AWS Data Stores for Machine Learning
- Redshift
- Data Warehousing, SQL analytics (OLAP – Online analytical processing)
- Load data from S3 to Redshift
- Use Redshift Spectrum to query data directly in S3 (no loading)
- RDS, Aurora
- Relational Store, SQL (OLTP – Online Transaction Processing)
- Must provision servers in advance
- DynamoDB
- NoSQL data store, serverless, provision read/write capacity
- Useful to store a machine learning model served by your application
- S3
- Object storage
- Serverless, infinite storage
- Integration with most AWS Services
- OpenSearch (previously ElasticSearch)
- Indexing of data
- Search amongst data points
- Clickstream Analytics
ElastiCacheCaching mechanismNot really used for Machine Learning
=== DATA (FILE) ===
S3
- Common formats for ML: CSV, JSON, Parquet, ORC, Avro, Protobuf
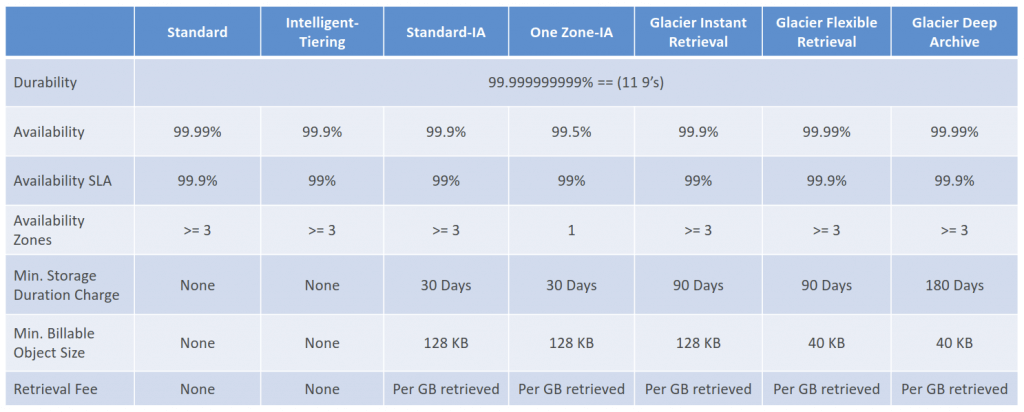
- Storage Classes
- Amazon S3 Standard – General Purpose
- Amazon S3 Standard-Infrequent Access (IA)
- Amazon S3 One Zone-Infrequent Access
- data lost when AZ is destroyed
- Amazon S3 Glacier Instant Retrieval
- Millisecond retrieval
- Minimum storage duration of 90 days
- Amazon S3 Glacier Flexible Retrieval
- Expedited (1 to 5 minutes), Standard (3 to 5 hours), Bulk (5 to 12 hours)
- Minimum storage duration of 90 days
- Amazon S3 Glacier Deep Archive
- Standard (12 hours), Bulk (48 hours)
- Minimum storage duration of 180 days
- Amazon S3 Intelligent Tiering
- Moves objects automatically between Access Tiers based on usage
- There are no retrieval charges in S3 Intelligent-Tiering
- Can managed with S3 Lifecycle
- Objects must be stored for at least 30 days before transitioning to S3 Standard-IA or S3 One Zone-IA
- Lifecycle Rules
- Transition Actions
- Expiration actions
- Can be used to delete old versions of files (if versioning is enabled)
- Can be used to delete incomplete Multi-Part uploads
- Enable S3 Versioning in order to have object versions, so that “deleted objects” are in fact hidden by a “delete marker” and can be recovered
- Amazon S3 Event Notifications allow you to receive notifications when certain events occur in your S3 bucket, such as object creation or deletion.
- AWS Lambda can be directly triggered through S3 Event Notifications
- S3 Analytics
- decide when to transition objects to the right storage class
- analyze your object access patterns
- S3 Security
- User-Based (IAM Policies)
- Resource-Based (Bucket Policies)
- Grant public access to the bucket
- Force objects to be encrypted at upload
- Grant access to another account (Cross Account)
- Object Encryption
- Server-Side Encryption (SSE)
- Server-Side Encryption with Amazon S3-Managed Keys (SSE-S3) – Default
- automatically applied to new objects stored in S3 bucket
- Encryption type is AES-256
- header “x-amz-server-side-encryption”: “AES256”
- Server-Side Encryption with KMS Keys stored in AWS KMS (SSE-KMS)
- KMS advantages: user control + audit key usage using CloudTrail
- header “x-amz-server-side-encryption”: “aws:kms”
- When you upload, it calls the GenerateDataKey KMS API
- When you download, it calls the Decrypt KMS API
- Server-Side Encryption with Customer-Provided Keys (SSE-C)
- Amazon S3 does NOT store the encryption key you provide
- HTTPS must be used
- Encryption key must provided in HTTP headers, for every HTTP request made
- Server-Side Encryption with Amazon S3-Managed Keys (SSE-S3) – Default
- Client-Side Encryption
- Server-Side Encryption (SSE)
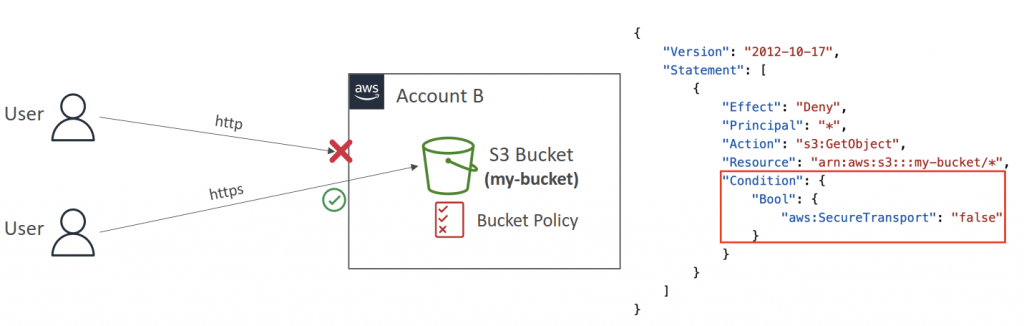
- Encryption in transit (SSL/TLS)
- aka “Encryption in flight”
- Amazon S3 exposes two endpoints:
- HTTP Endpoint – non encrypted
- HTTPS Endpoint – encryption in flight
- mandatory for SSE-C
- Set Condition in the Bucket Policy, with “aws:SecureTransport”
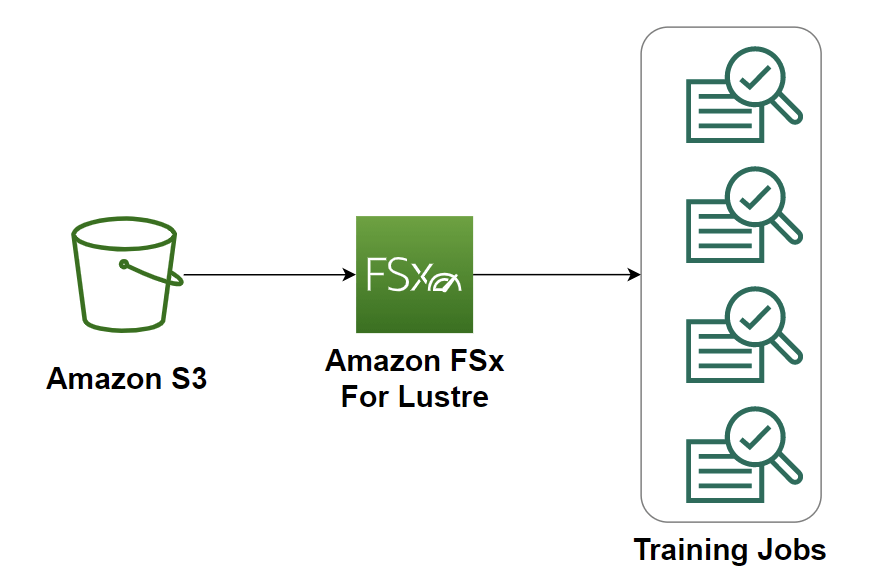
- For faster transfer, could apply “Amazon FSx for Lustre”.
- Amazon FSx for Lustre provides a high-performance file system natively integrated with Amazon Simple Storage Service (S3)
With AWS Lake Formation, organizations can build, secure, and manage data lakes on Amazon S3 more efficiently. Lake Formation simplifies data ingestion, cleaning, cataloging, and secure access control, ensuring that only authorized users can access specific datasets. It integrates with AWS Glue, allowing schema inference and metadata management while enabling fine-grained access control for multiple teams.
A data lake is a centralized repository that allows structured and unstructured data storage at any scale. With Lake Formation, you can easily define access policies and use attribute-based access control (ABAC), ensuring governance and security while still enabling different analytics workloads.
Amazon Athena is an interactive query service that allows querying of data stored in Amazon S3 using standard SQL, eliminating the need for complex ETL processes. It works seamlessly with AWS Lake Formation, ensuring governed queries based on predefined permissions.
Data lakes on AWS help you break down data silos to maximize end-to-end data insights.
With AWS Lake Formation, you can build secure data lakes in days instead of months.
=== DATA (STREAM) ===
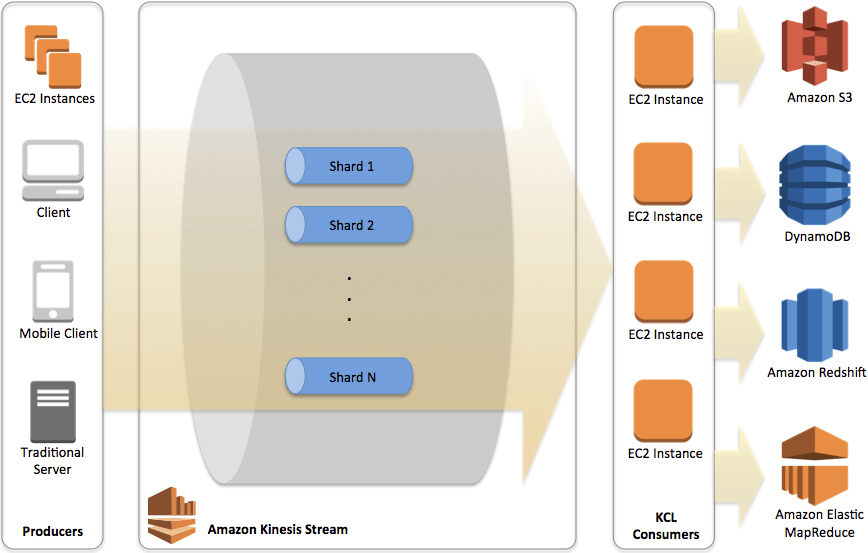
Kinesis Data Streams
- Collect and store streaming data in real-time
- data retention, data replication, and automatic load balancing
- Retention between 24 hours up to 365 days
- Data up to 1MB (typical use case is lot of “small” real-time data)
- Data ordering guarantee for data with the same “Partition ID”
- Capacity Modes
- Provisioned mode
- Each shard gets 1MB/s in (or 1000 records per second)
- Each shard gets 2MB/s out
- On-demand mode
- Default capacity provisioned (4 MB/s in or 4000 records per second)
- So if there are 8KB JSON as 1000 transactions per second to ingest, it means about 8MB/sec input, which would needs 8 shards in provisioned mode.
- Provisioned mode
- [ML] create real-time machine learning applications
- by using “Amazon Redshift streaming ingestion”, which simplifies the streaming architecture by providing native integration between Amazon Redshift and the streaming engines in AWS, which are Amazon Kinesis Data Streams and Amazon Managed Streaming for Apache Kafka (Amazon MSK).
- While you can configure Redshift as a destination for an Amazon Data firehose, Kinesis does not actually load the data directly into Redsfhit. Under the hood, Kinesis stages the data first in Amazon S3 and copies it into Redshift using the COPY command.
- The Amazon Kinesis Client Library (KCL) is different from the Kinesis Data Streams APIs that are available in the AWS SDKs. The Kinesis Data Streams APIs help you manage many aspects of Kinesis Data Streams, including creating streams, resharding, and putting and getting records. The KCL provides a layer of abstraction around all these subtasks, specifically so that you can focus on your consumer application’s custom data processing logic.
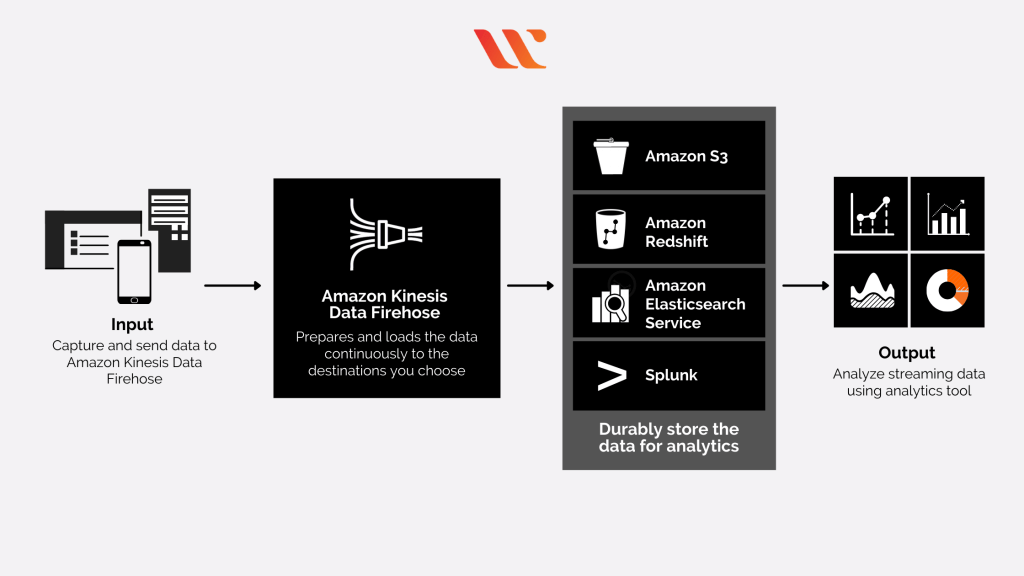
Amazon Data Firehose
- aka Kinesis Data Firehose
- Collect and store streaming data in real-time
- buffers incoming streaming data to a certain size and for a certain period of time before delivering it to the specified destinations
- Buffer size
- Buffer interval
- buffers incoming streaming data to a certain size and for a certain period of time before delivering it to the specified destinations
- Near Real-Time; in another words, suitable for batch processing
- Custom data transformations using AWS Lambda
- [ML] ingest massive data near-real time
- Kinesis Data Streams is for when you want to “real-time” control and manage the flow of data yourself, while Kinesis Data Firehose is for when you want the data to be “near-real-time” automatically processed and delivered to a specific destination(Redshift, S3, Splunk, etc.)
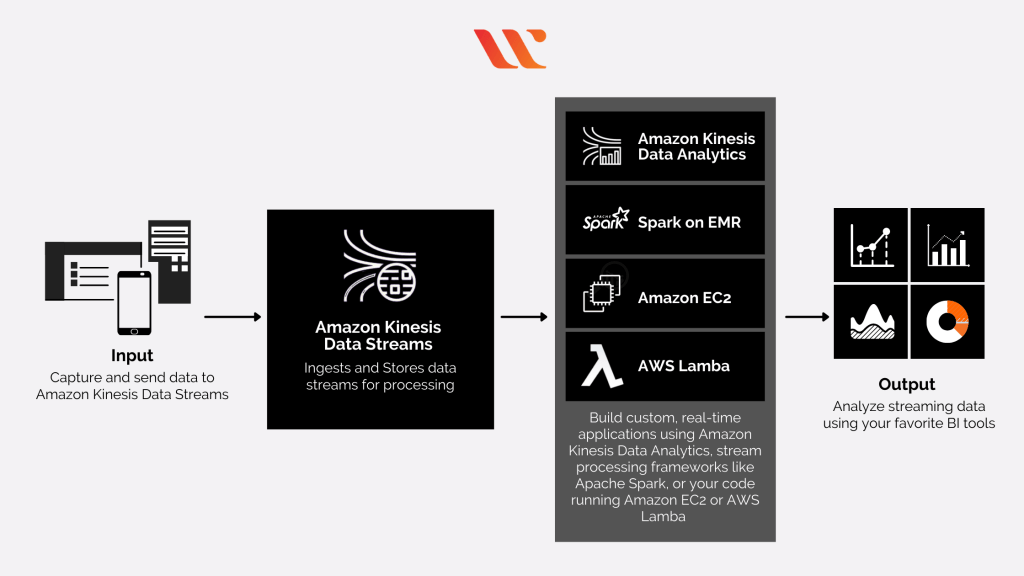

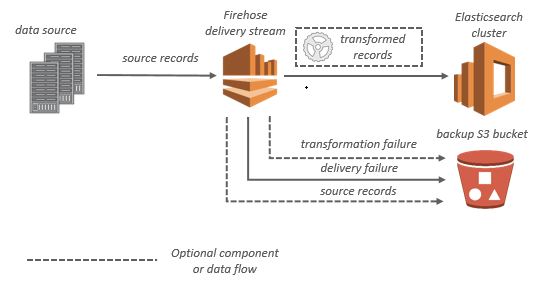
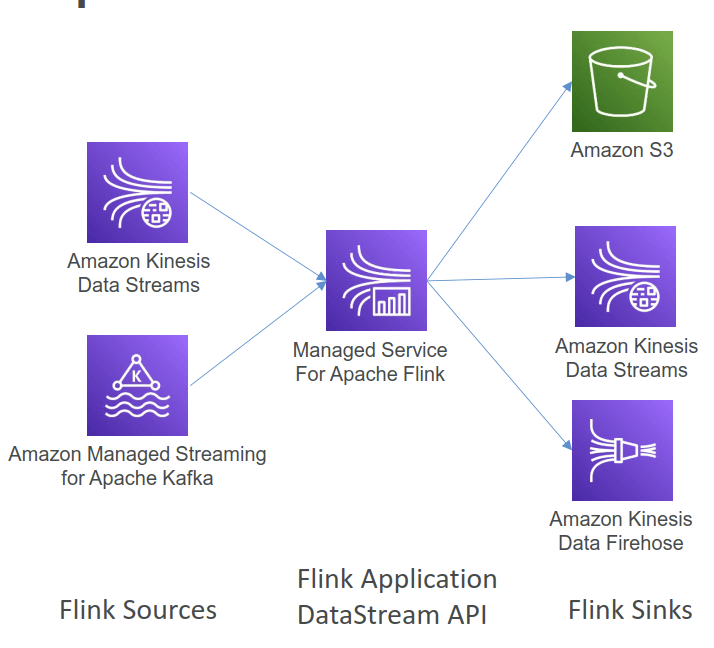
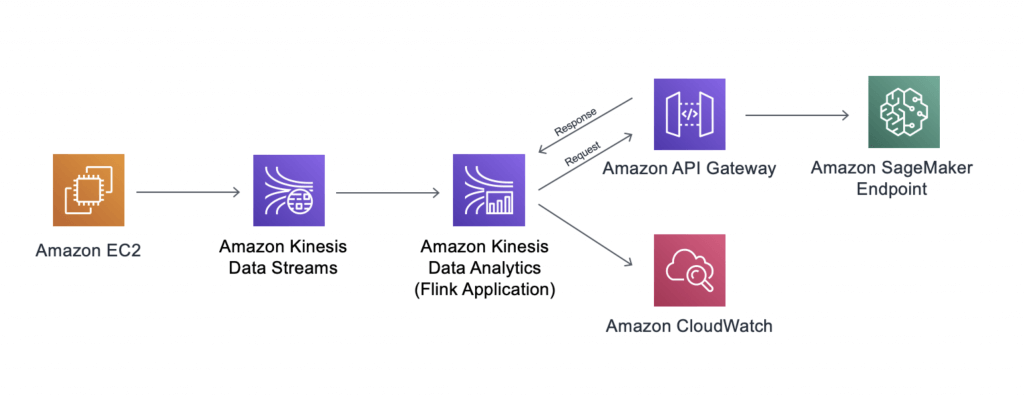
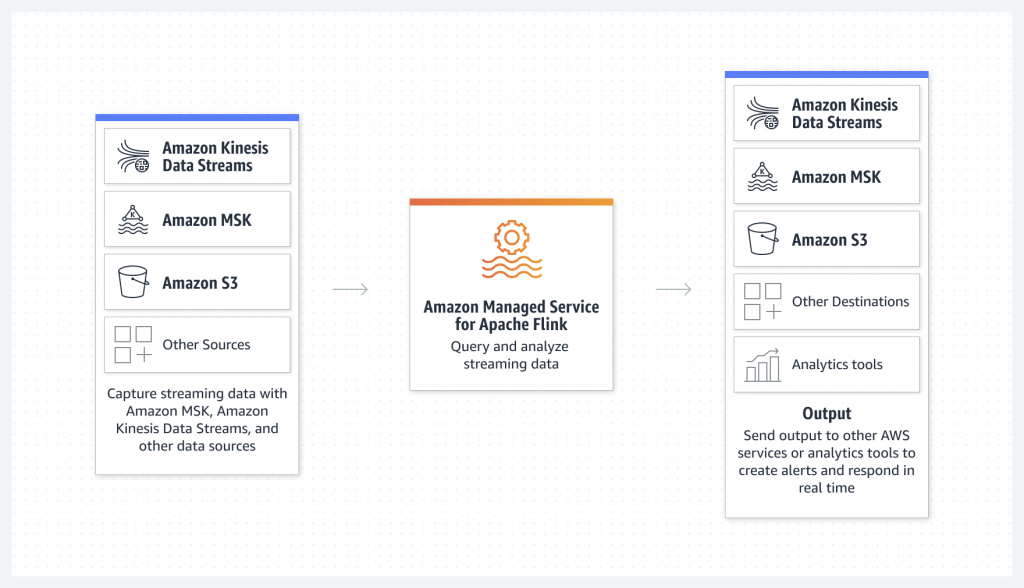
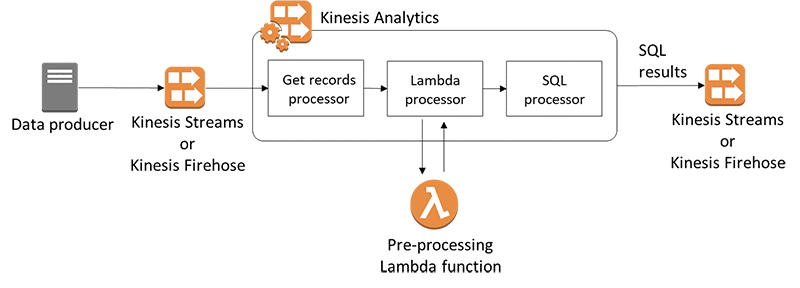
Amazon Kinesis Data Analytics
- aka Amazon Managed Service for Apache Flink
- Apache Flink is an open-source distributed processing engine for stateful computations over data streams. It provides a high-performance runtime and a powerful stream processing API that supports stateful computations, event-time processing, and accurate fault-tolerance guarantees.
- real-time data transformations, filtering, and enrichment
- Flink does not read from Amazon Data Firehose
- AWS Apache Flink clusters
- EC2 instances
- Apache Flink runtime
- Apache ZooKeeper
- Serverless
- Common cases
- Streaming ETL
- Continuous metric generation
- Responsive analytics
- building a real-time anomaly detection system for click-through rates
- with “RANDOM_CUT_FOREST”
- Use IAM permissions to access streaming source and destination(s)
- Schema discovery
- [ML] real-time ETL / ML algorithms on streams
Kinesis Video Stream
- Video playback capability
- Keep data for 1 hour to 10 years
- [ML] real-time video stream to create ML applications
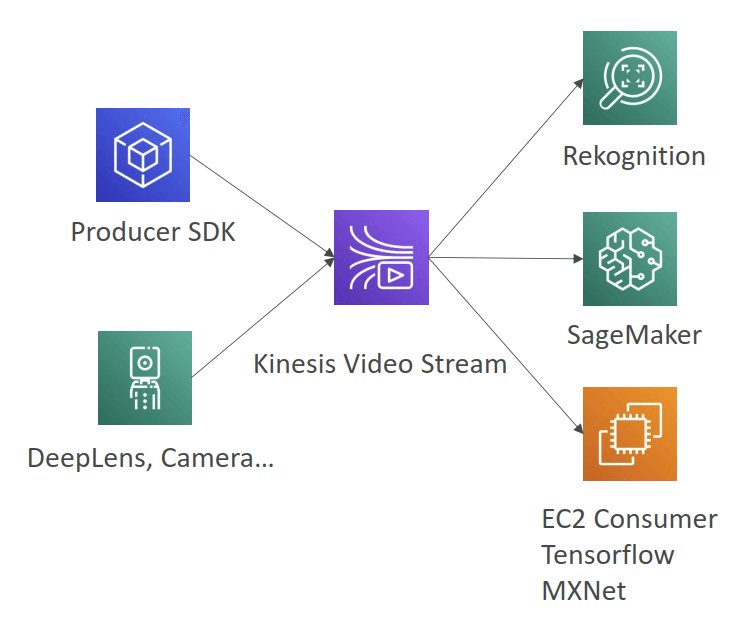
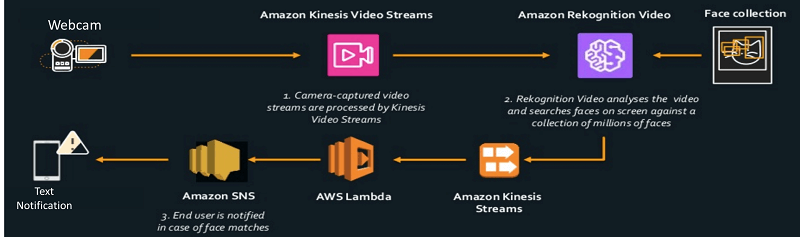
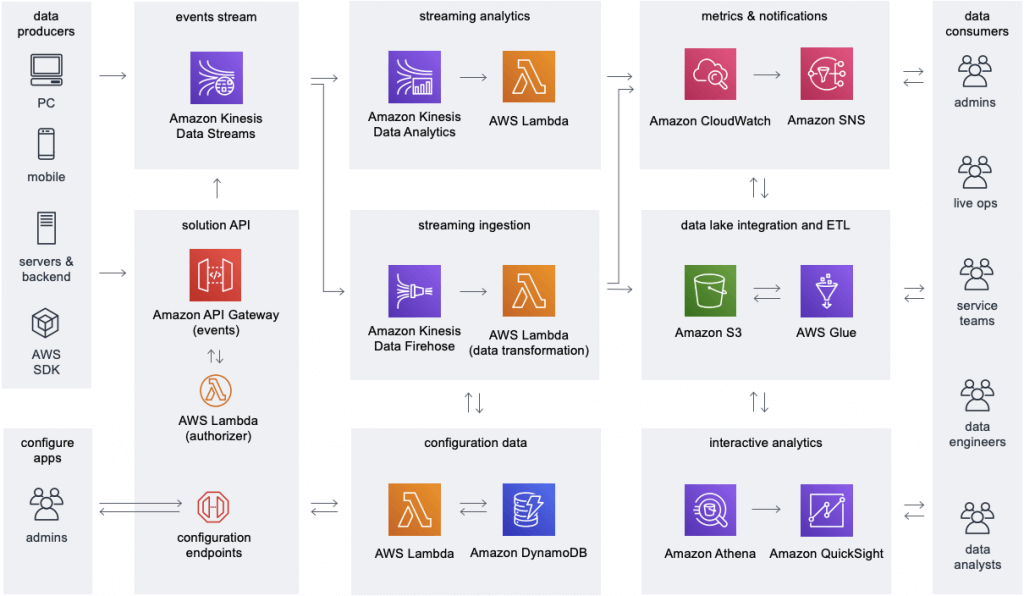
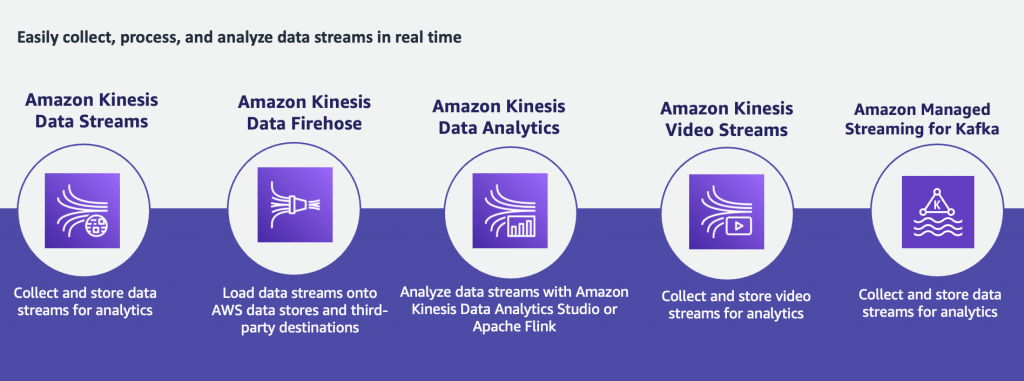
| Data Streams | Data Firehose | Data Analytics (Amazon Managed Service for Apache Flink) | Video Streams | |
| Short definition | Scalable and durable real-time data streaming service. | Capture, transform, and deliver streaming data into data lakes, data stores, and analytics services. | Transform and analyze streaming data in real time with Apache Flink. | Stream video from connected devices to AWS for analytics, machine learning, playback, and other processing. |
| Data sources | Any data source (servers, mobile devices, IoT devices, etc) that can call the Kinesis API to send data. | Any data source (servers, mobile devices, IoT devices, etc) that can call the Kinesis API to send data. | Amazon MSK, Amazon Kinesis Data Streams, servers, mobile devices, IoT devices, etc. | Any streaming device that supports Kinesis Video Streams SDK. |
| Data consumers | Kinesis Data Analytics, Amazon EMR, Amazon EC2, AWS Lambda | Amazon S3, Amazon Redshift, Amazon Elasticsearch Service, generic HTTP endpoints, Datadog, New Relic, MongoDB, and Splunk | Analysis results can be sent to another Kinesis stream, a Firehose stream, or a Lambda function | Amazon Rekognition, Amazon SageMaker, MxNet, TensorFlow, HLS-based media playback, custom media processing application |
| Use cases | – Log and event data collection – Real-time analytics – Mobile data capture – Gaming data feed | – IoT Analytics – Clickstream Analytics – Log Analytics – Security monitoring | – Streaming ETL – Real-time analytics – Stateful event processing | – Smart technologies – Video-related AI/ML – Video processing |
=== DATA (DATABASE) ===
Amazon Keyspaces DB
- a scalable, highly available, and managed Apache Cassandra–compatible database service
| Apache Cassandra | MongoDB | |
| Data model | Cassandra uses a wide-column data model more closely related to relational databases. | MongoDB moves completely away from the relational model by storing data as documents. |
| Basic storage unit | Sorted string tables. | Serialized JSON documents. |
| Indexing | Cassandra supports secondary indexes and SASI to index by column or columns. | MongoDB indexes at a collection level and field level and offers multiple indexing options. |
| Query language | Cassandra uses CQL. | MongoDB uses MQL. |
| Concurrency | Cassandra achieves concurrency with row-level atomicity and turntable consistency. | MongoDB uses MVCC and document-level locking to ensure concurrency. |
| Availability | Cassandra has multiple master nodes, node partitioning, and key replication to offer high availability. | MongoDB uses a single primary node and multiple replica nodes. Combined with sharding, MongoDB provides high availability and scalability. |
| Partitioning | Consistent hashing algorithm, less control to users. | Users define sharding keys and have more control over partitioning. |
| AWS | AWS Keyspaces | AWS DynomoDB |
With AWS Lake Formation, organizations can build, secure, and manage data lakes on Amazon S3 more efficiently. Lake Formation simplifies data ingestion, cleaning, cataloging, and secure access control, ensuring that only authorized users can access specific datasets. It integrates with AWS Glue, allowing schema inference and metadata management while enabling fine-grained access control for multiple teams.
A data lake is a centralized repository that allows structured and unstructured data storage at any scale. With Lake Formation, you can easily define access policies and use attribute-based access control (ABAC), ensuring governance and security while still enabling different analytics workloads.
Amazon Athena is an interactive query service that allows querying of data stored in Amazon S3 using standard SQL, eliminating the need for complex ETL processes. It works seamlessly with AWS Lake Formation, ensuring governed queries based on predefined permissions.
Amazon Redshift is a data warehouse service used for running fast, simple, and cost-effective SQL queries to analyze data. This is not suitable as a data repository for unprocessed data
=== DATA PROCESSING (ETL) ===
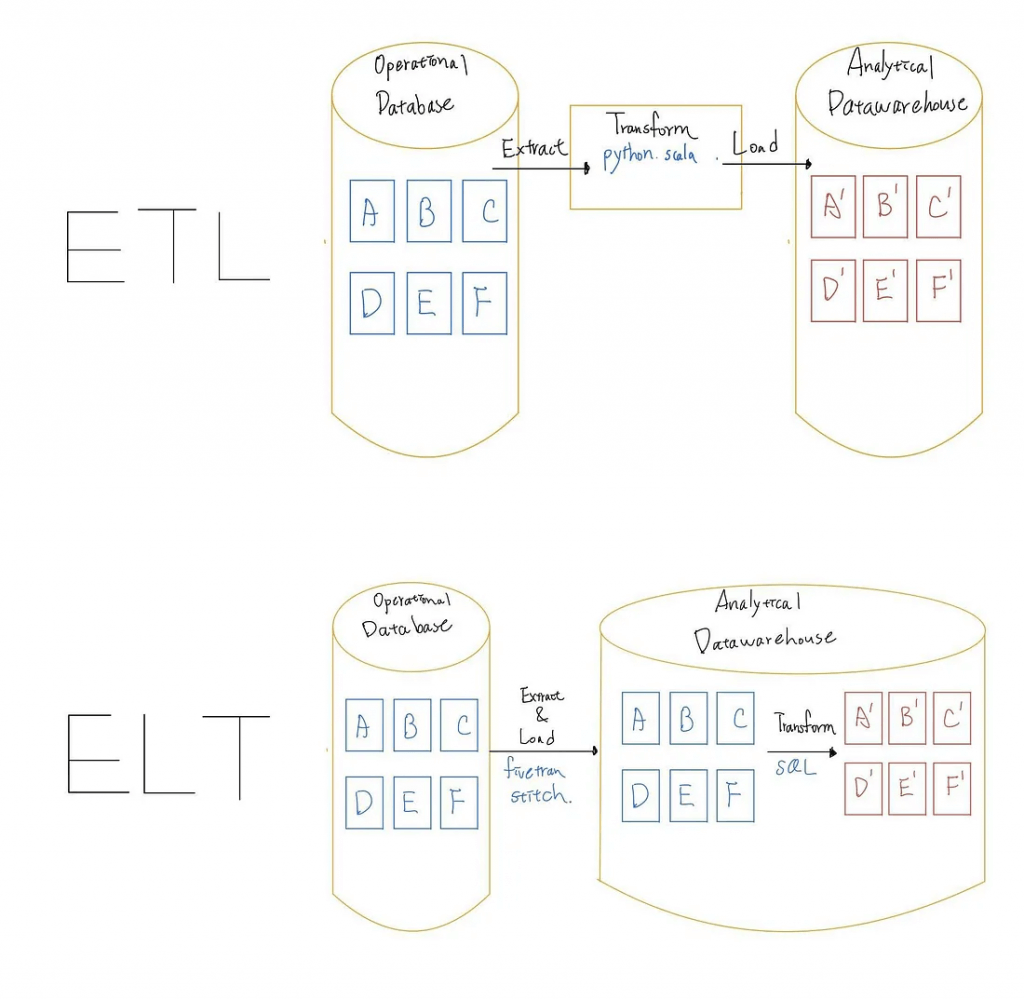
Data Build Tool (dbt)
- an open-source command line tool that helps analysts and engineers transform data in their warehouse more effectively
- Dbt enables analytics engineers to transform data in their warehouses by writing select statements, and turns these select statements into tables and views. Dbt does the transformation (T) in extract, load, transform (ELT) processes – it does not extract or load data, but is designed to be performant at transforming data already inside of a warehouse.
- Dbt uses YAML files to declare properties.
seedis a type of reference table used in dbt for static or infrequently changed data, like for example country codes or lookup tables), which are CSV based and typically stored in a seeds folder.
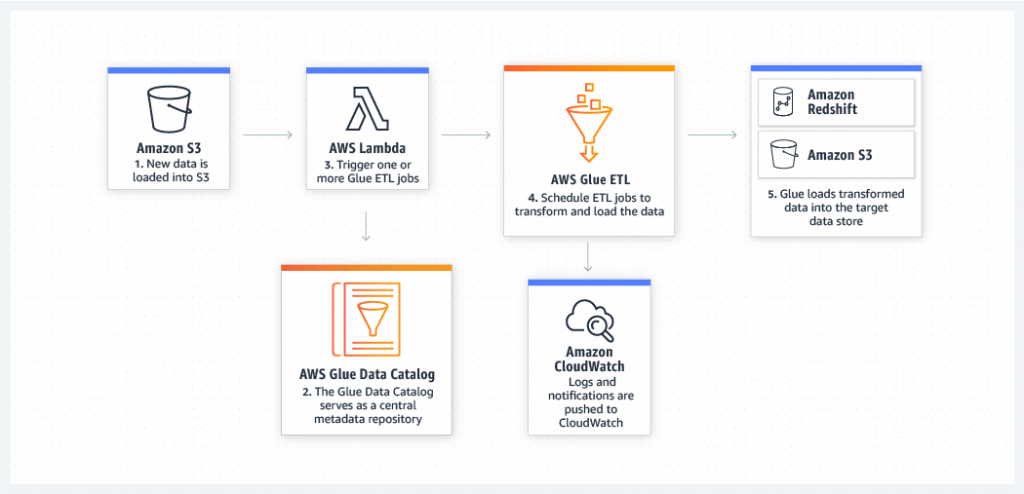
Glue ETL
- Extract, Transform, Load
- primarily used for batch data processing and not real-time data ingestion and processing
- Transform data, Clean Data, Enrich Data (before doing analysis)
- Bundled Transformations
- DropFields, DropNullFields – remove (null) fields
- Filter – specify a function to filter records
- Join – to enrich data
- Map – add fields, delete fields, perform external lookups
- Machine Learning Transformations
- FindMatches ML: identify duplicate or matching records in your dataset, even when the records do not have a common unique identifier and no fields match exactly.
- Apache Spark transformations (example: K-Means)
- Bundled Transformations
- Jobs are run on a serverless Spark platform
- Glue Scheduler to schedule the jobs
- Glue Triggers to automate job runs based on “events”
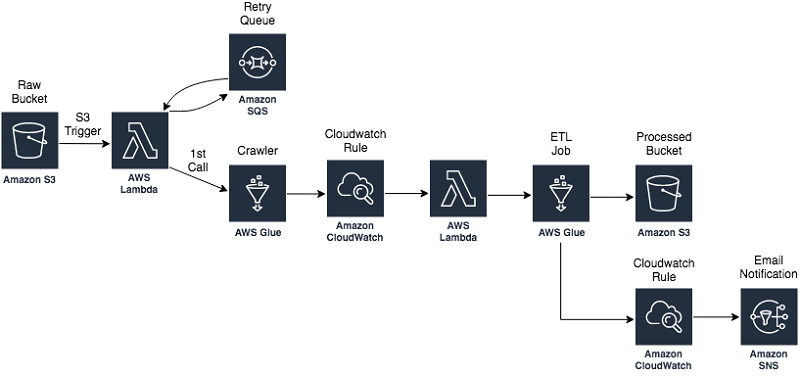
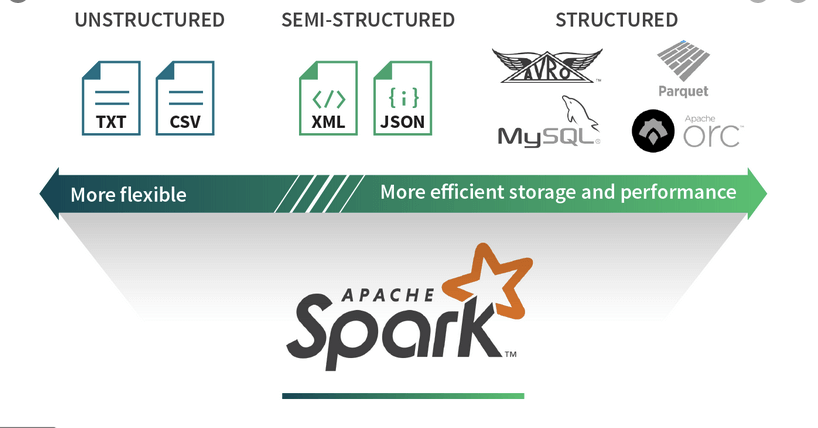
| Format | Definition | Property | Usage |
| CSV | Unstructured | minimal, row-based | no good for large-scale data |
| XML | Semi-structured | not row- nor column-based | no good for large-scale data |
| JSON | Semi-structured | not row- nor column-based | |
| JSON Lines (JSONL) | Structured | performance-oriented, row-based | large datasets (streaming, event data) |
| Parquet | Structured (columnar) | performance-oriented, column-based | large datasets (analytical queries), with data compression and encoding algorithms |
| Avro-RecordIO | Structured | performance-oriented, row-based | large datasets (streaming, event data) |
| grokLog | Structured | ||
| Ion | Structured | ||
| ORC | Structured | performance-oriented, column-based |
| Feature | Avro | Parquet |
| Storage Format | Row-based (stores entire records sequentially) | Columnar-based (stores data by columns) |
| Best For | Streaming, event data, schema evolution | Analytical queries, big data analytics |
| Read Performance | Slower for analytics since entire rows must be read | Faster for analytics as only required columns are read |
| Write Performance | Faster – appends entire rows quickly | Slower – columnar storage requires additional processing |
| Query Efficiency | Inefficient for analytical queries due to row-based structure | Highly efficient for analytical queries since only required columns are scanned |
| File Size | Generally larger due to row-based storage | Smaller file sizes due to better compression techniques |
| Use Cases | Event-driven architectures, Kafka messaging systems, log storage | Data lakes, data warehouses, ETL processes, analytical workloads |
| Processing Frameworks | Works well with Apache Kafka, Hadoop, Spark | Optimized for Apache Spark, Hive, Presto, Snowflake |
| Support for Nested Data | Supports nested data, but requires schema definition | Optimized for nested structures, making it better suited for hierarchical data |
| Interoperability | Widely used in streaming platforms | Preferred for big data processing and analytical workloads |
| Primary Industry Adoption | Streaming platforms, logging, real-time pipelines | Data warehousing, analytics, business intelligence |
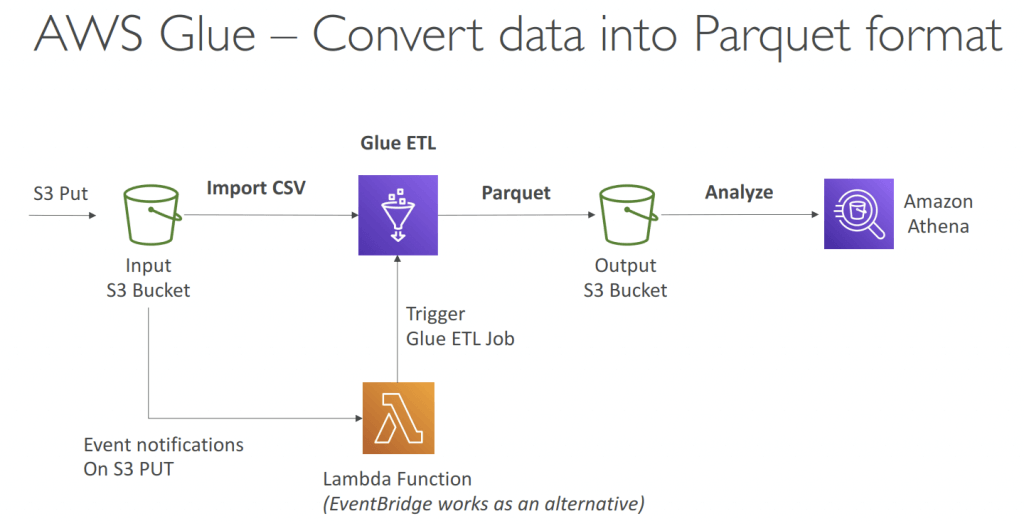
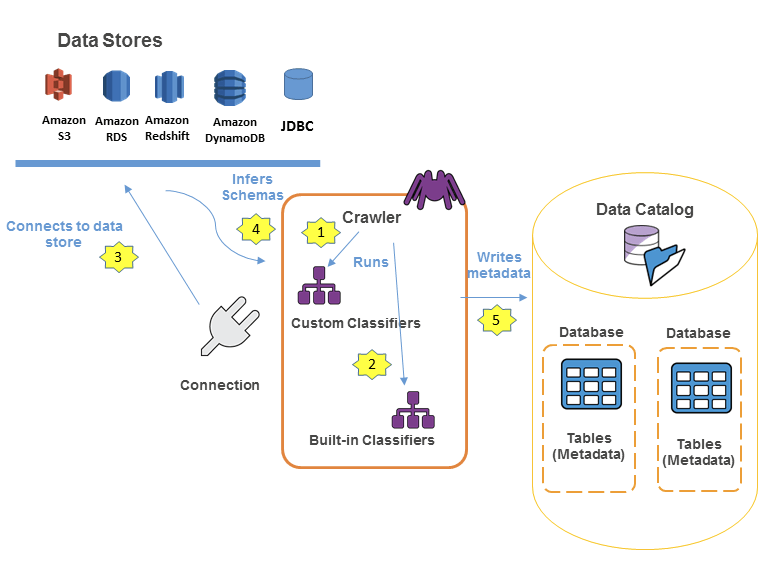
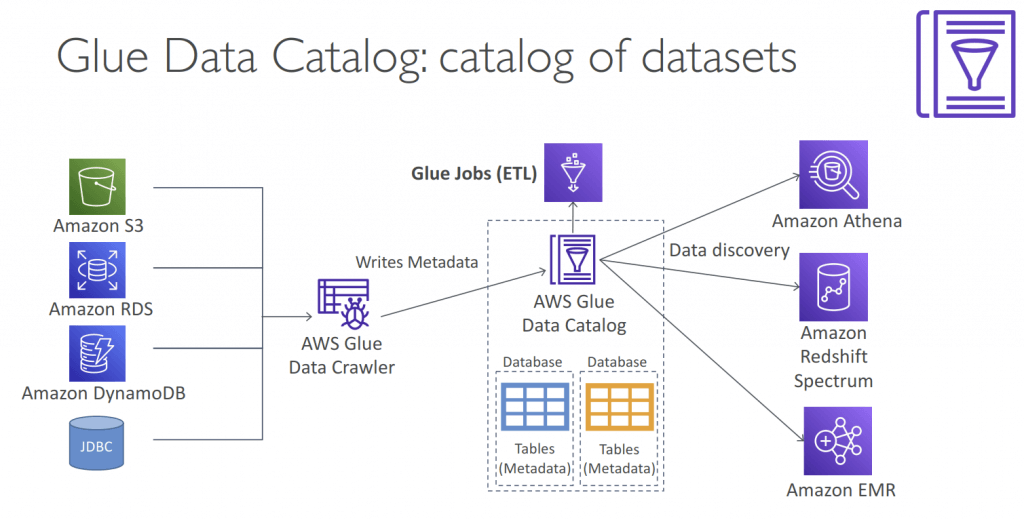
Glue Data Catalog
- Metadata repository for all your tables
- Automated Schema Inference
- Schemas are versioned
- Integrates with Athena or Redshift Spectrum (schema & data discovery)
- Glue Crawlers can help build the Glue Data Catalog
- Works JSON, Parquet, CSV, relational store
- Crawlers work for: S3, Amazon Redshift, Amazon RDS
- Run the Crawler on a Schedule or On Demand
- Need an IAM role / credentials to access the data stores
- Glue crawler will extract partitions based on how your S3 data is organized
AWS Glue DataBrew
- Allows you to clean and normalize data without writing any code
- clean and normalize data using pre-built transformation
- Reduces ML and analytics data preparation time by up to 80%
- features
- Transformations, such as filtering rows, replacing values, splitting and combining columns; or applying NLP to split sentences into phrases.
- Data Formats and Data Sources
- Job and Scheduling
- Security
- Integration
- Components
- Project
- Dataset
- Recipe
- Job
- Data Lineage
- Data Profile
- AWS Glue DataBrew is a visual data preparation tool that makes it easy for data analysts and data scientists to clean and normalize data to prepare it for analytics and machine learning. It offers a wide selection of pre-built transformations to automate data preparation tasks, all without the need to write any code. You can automate filtering anomalies, converting data to standard formats, and correcting invalid values, and other tasks. After your data is ready, you can immediately use it for analytics and machine learning projects.
Since AWS Glue DataBrew is serverless, you do not need to provision or manage any infrastructure to use it. With AWS Glue DataBrew, you can easily and quickly create and execute data preparation recipes through a visual interface. The service automatically scales up or down based on the size and complexity of your data, so you only pay for the resources you use.
AWS Glue Streaming
- (built on Apache Spark Structured Streaming): compatible with Kinesis Data Streaming, Kafka, MSK (managed Kafka)
- Use cases
- Near-real-time data processing
- Convert CSV to Apache Parquet
- Fraud detection
- Social media analytics
- Internet of Things (IoT) analytics
- Clickstream analysis
- Log monitoring and analysis
- Recommendation systems
- Near-real-time data processing
- When
- If you are already using AWS Glue or Spark for batch processing.
- If you require a unified service or product to handle batch, streaming, and event-driven workloads
- extremely large streaming data volumes and complex transformations
- If you prefer a visual approach to building streaming jobs
- for near-real-time use cases where there are stringent SLAs (Service Level Agreements) greater than 10 seconds.
- If you are building a transactional data lake using Apache Iceberg, Apache Hudi, or Delta Lake
- When needing to ingest streaming data for a variety of data targets
- Data sources
- Amazon Kinesis Data Stream
- Amazon MSK (Managed Streaming for Apache Kafka)
- Self-managed Apache Kafka
- Data Target
- Data targets supported by AWS Glue Data Catalog
- Amazon S3
- Amazon Redshift
- MySQL
- PostgreSQL
- Oracle
- Microsoft SQL Server
- Snowflake
- Any database that can be connected using JDBC
- Apache Iceberg, Delta and Apache Hudi
- AWS Glue Marketplace connectors
AWS Glue Job Bookmarks
- prevent re-processing old data
- AWS Glue tracks data that has already been processed during a previous run of an ETL job by persisting state information from the job run. This persisted state information is called a job bookmark. Job bookmarks help AWS Glue maintain state information and prevent the reprocessing of old data. With job bookmarks, you can process new data when rerunning on a scheduled interval. A job bookmark is composed of the states for various elements of jobs, such as sources, transformations, and targets. For example, your ETL job might read new partitions in an Amazon S3 file. AWS Glue tracks which partitions the job has processed successfully to prevent duplicate processing and duplicate data in the job’s target data store.
| AWS Glue version | Amazon S3 source formats |
|---|---|
| Version 0.9 | JSON, CSV, Apache Avro, XML |
| Version 1.0 and later | JSON, CSV, Apache Avro, XML, Parquet, ORC |
=== DATA PROCESSING (EMR) ===
Amazon Elastic MapReduce (EMR)
- a managed cluster platform that simplifies running big data frameworks, such as Apache Hadoop and Apache Spark, on AWS to process and analyze vast amounts of data. Using these frameworks and related open-source projects, you can process data for analytics purposes and business intelligence workloads. Amazon EMR also lets you transform and move large amounts of data into and out of other AWS data stores and databases, such as Amazon Simple Storage Service (Amazon S3) and Amazon DynamoDB.
- Data Processing (Transform)
- Dara Analytics
- Data Storage
- Managed Hadoop framework on EC2 instances
- Hadoop is an open source framework based on Java that manages the storage and processing of large amounts of data for applications.
- Hadoop Distributed File System (HDFS): a distributed file system in which individual Hadoop nodes operate on data that resides in their local storage
- Yet Another Resource Negotiator (YARN): a resource-management platform responsible for managing compute resources in clusters and using them to schedule users’ applications. It performs scheduling and resource allocation across the Hadoop system.
- MapReduce: a programming model for large-scale data processing. In the MapReduce model, subsets of larger datasets and instructions for processing the subsets are dispatched to multiple different nodes, where each subset is processed by a node in parallel with other processing jobs. After processing the results, individual subsets are combined into a smaller, more manageable dataset.
- Hadoop Common: the libraries and utilities
- Hadoop is an open source framework based on Java that manages the storage and processing of large amounts of data for applications.
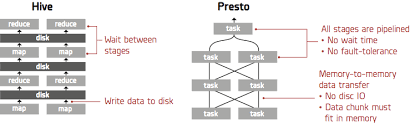
- Includes Spark, HBase, Presto, Flink, Hive & more
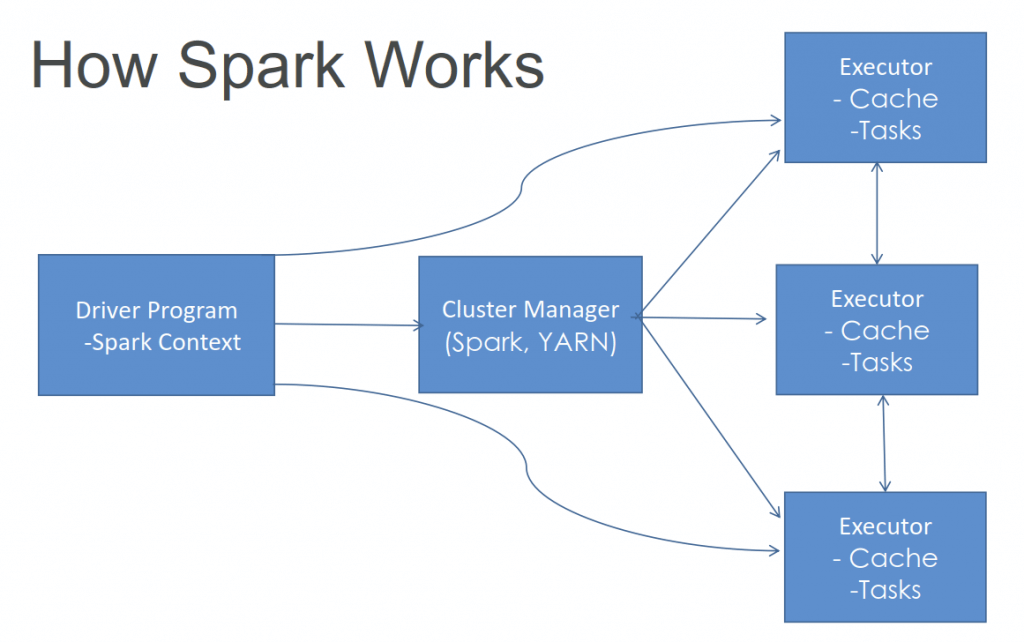
- Apache Spark: uses in-memory caching and optimized query execution for fast analytic queries against data of any size. Its foundational concept is a read-only set of data distributed over a cluster of machines, which is called a resilient distributed dataset (RDD).
- Apache HBase: An open source non-relational distributed database often paired with Hadoop
- Presto: a distributed and open-source SQL query engine that is used to run interactive analytical queries. It can handle the query of any size ranging from gigabytes to petabytes.
- Flink: a stream processing framework that can also handle batch processing. It is designed for real-time analytics and can process data as it arrives.
- Apache Hive: A data warehouse that allows programmers to work with data in HDFS using a query language called HiveQL, which is similar to SQL
- Zeppelin: Web-based notebook that enables data-driven, interactive data analytics and collaborative documents with SQL, Scala, Python, R and more.
- Apache Ranger: an open-source framework designed to enable, monitor and manage comprehensive data security across the Hadoop platform

| Based On | Apache Hadoop | Apache Spark | Apache Flink |
|---|---|---|---|
| Data Processing | Hadoop is mainly designed for batch processing which is very efficient in processing large datasets. | It supports batch processing as well as stream processing. | It supports both batch and stream processing. Flink also provides the single run-time for batch and stream processing. |
| Stream Engine | It takes the complete data-set as input at once and produces the output. | Process data streams in micro-batches. | The true streaming engine uses streams for workload: streaming, micro-batch, SQL, batch. |
| Data Flow | Data Flow does not contain any loops. supports linear data flow. | Spark supports cyclic data flow and represents it as (DAG) direct acyclic graph. | Flink uses a controlled cyclic dependency graph in run time. which efficiently manifest ML algorithms. |
| Computation Model | Hadoop Map-Reduce supports the batch-oriented model. | It supports the micro-batching computational model. | Flink supports a continuous operator-based streaming model. |
| Performance | Slower than Spark and Flink. | More than Hadoop lesser than Flink. | Performance is highest among these three. |
| Memory management | Configurable Memory management supports both dynamically or statically management. | The Latest release of spark has automatic memory management. | Supports automatic memory management |
| Fault tolerance | Highly fault-tolerant using a replication mechanism. | Spark RDD provides fault tolerance through lineage. | Fault tolerance is based on Chandy-Lamport distributed snapshots results in high throughput. |
| Scalability | Highly scalable and can be scaled up to tens of thousands of nodes. | Highly scalable. | It is also highly scalable. |
| Iterative Processing | Does not support Iterative Processing. | supports Iterative Processing. | supports Iterative Processing and iterate data with the help of its streaming architecture. |
| Supported Languages | Java, C, C++, Python, Perl, groovy, Ruby, etc. | Java, Python, R, Scala. | Java, Python, R, Scala. |
| Cost | Uses commodity hardware which is less expensive | Needed lots of RAM so the cost is relatively high. | Apache Flink also needed lots of RAM so the cost is relatively high. |
| Abstraction | No Abstraction in Map-Reduce. | Spark RDD abstraction | Flink supports Dataset abstraction for batch and DataStreams |
| SQL support | Users can run SQL queries using Apache Hive. | Users can run SQL queries using Spark-SQL. It also supports Hive for SQL. | Flink supports Table-API which are similar to SQL expression. Apache foundation is panning to add SQL interface in its future release. |
| Caching | Map-Reduce can not cache data. | It can cache data in memory | Flink can also cache data in memory |
| Hardware Requirements | Runs well on less expensive commodity hardware. | It also needed high-level hardware. | Apache Flink also needs High-level Hardware |
| Machine Learning | Apache Mahout is used for ML. | Spark is so powerful in implementing ML algorithms with its own ML libraries. | FlinkML library of Flink is used for ML implementation. |
| High Availability | Configurable in High Availability Mode. | Configurable in High Availability Mode. | Configurable in High Availability Mode. |
| Amazon S3 connector | Provides Support for Amazon S3 Connector. | Provides Support for Amazon S3 Connector. | Provides Support for Amazon S3 Connector. |
| Backpressure Handing | Hadoop handles back-pressure through Manual Configuration. | Spark also handles back-pressure through Manual Configuration. | Apache Flink handles back-pressure Implicitly through System Architecture |
- An EMR Cluster
- Master node: manages the cluster
- Single EC2 instance
- Core node: Hosts HDFS data and runs tasks
- Can be scaled up & down, but with some risk
- Task node: Runs tasks, does not host data
- No risk of data loss when removing
- Good use of spot instances
- Master node: manages the cluster
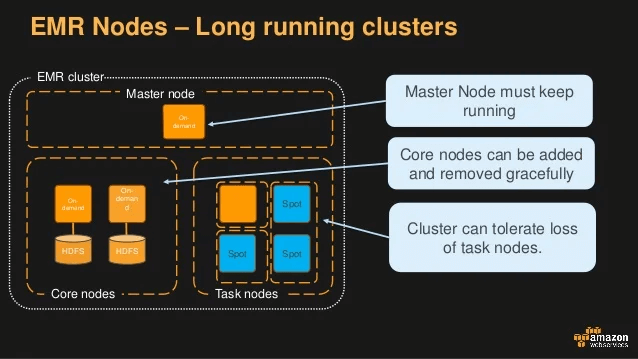
- EMR Usage
- Transient vs Long-Running Clusters
- Can spin up task nodes using Spot instances for temporary capacity
- Can use reserved instances on long-running clusters to save $
- Connect directly to master to run jobs
- Submit ordered steps via the console
- Serverless
- Transient vs Long-Running Clusters
- AWS Integration
- Amazon EC2 for the instances that comprise the nodes in the cluster
- Amazon VPC to configure the virtual network in which you launch your instances
- Amazon S3 to store input and output data
- Amazon CloudWatch to monitor cluster performance and configure alarms
- AWS IAM to configure permissions
- AWS CloudTrail to audit requests made to the service
- AWS Data Pipeline to schedule and start your clusters
- EMR Storage
- HDFS
- EMR File System (EMRFS) : access S3 as if it were HDFS
- [End-of-Support] EMRFS Consistent View – Optional for S3 consistency; uses DynamoDB to track consistency
- Local file system
- EBS for HDFS
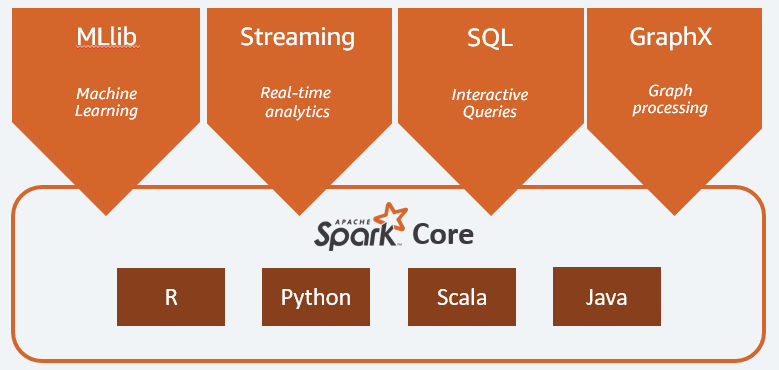
- Apache Spark
- Can work with Hadoop
- Spark MLLib
- Classification: logistic regression, naïve Bayes
- Regression
- Decision trees
- Recommendation engine (ALS)
- Clustering (K-Means)
- LDA (topic modeling)
- ML workflow utilities (pipelines, feature transformation, persistence)
- SVD, PCA, statistics
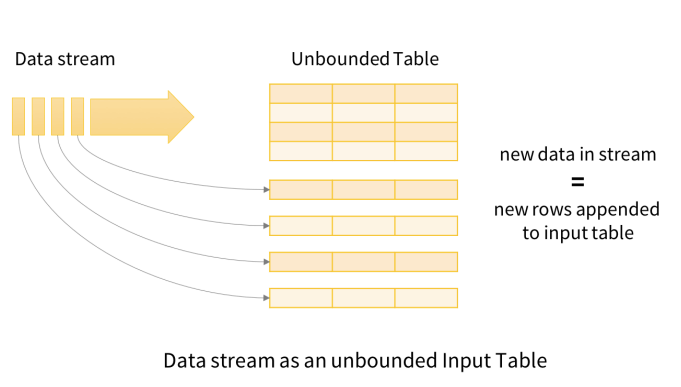
- Spark Structured Streaming
- Data stream as an unbounded Input Table
- New data in stream = new rows appended to input table
- EMR Notebook
- Notebooks backed up to S3
- Provision clusters from the notebook!
- Hosted inside a VPC
- Accessed only via AWS console
- EMR Security
- IAM policies
- Kerberos (a computer-network authentication protocol that works on the basis of tickets to allow nodes communicating over a non-secure network to prove their identity to one another in a secure manner.)
- SSH
- IAM roles
- Security configurations may be specified for Lake Formation
- Native integration with Apache Ranger
- EMR: Choosing Instance Types
- Master node:
- m4.large if < 50 nodes, m4.xlarge if > 50 nodes
- Core & task nodes:
- m4.large is usually good
- If cluster waits a lot on external dependencies (i.e. a web crawler), t2.medium
- Improved performance: m4.xlarge
- Computation-intensive applications: high CPU instances
- Database, memory-caching applications: high memory instances
- Network / CPU-intensive (NLP, ML) – cluster computer instances
- Accelerated Computing / AI – GPU instances (g3, g4, p2, p3)
- Spot instances
- Good choice for task nodes
- Only use on core & master if you’re testing or very cost-sensitive; you’re risking partial
data loss
- Master node:
| Aspect | Flink | Spark | Kafka |
|---|---|---|---|
| Type | Hybrid (batch and stream) | Hybrid (batch and stream) | Stream-only |
| Support for 3rd party systems | Multiple source and sink | Yes (Kafka, HDFS, Cassandra, etc.) | Tightly coupled with Kafka (Kafka Connect) |
| Stateful | Yes (RocksDB) | Yes (with checkpointing) | Yes (with Kafka Streams, RocksDB) |
| Complex event processing | Yes (native support) | Yes (with Spark Structured Streaming) | No (developer needs to handle) |
| Streaming window | Tumbling, Sliding, Session, Count | Time-based and count-based | Tumbling, Hopping/Sliding, Session |
| Data Processing | Batch/Stream (native) | Batch/Stream (micro Batch) | Stream-only |
| Iterations | Supports iterative algorithms natively | Supports iterative algorithms with micro-batches | No |
| SQL | Table, SQL API | Spark SQL | Supports SQL queries on streaming data with Kafka SQL API (KSQL) |
| Optimization | Auto (data flow graph and the available resources) | Manual (directed acyclic graph (DAG) and the available resources) | No native support |
| State Backend | Memory, file system, RocksDB or custom backends | Memory, file system, HDFS or custom backends | Memory, file system, RocksDB or custom backends |
| Language | Java, Scala, Python and SQL APIs | Java, Scala, Python, R, C#, F# and SQL APIs | Java, Scala and SQL APIs |
| Geo-distribution | Flink Stateful Functions API | No native support | Kafka MirrorMaker tool |
| Latency | Streaming: very low latency (milliseconds) | Micro-batching: near real-time latency (seconds) | Log-based: very low latency (milliseconds) |
| Data model | True streaming with bounded and unbounded data sets | Micro-batching with RDDs and DataFrames | Log-based streaming |
| Processing engine | One unified engine for batch and stream processing | Separate engines for batch (Spark Core) and stream processing (Spark Streaming) | Stream processing only |
| Delivery guarantees | Exactly-once for both batch and stream processing | Exactly-once for batch processing, at-least-once for stream processing | At-least-once |
| Throughput | High throughput due to pipelined execution and in-memory caching | High throughput due to in-memory caching and parallel processing | High throughput due to log compaction and compression |
| State management | Rich support for stateful operations with various state backends and time semantics | Limited support for stateful operations with mapWithState and updateStateByKey functions | No native support for stateful operations, rely on external databases or Kafka Streams API |
| Machine learning support | Yes (Flink ML library) | Yes (Spark MLlib library) | No (use external libraries like TensorFlow or H2O) |
| Architecture | True streaming engine that treats batch as a special case of streaming with bounded data. Uses a streaming dataflow model that allows for more optimization than Spark’s DAG model. | Batch engine that supports streaming as micro-batching (processing small batches of data at regular intervals). Uses a DAG model that divides the computation into stages and tasks. | Stream engine that acts as both a message broker and a stream processor. Uses a log model that stores and processes records as an ordered sequence of events. |
| Delivery Guarantees | Supports exactly-once processing semantics by using checkpoints and state snapshots. Also supports at-least-once and at-most-once semantics. | Supports at-least-once processing semantics by using checkpoints and write-ahead logs. Can achieve exactly-once semantics for some output sinks by using idempotent writes or transactions. | Supports exactly-once processing semantics by using transactions and idempotent producers. Also supports at-least-once and at-most-once semantics. |
| Performance | Achieves high performance and low latency by using in-memory processing, pipelined execution, incremental checkpoints, network buffers, and operator chaining. Also supports batch and iterative processing modes for higher throughput. | Achieves high performance and low latency by using in-memory processing, lazy evaluation, RDD caching, and code generation. However, micro-batching introduces some latency overhead compared to true streaming engines. | Achieves high performance and low latency by using log compaction, zero-copy transfer, batch compression, and client-side caching. However, Kafka does not support complex stream processing operations natively. |
=== DATA PROCESSING (MISC) ===
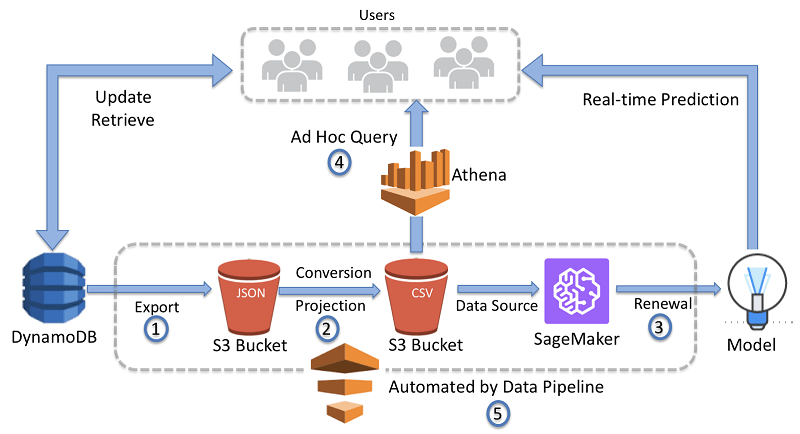
AWS Data Pipeline
- Destinations include S3, RDS, DynamoDB, Redshift and EMR
- Manages task dependencies
- Retries and notifies on failures
- Data sources may be on-premises

AWS Batch
- Run batch jobs via Docker images
- Dynamic provisioning of the instances (EC2 & Spot Instances)
- serverless
- Schedule Batch Jobs using CloudWatch Events
- Orchestrate Batch Jobs using AWS Step Functions
- AWS Batch is not a valid destination of S3 Events
AWS Batch enables developers, scientists, and engineers to easily and efficiently run hundreds of thousands of batch computing jobs on AWS. With AWS Batch, there is no need to install and manage batch computing software or server clusters that you use to run your jobs, allowing you to focus on analyzing results and solving problems.
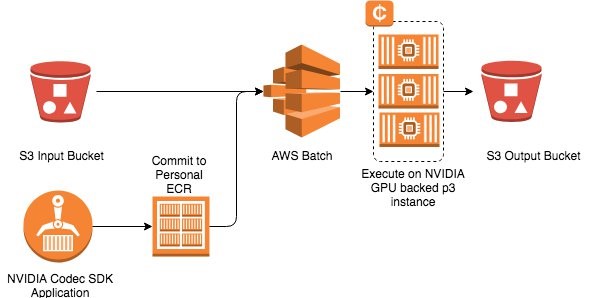
Jobs submitted to AWS Batch are queued and executed based on the assigned order of preference. AWS Batch dynamically provisions the optimal quantity and type of computing resources based on the requirements of the batch jobs submitted. It also offers an automated retry mechanism where you can continuously run a job even in the event of a failure (e.g., instance termination when Amazon EC2 reclaims Spot instances, internal AWS service error/outage).

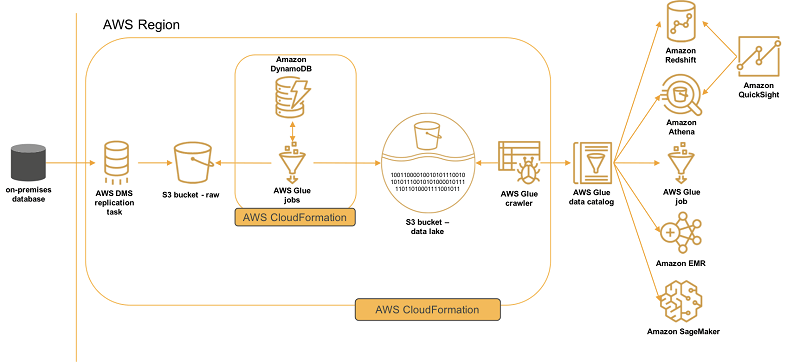
AWS DMS – Database Migration Service
- a cloud service that makes it easy to migrate EXISTING relational databases, data warehouses, NoSQL databases, and other types of data stores
- you can perform one-time migrations, and you can replicate ongoing changes to keep sources and targets in sync
- Continuous Data Replication using CDC (change data capture)
- introduce latency and potential data consistency issues
- You must create an EC2 instance to perform the replication tasks
- Homogeneous migrations: ex Oracle to Oracle, MySQL to Aurora MySQL
- Heterogeneous migrations: ex Microsoft SQL Server to Aurora
- You can migrate data to Amazon S3 using AWS DMS from any of the supported database sources. When using Amazon S3 as a target in an AWS DMS task, both full load and change data capture (CDC) data is written to comma-separated value (.csv) format by default.
- The comma-separated value (.csv) format is the default storage format for Amazon S3 target objects. For more compact storage and faster queries, you can instead use Apache Parquet (.parquet) as the storage format. Apache Parquet is an open-source file storage format originally designed for Hadoop.


AWS DataSync
- on-premises -> AWS storage services
- A DataSync Agent is deployed as a VM and connects to your internal storage (NFS, SMB, HDFS)
- Encryption and data validation
- DataSync cannot transfer from Database
AWS Step Functions
- Use to design workflows
- Advanced Error Handling and Retry mechanism outside the (Lambda) code
- Audit of the history of workflows
- States
- Take State
- Wait State
- Fail State
- Ability to “Wait” for an arbitrary amount of time
- Max execution time of a State Machine is 1 year
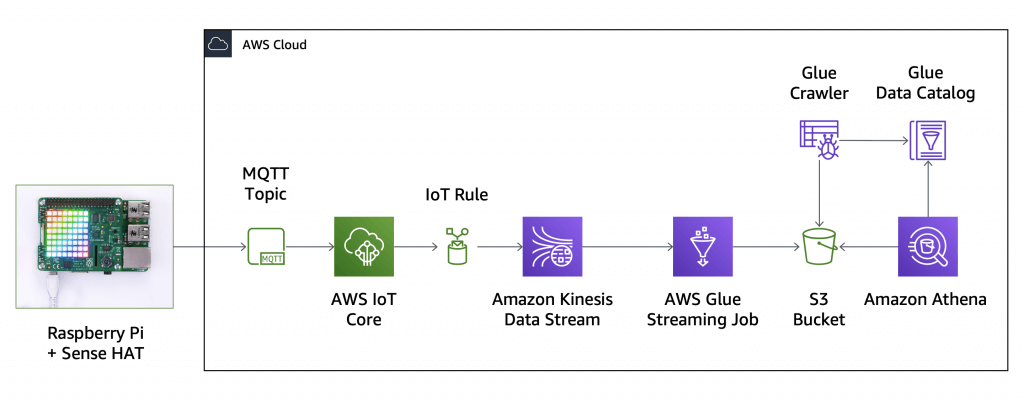
MQTT
- Standard messaging protocol, for IoT (Internet of Things)
- Think of it as how lots of sensor data might get transferred to your machine learning model
- The AWS IoT Device SDK can connect via MQTT
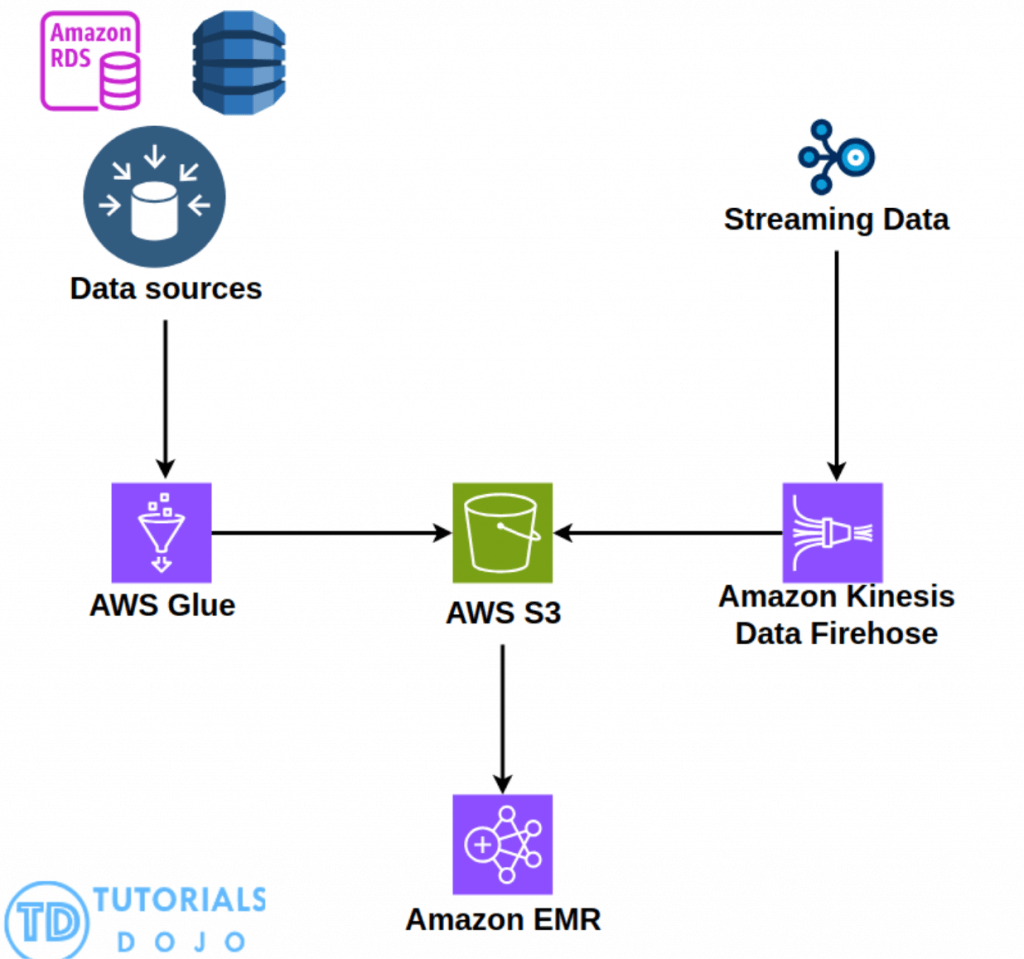
AWS Glue can be used to extract and combine data from various sources like Amazon RDS databases, Amazon DynamoDB, and other data stores, creating a unified dataset for training the machine learning model. This combined dataset can then be stored in Amazon S3, a cost-effective and scalable object storage service, making it accessible for both training and inference purposes. For analyzing large volumes of purchase history data, which is crucial for understanding customer behavior, the company can utilize Amazon EMR, a distributed computing framework that enables efficient processing of big data. Additionally, to incorporate real-time social media activity data into the model, Amazon Data Firehose can be employed to ingest, transform, and load this streaming data directly into Amazon S3, where it can be combined with the other datasets. By leveraging these AWS services in tandem, the e-commerce company can streamline the entire data processing pipeline, from data ingestion and storage to analysis and model training, ultimately enhancing the accuracy and effectiveness of their customer churn prediction model.