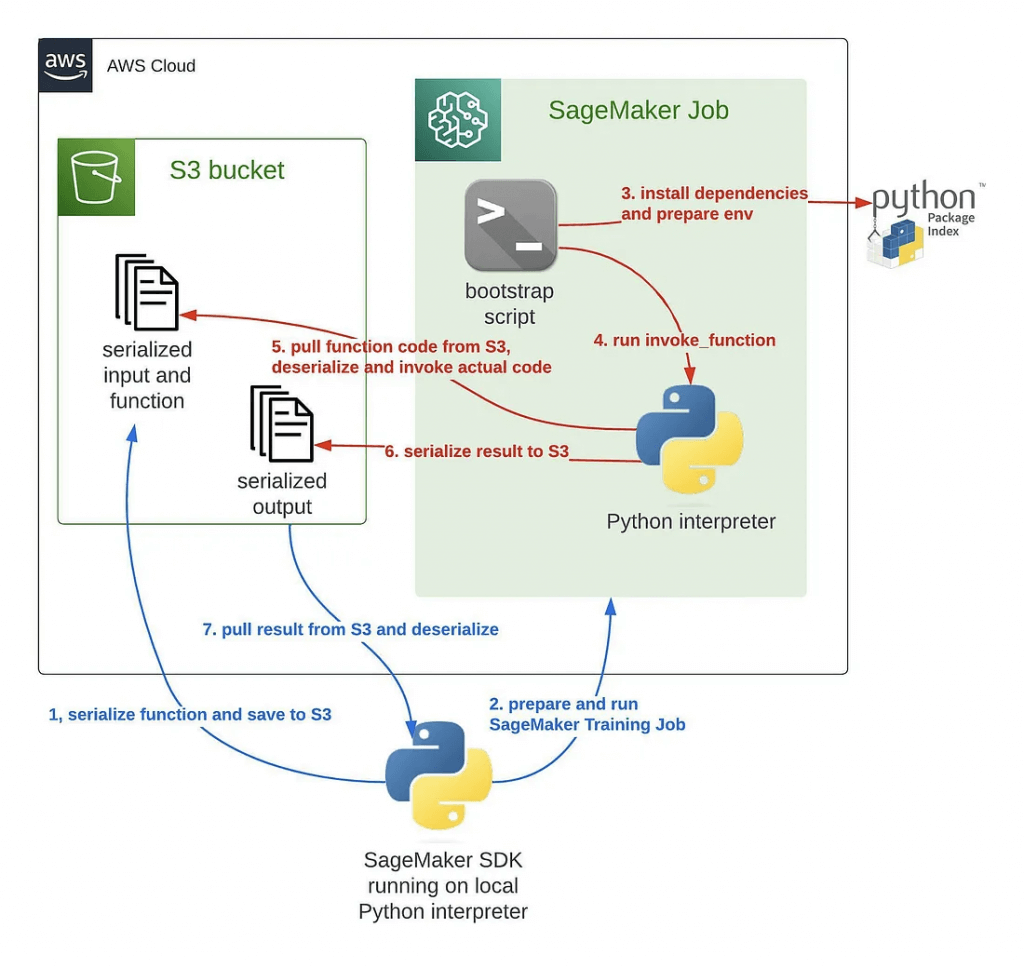
- @remote decorator : remote function calls
- It simplifies the execution of machine learning workflows by allowing you to run code remotely in a SageMaker environment, making it easier to scale your workloads, distribute computations, and leverage SageMaker infrastructure efficiently.

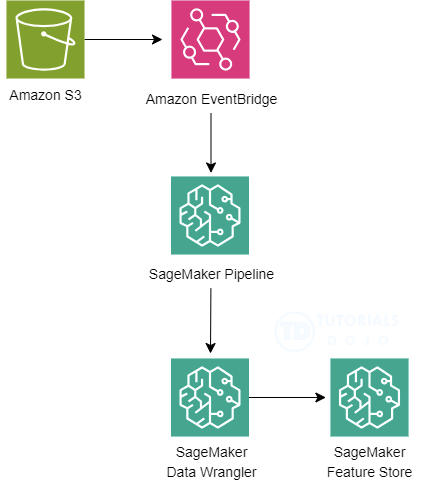
AWS Step Functions
- create workflows, also called State machines, to build distributed applications, automate processes, orchestrate microservices, and create data and machine learning pipelines
- based on state machines and tasks. In Step Functions, state machines are called workflows, which are a series of event-driven steps. Each step in a workflow is called a state. For example, a Task state represents a unit of work that another AWS service performs, such as calling another AWS service or API. Instances of running workflows performing tasks are called executions in Step Functions.
- The work in your state machine tasks can also be done using Activities which are workers that exist outside of Step Functions.
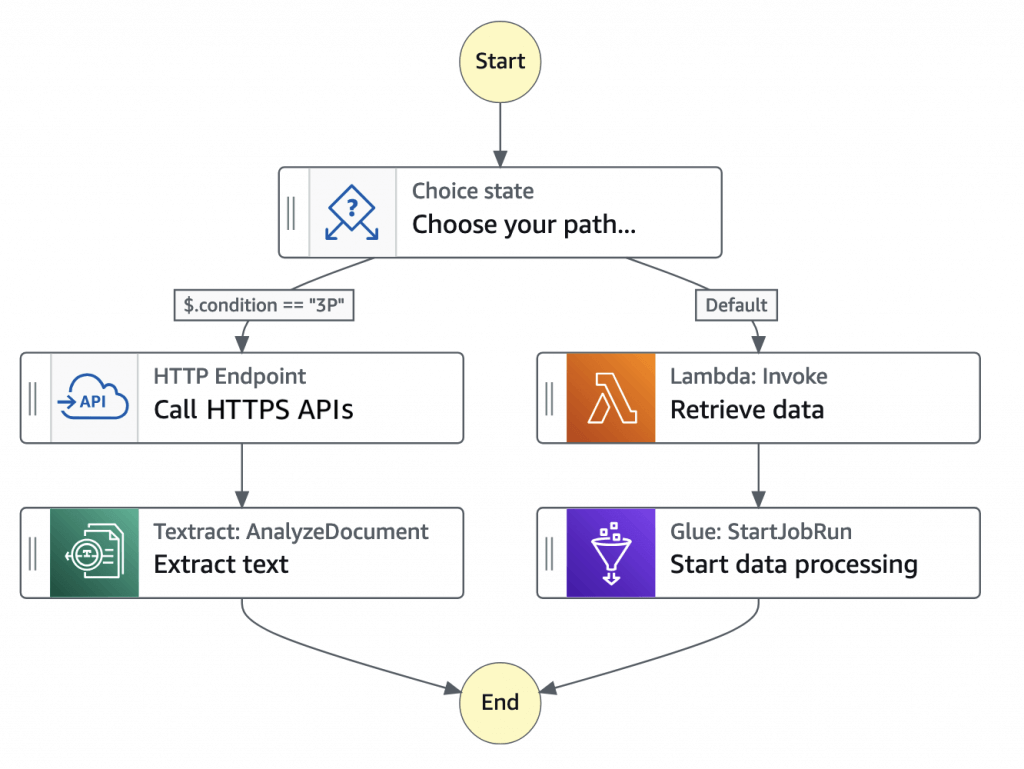
| Integrated service | Request Response | Run a Job – .sync | Wait for Callback – .waitForTaskToken |
|---|---|---|---|
| Amazon API Gateway | Standard & Express | Not supported | Standard |
| Amazon Athena | Standard & Express | Standard | Not supported |
| AWS Batch | Standard & Express | Standard | Not supported |
| Amazon Bedrock | Standard & Express | Standard | Standard |
| AWS CodeBuild | Standard & Express | Standard | Not supported |
| Amazon DynamoDB | Standard & Express | Not supported | Not supported |
| Amazon ECS/Fargate | Standard & Express | Standard | Standard |
| Amazon EKS | Standard & Express | Standard | Standard |
| Amazon EMR | Standard & Express | Standard | Not supported |
| Amazon EMR on EKS | Standard & Express | Standard | Not supported |
| Amazon EMR Serverless | Standard & Express | Standard | Not supported |
| Amazon EventBridge | Standard & Express | Not supported | Standard |
| AWS Glue | Standard & Express | Standard | Not supported |
| AWS Glue DataBrew | Standard & Express | Standard | Not supported |
| AWS Lambda | Standard & Express | Not supported | Standard |
| AWS Elemental MediaConvert | Standard & Express | Standard | Not supported |
| Amazon SageMaker AI | Standard & Express | Standard | Not supported |
| Amazon SNS | Standard & Express | Not supported | Standard |
| Amazon SQS | Standard & Express | Not supported | Standard |
| AWS Step Functions | Standard & Express | Standard | Standard |
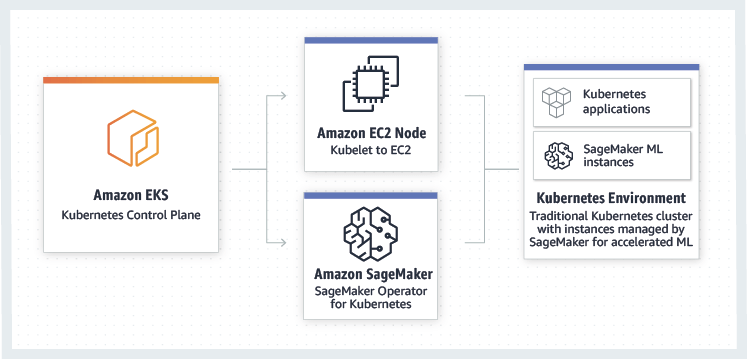
— Kubernetes —
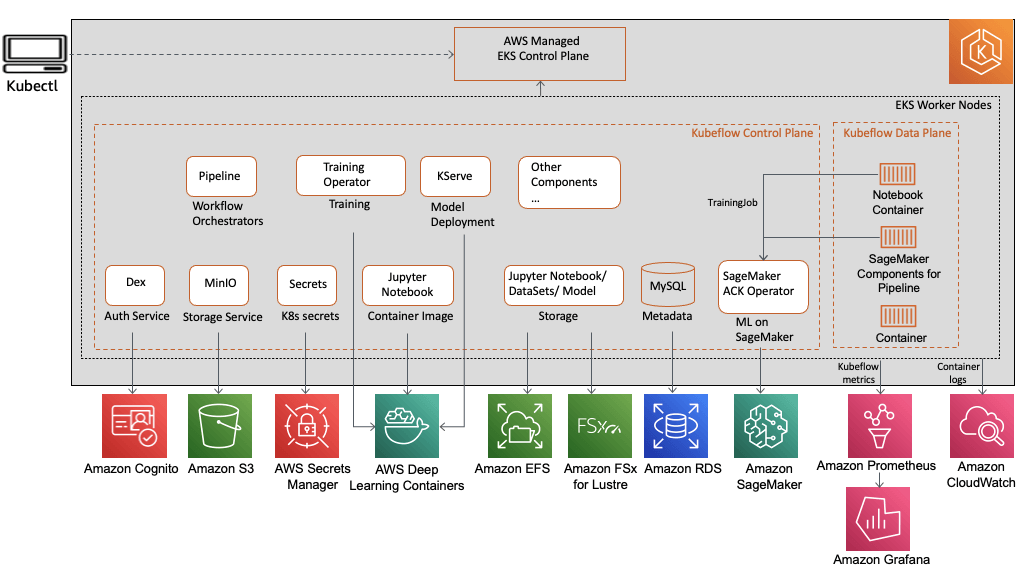
Amazon SageMaker Operators for Kubernetes
- Integrates SageMaker with Kubernetes-based ML infrastructure
- Components for Kubeflow Pipelines
- Enables hybrid ML workflows (on-prem + cloud)
- Enables integration of existing ML platforms built on Kubernetes / Kubeflow
== MISC ==
Managing SageMaker Resources
- In general, algorithms that rely on deep learning will benefit from GPU instances (P3, g4dn) for training
- Inference is usually less demanding and you can often get away with compute instances there (C5)
- Can use EC2 Spot instances for training
- Save up to 90% over on-demand instances
- Spot instances can be interrupted!
- Use checkpoints to S3 so training can resume
- Can increase training time as you need to wait for spot instances to become available
- Elastic Inference (EI) / Amazon SageMaker Inference
- attach just the right amount of GPU-powered acceleration to any Amazon EC2 and Amazon SageMaker instance
- Accelerates deep learning inference
- At fraction of cost of using a GPU instance for inference
- EI accelerators may be added alongside a CPU instance
- ml.eia1.medium / large / xlarge
- EI accelerators may also be applied to notebooks
- Works with Tensorflow, PyTorch, and MXNet pre-built containers
- ONNX may be used to export models to MXNet
- Works with custom containers built with EI-enabled Tensorflow, PyTorch, or MXNet
- Works with Image Classification and Object Detection built-in algorithms
- Automatic Scaling
- “Real-time endpoints” typically keep instances running even when there is no traffic; so it’s good to solve the peak traffic, but not the best cost-saving
- Serverless Inference
- Specify your container, memory requirement, concurrency requirements
- Underlying capacity is automatically provisioned and scaled
- Good for infrequent or unpredictable traffic; will scale down to zero when there are no
requests- a cost-effective option for workloads with intermittent or unpredictable traffic
- “Provisioned Concurrency” ensures that the model is always available, with extra cost for the reserved capacity even unused; but this can prevent the “cold-start” issue
- Charged based on usage
- Monitor via CloudWatch
- ModelSetupTime, Invocations, MemoryUtilization
- Amazon SageMaker Inference Recommender
- Availability Zones
- automatically attempts to distribute instances across availability zones
- Deploy multiple instances for each production endpoint
- Configure VPC’s with at least two subnets, each in a different AZ
== SECURITY ==
SageMaker Security
- Use Identity and Access Management (IAM)
- User permissions for:
- CreateTrainingJob
- CreateModel
- CreateEndpointConfig
- CreateTransformJob
- CreateHyperParameterTuningJob
- CreateNotebookInstance
- UpdateNotebookInstance
- Predefined policies:
- AmazonSageMakerReadOnly
- AmazonSageMakerFullAccess
- AdministratorAccess
- DataScientist
- User permissions for:
- Set up user accounts with only the permissions they need
- Use MFA
- Use SSL/TLS when connecting to anything
- Use CloudTrail to log API and user activity
- Use encryption
- AWS Key Management Service (KMS)
- Accepted by notebooks and all SageMaker jobs
- Training, tuning, batch transform, endpoints
- Notebooks and everything under /opt/ml/ and /tmp can be encrypted with a KMS key
- Accepted by notebooks and all SageMaker jobs
- S3
- Can use encrypted S3 buckets for training data and hosting models
- S3 can also use KMS
- Protecting Data in Transit
- All traffic supports TLS / SSL
- IAM roles are assigned to SageMaker to give it permissions to access resources
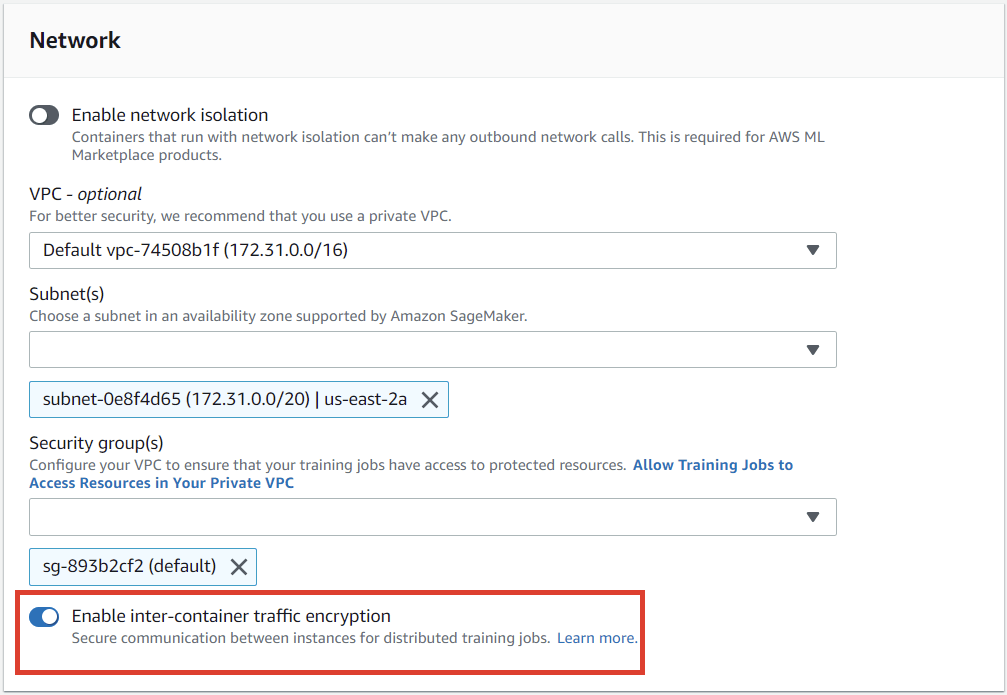
- Inter-node training communication may be optionally encrypted
- Can increase training time and cost with deep learning
- AKA inter-container traffic encryption
- Enabled via console or API when setting up a training or tuning job
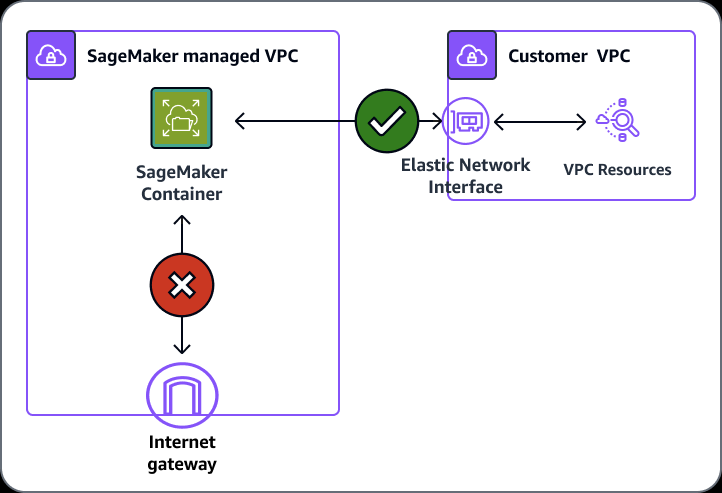
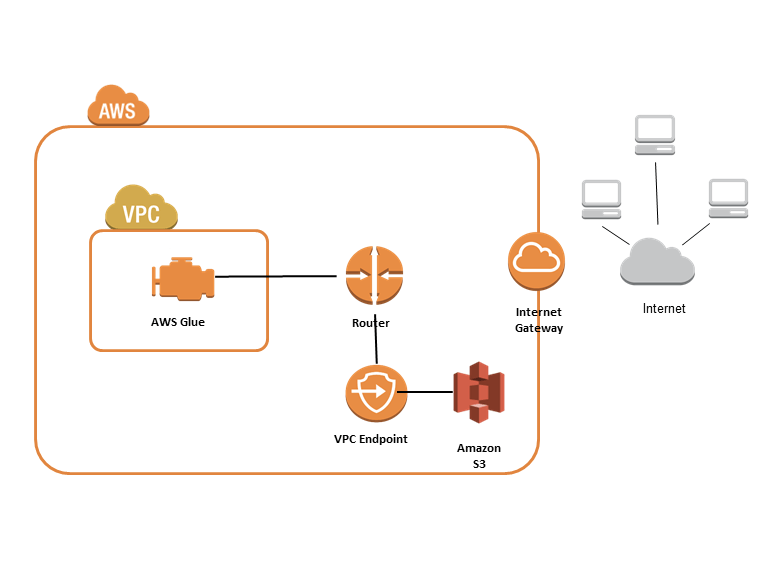
- VPC
- Training jobs run in a Virtual Private Cloud (VPC)
- You can use a private VPC for even more security
- You’ll need to set up S3 VPC endpoints
- Custom endpoint policies and S3 bucket policies can keep this secure
- Notebooks are Internet-enabled by default
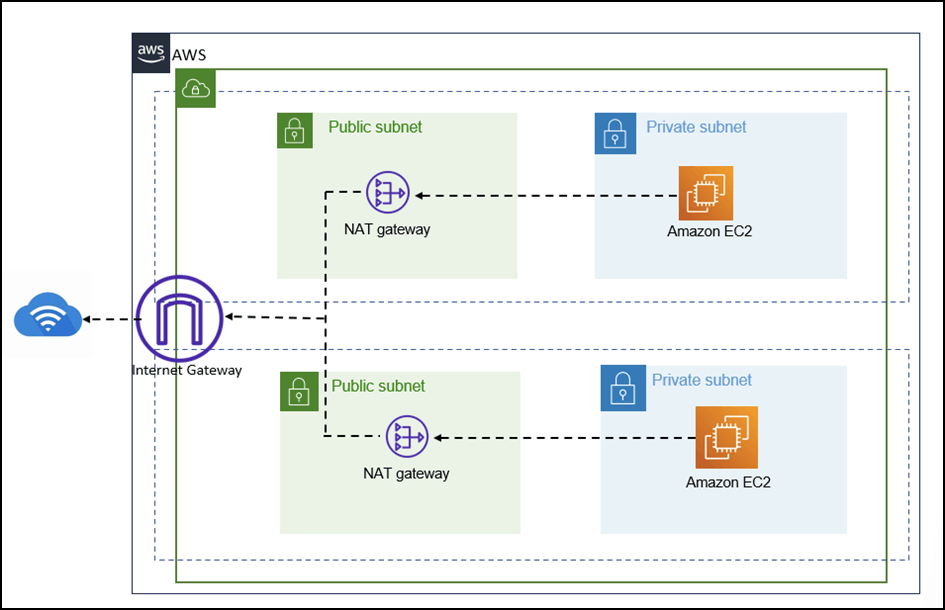
- If disabled, your VPC needs
- an interface endpoint (PrivateLink) and allow outbound connections (to other AWS services, like S3, AWS Comprehend), for training and hosting to work
- or NAT Gateway, and allow outbound connections (to Internet), for training and hosting to work
- If disabled, your VPC needs
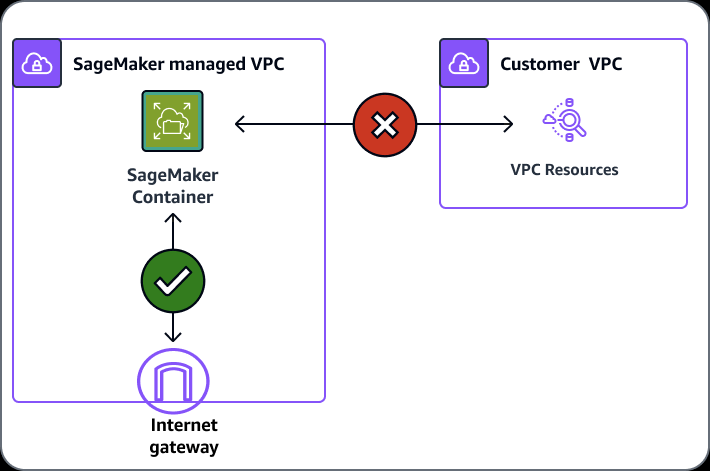
- Training and Inference Containers are also Internet-enabled by default
- Network isolation is an option, but this also prevents S3 access
- Enable the SageMaker parameter EnableNetworkIsolation for the notebook instances; so the instances wouldn’t be accessible from the Internet
- Network isolation is an option, but this also prevents S3 access
- Enabling inter-container traffic encryption can increase training time, especially if you are using distributed deep learning algorithms. Enabling inter-container traffic encryption doesn’t affect training jobs with a single compute instance. However, for training jobs with several compute instances, the effect on training time depends on the amount of communication between compute instances. For affected algorithms, adding this additional level of security also increases cost. The training time for most SageMaker built-in algorithms, such as XGBoost, DeepAR, and linear learner, typically isn’t affected.
- Logging and Monitoring
- CloudWatch can log, monitor and alarm on:
- Invocations and latency of endpoints
- Health of instance nodes (CPU, memory, etc)
- Ground Truth (active workers, how much they are doing)
- CloudTrail records actions from users, roles, and services within SageMaker
- Log files delivered to S3 for auditing
- CloudWatch can log, monitor and alarm on:
The CreatePresignedDomainUrl API generates secure presigned URLs that allow users to access specific Amazon SageMaker Studio domains. This API is essential for dynamically creating user-specific access links, ensuring secure and seamless connectivity to the designated SageMaker Studio domain
The Identity Provider (IdP) is used to authenticate users centrally. By integrating the IdP with the central proxy, users can securely log in using a single sign-on mechanism. This ensures that only authenticated users can access their designated SageMaker Studio domains.
The Amazon DynamoDB table stores user-domain mappings. Each user’s identity and access route are mapped to their specific SageMaker Studio domain, enabling the dynamic routing of users based on their identity.
The central proxy acts as the unified entry point for all users. It authenticates users through the IdP, retrieves their domain mappings from DynamoDB, and routes them to their designated SageMaker Studio domains using the presigned URLs generated by the CreatePresignedDomainUrl API.
SageMaker Studio domains are the individual environments used by different departments for machine learning workflows. The proposed solution dynamically routes users to their designated domains, ensuring centralized and streamlined access management.
Sensitive data that needs to be encrypted with a KMS key for compliance reasons should be stored in the ML storage volume or in Amazon S3, both of which can be encrypted using a KMS key you specify. Additionally, you can use AWS Glue’s sensitive data detection to redact Personal Identifiable Information (PII) and other sensitive data at both the column and cell levels.
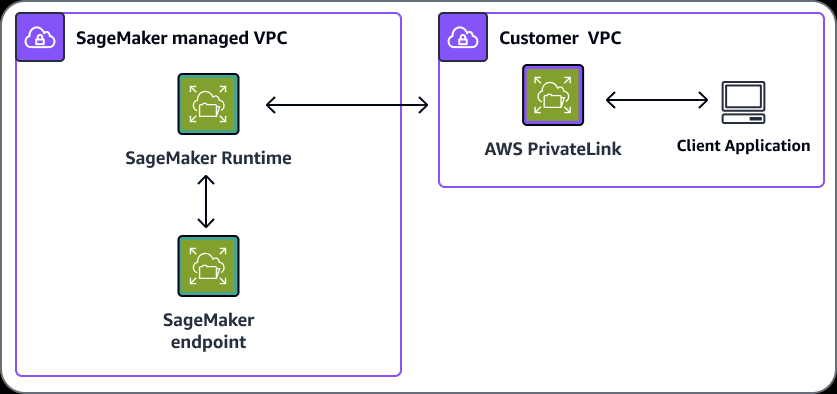
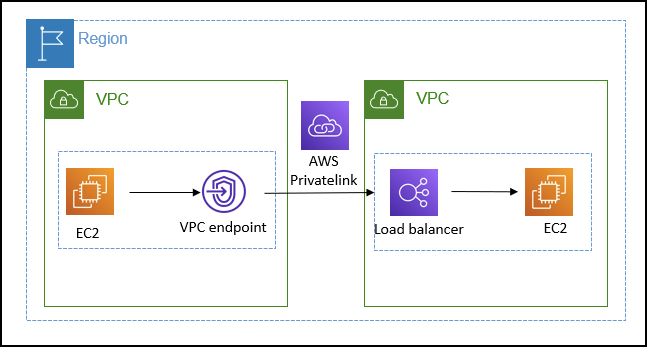
Private Connection among SageMaker and customer VPC
- You can connect directly to the SageMaker API or to the SageMaker Runtime through an interface endpoint in your Virtual Private Cloud (VPC) instead of connecting over the internet. When you use a VPC interface endpoint, communication between your VPC and the SageMaker API or Runtime is conducted entirely and securely within the AWS network.
- The SageMaker API and Runtime support Amazon Virtual Private Cloud (Amazon VPC) interface endpoints that are powered by AWS PrivateLink. Each VPC endpoint is represented by one or more Elastic Network Interfaces with private IP addresses in your VPC subnets.
- The VPC interface endpoint connects your VPC directly to the SageMaker API or Runtime without an internet gateway, NAT device, VPN connection, or AWS Direct Connect connection. The instances in your VPC don’t need public IP addresses to communicate with the SageMaker API or Runtime.
== COST OPTIMISATION ==
AWS Cost Management
- Operations for Cost Allocation Tracking/Analysis
- STEP ONE: create user-defined tags with key-value pairs that reflect attributes such as project names or departments to ensure proper categorization of resources
- STEP TWO: apply these tags to the relevant resources to enable tracking
- STEP THREE: enable the cost allocation tags in the Billing console
- (AFTER) STEP FOUR: Configure tag-based cost and usage reports (AWS Cost Allocation Reports) for detailed analysis in Cost Explorer
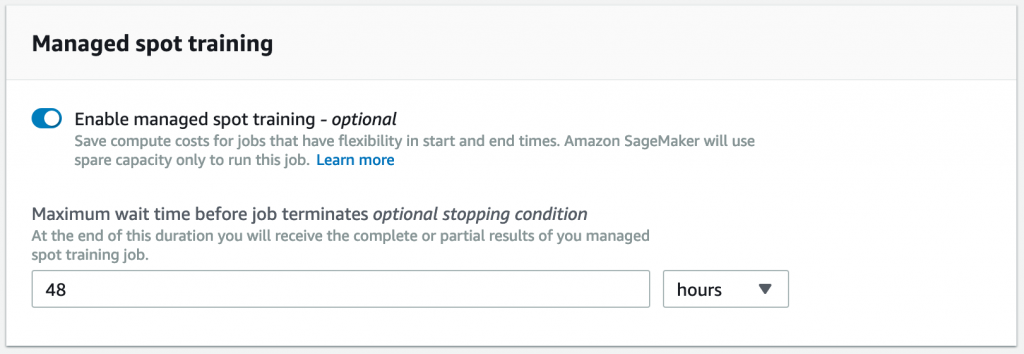
Managed Spot Training uses Amazon EC2 Spot instance to run training jobs instead of on-demand instances. You can specify which training jobs use spot instances and a stopping condition that specifies how long SageMaker waits for a job to run using Amazon EC2 Spot instances. Managed spot training can optimize the cost of training models up to 90% over on-demand instances. SageMaker manages the Spot interruptions on your behalf.
To avoid restarting a training job from scratch should it be interrupted, it is strongly recommended that you implement checkpointing which is a technique that saves the model in training at periodic intervals. With this, you can resume a training job from a well-defined point in time, continuing from the most recent partially trained model.
The maximum wait time just refers to the time it takes to receive the complete or partial results of a managed spot training job.
Amazon API Gateway is a fully managed service that makes it easy for developers to create, publish, maintain, monitor, and secure APIs at any scale. API Gateway can be used to present an external-facing, single point of entry for Amazon SageMaker endpoints.
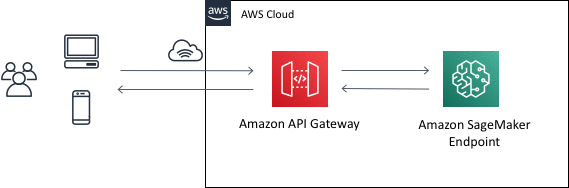
API Gateway can be used to front an Amazon SageMaker inference endpoint as (part of) a REST API, by making use of an API Gateway feature called mapping templates. This feature makes it possible for the REST API to be integrated directly with an Amazon SageMaker runtime endpoint, thereby avoiding the use of any intermediate compute resource (such as AWS Lambda or Amazon ECS containers) to invoke the endpoint. The result is a solution that is simpler, faster, and cheaper to run.