=== TEXT ===
Amazon Comperehend
- Natural Language Processing and Text Analytics
- Input social media, emails, web pages, documents, transcripts, medical records
- Comprehend Medical
- tailored only for extracting medical information from unstructured text using natural language processing
- Comprehend Medical
- Extract key phrases, entities, sentiment, language, syntax, topics, and document classifications
- perfect for evaluating customer feedback
- Events detection
- PII Identification & Redaction
- Targeted sentiment (for specific entities)
- Compose
- Entities: Noun with Category, Confidence
- Key phrases: Noun
- Language
- Sentiment: Neutral, Positive, Negative, Mixed
- Syntax: Noun, Verb, Adposition, Adjustive, …
- can provide quick sentiment analysis results, it’s not focused on labeling the data for future use in training custom models (in large data set)
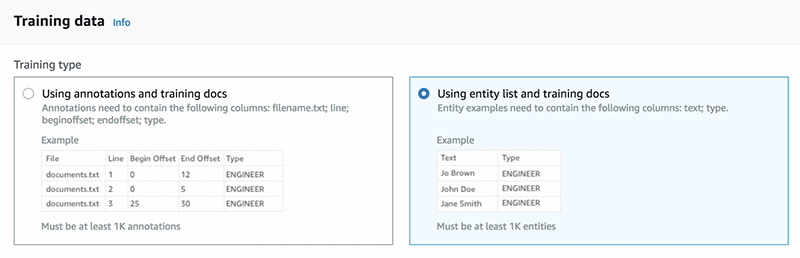
- Custom entity recognition
- Custom entity recognition extends the capability of Amazon Comprehend by helping you identify your specific new entity types that are not in the preset generic entity types. This means that you can analyze documents and extract entities like product codes or business-specific entities that fit your particular needs.
Amazon Translate
- Uses deep learning for translation
- Supports custom terminology
- In CSV or TMX format
- Appropriate for proper names, brand names, etc.
Amazon Transcribe
- Speech to text
- Input in FLAC, MP3, MP4, or WAV, in a specified language
- Streaming audio supported (HTTP/2 or WebSocket)
- Speaker Identification
- Specify number of speakers
- Channel Identification
- i.e., two callers could be transcribed separately
- Merging based on timing of “utterances”
- Automatic Language Identification
- Custom Vocabularies
- Vocabulary Lists (just a list of special words – names, acronyms)
- Vocabulary Tables (can include “SoundsLike”, “IPA”, and “DisplayAs”)
- Practices
- Call Analytics
- Medical
- Subtitling
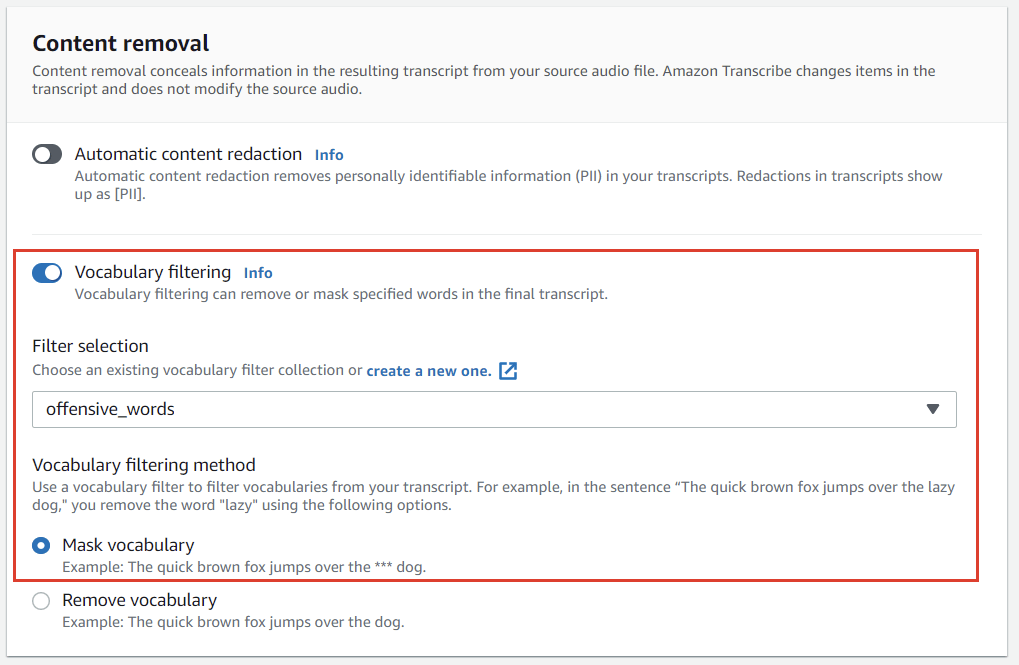
- Content Removal
- Automatic content redaction
- Personally Identifiable Information (PII)
- Vocabulary Filters
- Mask
- Remove
- Automatic content redaction
Amazon TextTract
- OCR with forms, fields, tables support
- detect typed and handwritten text in a variety of documents
- PDFs, Images
- For tasks like signature detection, Amazon Textract provides specific features to identify and validate signatures with confidence scores, making it a powerful solution for compliance workflows in industries like finance and healthcare.
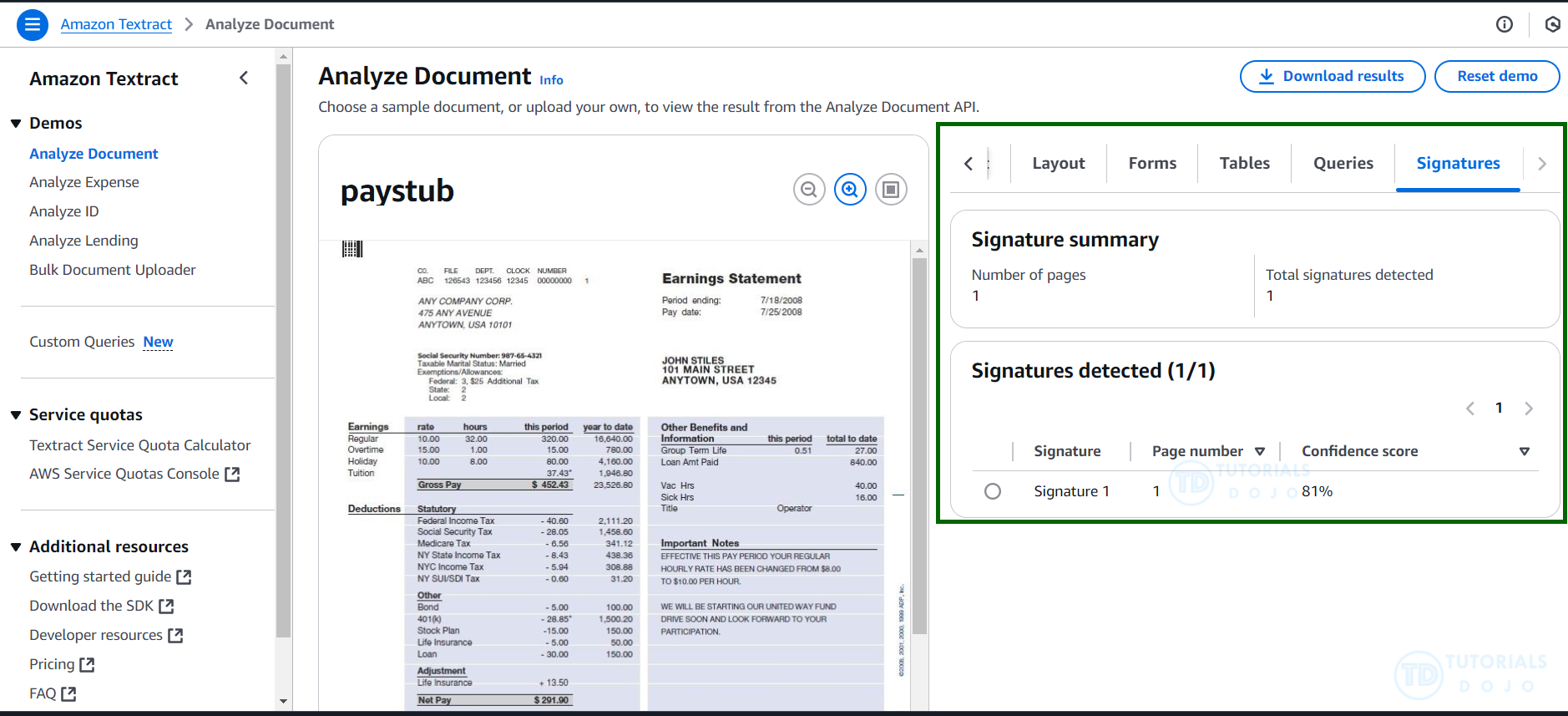
TheAnalyzeDocumentAPI is a synchronous API in Amazon Textract that processes single-page or multi-page documents. It enables detection of various features such as key-value pairs, tables, and more by leveraging theFeatureTypesparameter. This API is suitable for real-time processing and can provide detailed insights into the document structure and content.
TheFeatureTypesparameter specifies the features that Amazon Textract should analyze within a document. When set toSIGNATURES, the API is explicitly configured to detect handwritten or electronic signatures within the document. The API returns:
– Signature bounding boxes (location of the signature in the document).
– Confidence scores indicating the accuracy of the detection.
This feature directly addresses the requirement for signature detection in compliance workflows, automating the process of identifying signatures while ensuring accuracy and traceability. - Analyze the document using the
StartDocumentAnalysisAPI with theFeatureTypesparameter set toSIGNATURESto process signature detection is incorrect as it would only return a job ID for the request since it’s an asynchrounous operation. To get the confidence score, you would need to make another API call with the job ID usingGetDocumentAnalysis. This introduces additional complexity and extra API calls, which is unnecessary for the requirement of getting the confidence score directly in the response. - Analyze the document using the
GetDocumentTextDetectionAPI to extract text from documents and validate signatures with a confidence score is incorrect because this API is primarily designed for text extraction, not signature detection. While you could theoretically validate signatures by extracting text, this approach is not tailored to detect and extract signatures directly, making it less suitable for the given requirements.
Amazon Kendra
- Enterprise search with natural language
- a search service that uses natural language processing and advanced ML algorithms to return specific answers to search questions from your data
- to extract information from documents
- Combines data from file systems, SharePoint, intranet, sharing services (JDBC, S3) into one searchable repository
- ML-powered (of course) – uses thumbs up / down feedback
- Relevance tuning – boost strength of document freshness, view counts, etc.
| Use Cases | Amazon Kendra | Elasticsearch | OpenSearch |
| Improve search experiences | Yes | Yes | Yes |
| Enhance customer interactions and satisfaction | Yes | Yes | Yes |
| Natural Language Processing (NLP) | Yes | Yes, but with the help of additional configurations or integrations. | Yes, but it requires external NLP tools. |
| Full-text search | Yes | Yes | Yes |
| Enterprise search | Yes | Yes, but it requires extra configuration. | Yes, but it needs extra configuration. |
| Distributed search | Yes | Yes | Yes |
| Piped query language search | No | Yes | Yes |
| Integrate search functionality into your SaaS applications | Yes | Yes | Yes |
| Implement multi-tenancy and get rid of fraud and risk | Yes | Yes | Yes |
| Semantic search | Yes | Yes | Yes |
| Application search | Yes | Yes | Yes |
| E-commerce search | No | Yes | Yes |
| Log and event data monitoring | No | Yes | Yes |
| Aggregate and analyze large datasets | No | Yes | Yes |
| Security Information and Event Management (SIEM) | No | Yes | Yes |
Amazon OpenSearch
- AWS version of ElasticSearch
- search and analytics suite used for a broad set of use cases like real-time application monitoring, log analytics, and website search
- can be utilized as a vector database, which is ideal for storing and retrieving high-dimensional vectors needed for RAG applications. This enables the chatbot to efficiently search and retrieve relevant document vectors that contain the necessary operational guidelines.
- Lexical search: the search engine compares the words in the search query to the words in the documents, matching word for word.
- Searching through technical documentation or legal texts
- Finding specific product codes or part numbers in a database
- Locating exact phrases in a large corpus of text
- Semantic search: uses an ML model to encode text or other media (such as images and videos) from the source documents as a dense vector in a high-dimensional vector space. It similarly codes the query as a vector and then uses a distance metric to find nearby vectors in the multi-dimensional space to find matches. The algorithm for finding nearby vectors is called k-nearest neighbors (k-NN). Semantic search doesn’t match individual query terms—it finds documents whose vector embedding is near the query’s embedding in the vector space and therefore semantically similar to the query. This allows you to return highly relevant items even if they don’t contain any of the words that were in the query.
- Powering digital assistants and chatbots
- Enhancing e-commerce product discovery
- Improving academic research by finding conceptually related papers
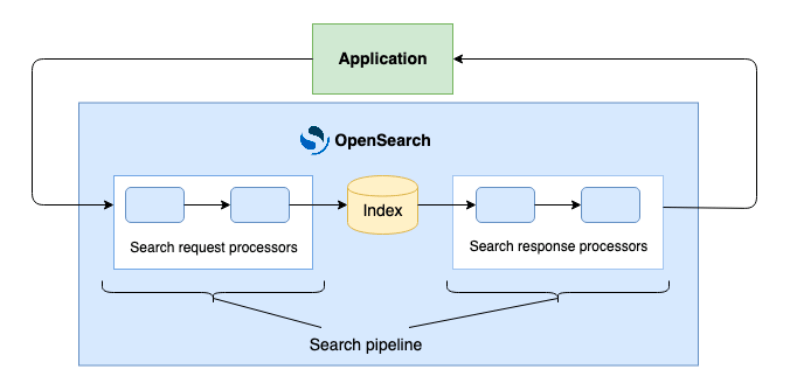
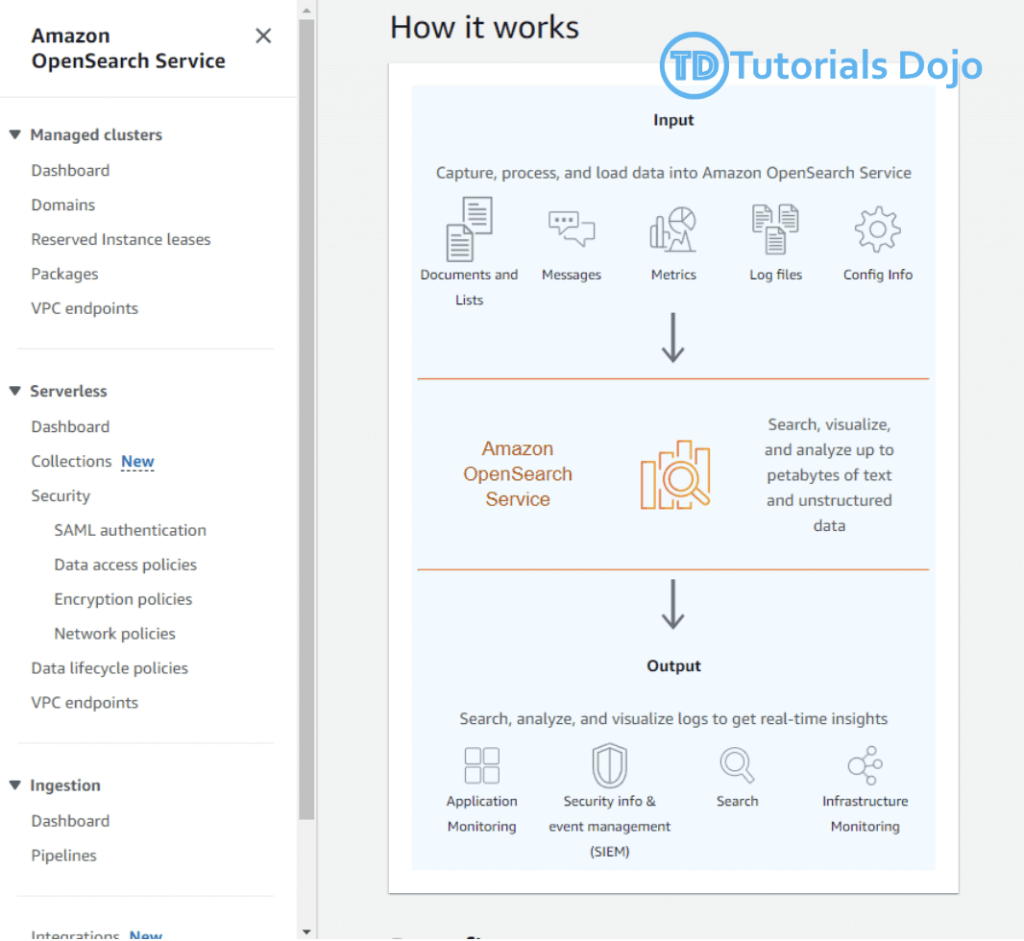
| Aspect | Lexical Search | Semantic Search |
|---|---|---|
| Precision | High for exact word matches | Lower for specific word matches, higher for conceptual matches |
| Flexibility | In its more common form (also known as “full-text search”), it supports wildcards, morphology, and fuzzy matching | Very high, understands context and intent |
| Speed | Generally faster, less computation | Requires more computational power |
| Context Awareness | Limited to literal and morphological matches | High, understands meaning and relationships |
| Result Transparency | Easy to understand match criteria | More complex, based on advanced models |
| Result Count | Exact result count available | Often limited to top results, full count may be unclear |
| Ideal Use Cases | Structured queries, known terminology | Open-ended questions, concept exploration |
=== SPEECH ===
Amazon Polly
- a service that turns text into lifelike speech, allowing you to create applications that talk, and build entirely new categories of speech-enabled products. Polly’s Text-to-Speech (TTS) service uses advanced deep learning technologies to synthesize natural sounding human speech.
- Neural Text-To-Speech
- Lexicons
- Customize pronunciation of specific words & phrases
- Example: “World Wide Web Consortium” instead of “W3C”
- SSML
- Speech Synthesis Markup Language
- Gives control over emphasis, phonetic pronunciation, breathing, whispering, speech rate, pitch, pauses.
- <emphasis>, <break>, <lang>, <phoneme>, <sub>
- Speech Marks
- metadata can encode when sentence / word starts and ends in the audio stream
- Useful for lip-synching animation, “viseme”
=== VISUAL ===
Amazon Rekognition
- Computer vision
- Object and scene detection
- Image moderation
- Facial analysis
- Celebrity recognition <- sport player, speech guest
- Face comparison
- Text in image
- Video analysis (Amazon Rekognition Video)
- Objects / people / celebrities marked on timeline
- People Pathing
- helps identify inappropriate, unwanted, or offensive content
- The Nitty Gritty
- Images come from S3, or provide image bytes as part of request
- Facial recognition depends on good lighting, angle, visibility of eyes, resolution
- Video must come from Kinesis Video Streams
- H.264 encoded
- 5-30 FPS
- Favor resolution over framerate
- Can use with Lambda to trigger image analysis upon upload
- Can use Custom Labels

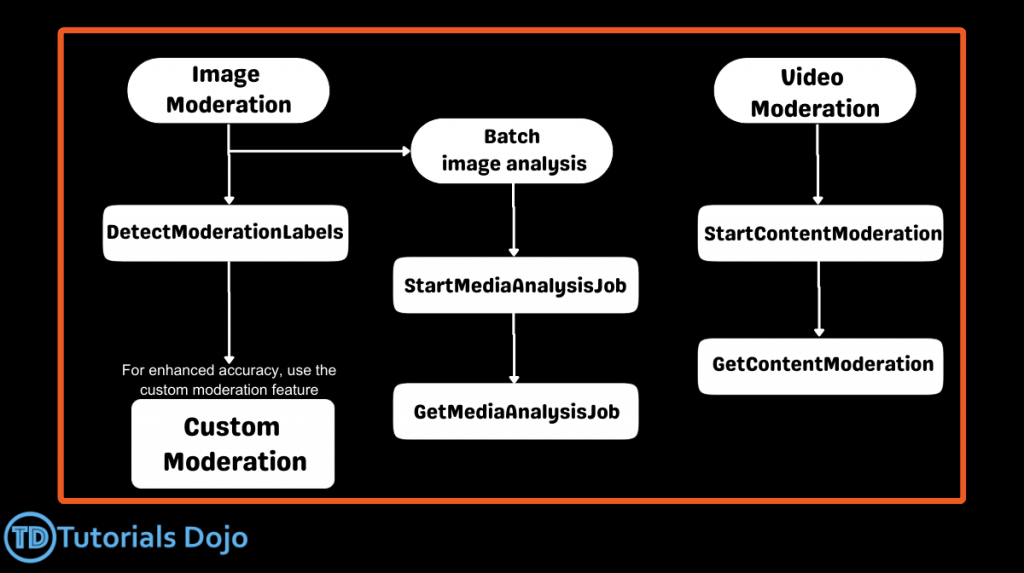
- store information about detected faces in server-side containers known as collections.
- Amazon Rekognition supports the IndexFaces operation. You can use this operation to detect faces in an image and persist information about facial features that are detected in a collection. This is an example of a storage-based API operation because the service persists information on the server.
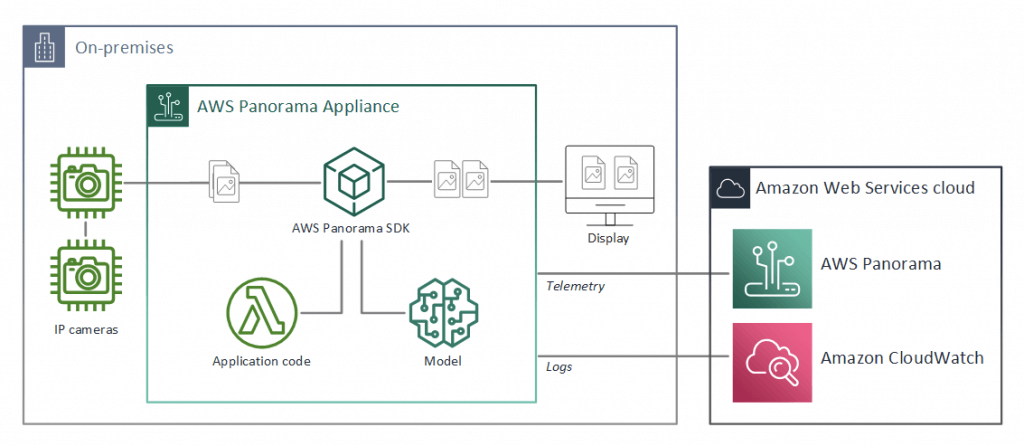
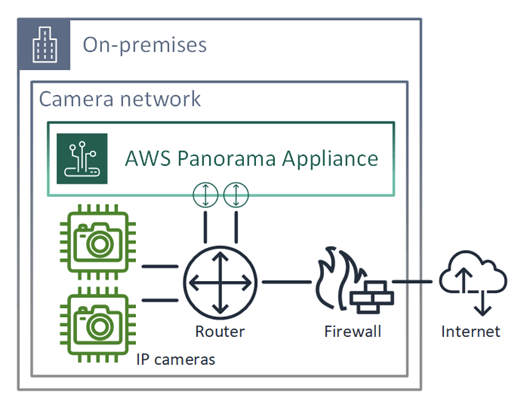
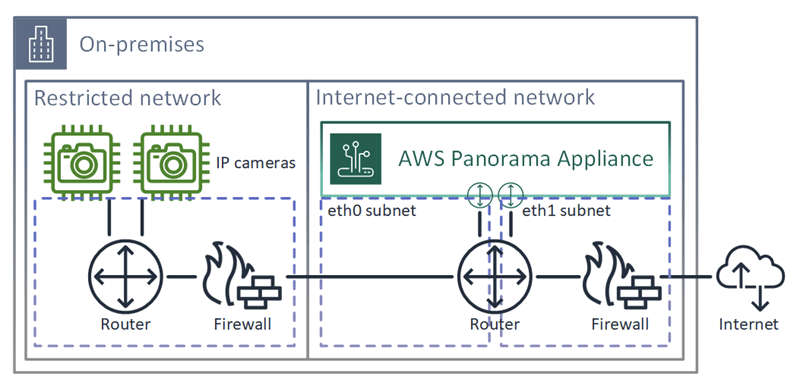
AWS Panorama
- Computer Vision (SDK) at the edge (ie, can be processed in local)
- Brings computer vision to your existing IP cameras
- Make predictions locally
- Process video feeds at the edge (helpful in limited internet bandwidth)
- AWS Panorama Appliance is the hardware that runs your applications.
- The software on the AWS Panorama Appliance connects to camera streams, sends frames of video to your application, and displays video output on an attached display
- Usecase
- Supply chain logistics
- Traffic management
- Detect manufacturing anomalies
=== OTHER : APPLICATIONS ===
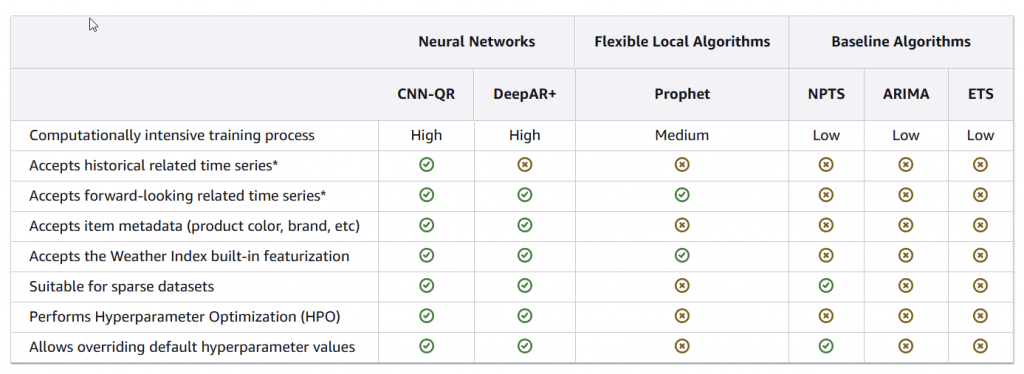
Amazon Forecast
- “AutoML” chooses best model for your time series data
- CNN-QR
- Convolutional Neural Network – Quantile Regression
- Best for large datasets with hundreds of time series
- Accepts related historical time series data & metadata
- DeepAR+
- Recurrent Neural Network
- Best for large datasets
- Accepts related forward-looking time series & metadata
- Prophet
- Additive model with non-linear trends and seasonality
- NPTS
- Non-Parametric Time Series
- Good for sparse data. Has variants for seasonal / climatological forecasts
- ARIMA
- Autoregressive Integrated Moving Average
- Commonly used for simple datasets (<100 time series)
- ETS
- Exponential Smoothing
- Commonly used for simple datasets (<100 time series)
- CNN-QR
- Works with any time series
- Price, promotions, economic performance, etc.
- Can combine with associated data to find relationships
- Inventory planning, financial planning, resource planning
- Based on “dataset groups,” “predictors,” and “forecasts.”
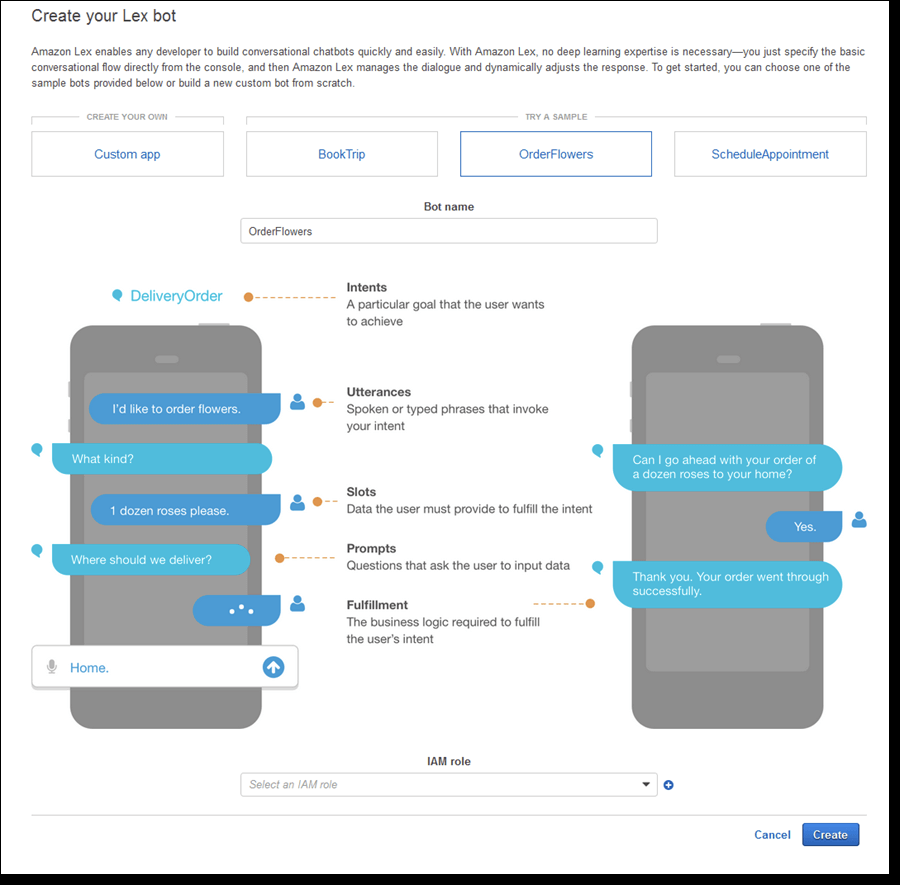
Amazon Lex
- a service for building conversational interfaces using voice and text. Powered by the same conversational engine as Alexa, Amazon Lex provides high quality speech recognition and language understanding capabilities, enabling addition of sophisticated, natural language ‘chatbots’ to new and existing applications.
- Natural-language chatbot engine
- A Bot is built around Intents
- Utterances invoke intents (“I want to order a pizza”)
- Lambda functions are invoked to fulfill the intent
- Slots specify extra information needed by the intent
- Pizza size, toppings, crust type, when to deliver, etc.
- Can deploy to AWS Mobile SDK, Facebook Messenger, Slack, and Twilio
- Lex Automated Chatbot Designer
- provide existing conversation transcripts
- Lex applies NLP & deep learning, removing overlaps & ambiguity
- Intents, user requests, phrases, values for slots are extracted
- Ensures intents are well defined and separated
- Integrates with Amazon Connect transcripts
Amazon Personalise
- Fully-managed recommender engine
- API access
- Feed in data (purchases, ratings, impressions, cart adds, catalog, user demographics etc.) via S3 or API integration
- provide an explicit schema in Avro format
- Javascript or SDK
- GetRecommendations
- Recommended products, content, etc.
- Similar items
- GetPersonalizedRanking
- Rank a list of items provided
- Allows editorial control / curation
- Features
- Real-time or batch recommendations
- Recommendations for new users and new items (the cold start
problem) - Contextual recommendations
- Device type, time, etc.
- Similar items
- Unstructured text input
- Intelligent user segmentation
- For marketing campaigns
- Business rules and filters
- Promotions
- Inject promoted content into recommendations
- Can find most relevant promoted content
- Trending Now
- Personalized Rankings
- Terminology
- Datasets
- Users, Items, Interactions
- Recipes
- USER_PERSONALIZATION
- PERSONALIZED_RANKING
- RELATED_ITEMS
- USER_SEGMENTATION
- Solutions
- Trains the model
- Optimizes for relevance as well as your additional objectives
- Video length, price, etc. – must be numeric
- Hyperparameter Optimization (HPO)
- Campaigns
- Deploys your “solution version”
- Deploys capacity for generating real-time
recommendations
- Datasets
- Hyperparameter
- User-Personalization, Personalized-Ranking
- hidden_dimension (HPO)
- bptt (back-propagation through time – RNN)
- recency_mask (weights recent events)
- min/max_user_history_length_percentile (filter out robots)
- exploration_weight 0-1, controls relevance
- exploration_item_age_cut_off – how far back in time you go
- Similar-items
- item_id_hidden_dim (HPO)
- item_metadata_hidden_dim (HPO with min & max range specified)
- User-Personalization, Personalized-Ranking
- Maintaining Relevance
- Use PutEvents operation to feed in real-time user behavior
- Retrain the model
- They call this a new solution version
- Updates every 2 hours by default
- Should do a full retrain (trainingMode=FULL) weekly
Amazon Connect
- an Amazon Web Services (AWS) public cloud customer contact center service
- Contact Lens
- For customer support call centers
- Ingests audio data from recorded calls
- Allows search on calls / chats
- Sentiment analysis
- Find “utterances” that correlate with successful calls
- Categorize calls automatically
- Measure talk speed and interruptions
- Theme detection: discovers emerging issues
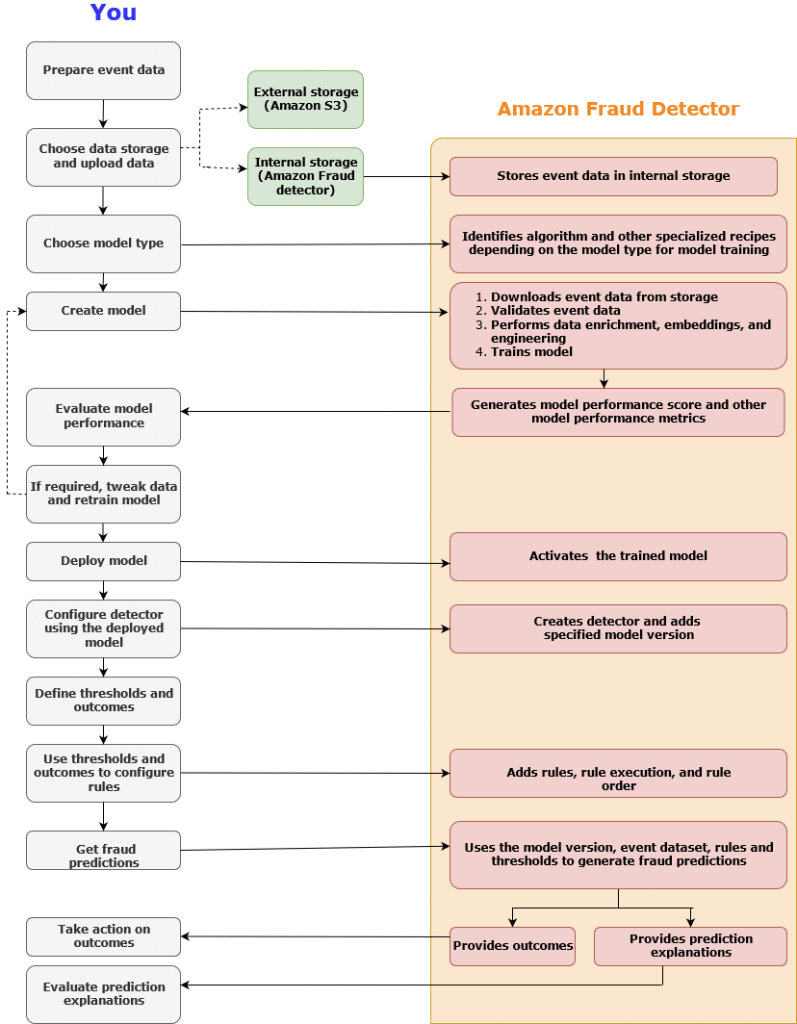
Amazon Fraud Detector
- Upload your own historical fraud data
- Builds custom models from a template you choose
- Exposes an API for your online application
- Assess risk from:
- New accounts
- Guest checkout
- “Try before you buy” abuse
- Online payments
Amazon Lookout
- Equipment, metrics, vision
- Detects abnormalities from sensor data automatically to detect equipment issues
- Monitors metrics from S3, RDS, Redshift, 3rd party SaaS apps
- Vision uses computer vision to detect defects in silicon wafers, circuit boards, etc.
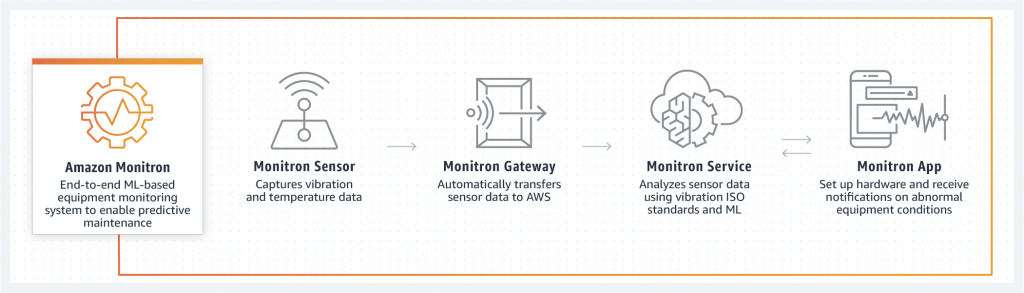
Amazon Monitron
- End to end system for monitoring industrial equipment & predictive maintenance
AWS Deep Composer
- AI-powered (music) keyboard
- Composes a melody into an entire song
- For educational purposes
AWS DeepRacer
- Reinforcement learning powered 1/18-scale race car
AWS DeepLens
- The AWS DeepLens camera is special-purpose hardware built to help developers learn and create deep learning models. It comes with sample projects focusing on computer vision applications such as face detection, object detection, etc.
- It is not meant to replace commercial security cameras that can be conveniently installed in different locations of a premise. It is not practical to use AWS DeepLens as a surveillance cam as it’s not designed to be mounted on walls, ceilings, posts, etc.
== OTHER : AWS SERVICES ===
TorchServe
- Model serving framework for PyTorch
- Part of the PyTorch open source project from Facebook (Meta?)
AWS Neuron
- SDK for ML inference specifically on AWS Inferentia chips
- EC2 Inf1 instance type
- Integrated with SageMaker or whatever else you want (deep learning AMI’s, containers, Tensorflow, PyTorch, MXNet)
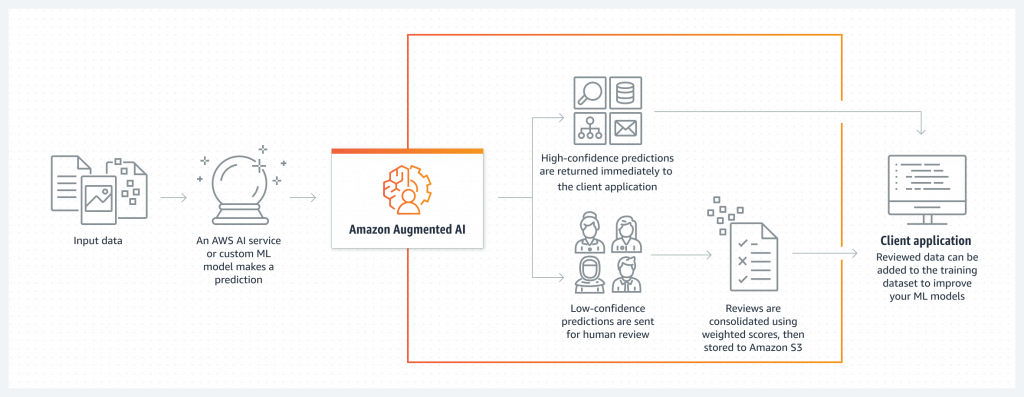
Amazon Augmented AI (A2I)
- Human review of ML predictions
- Builds workflows for reviewing low-confidence predictions
- Access the Mechanical Turk workforce or vendors
- Integrated into Amazon Textract and Rekognition
- Integrates with SageMaker
- Difference with SageMaker Ground Truth
- Focus:
- A2I: Focuses on integrating human review into the decision-making process of models post-prediction.
- Ground Truth: Focuses on creating high-quality labeled datasets during the training phase.
- Stage of ML Workflow:
- A2I: Used during the model deployment and prediction phase.
- Ground Truth: Used during the data preparation and model training phase.
- Automation:
- A2I: Adds human review when machine confidence is low.
- Ground Truth: Combines automated labeling with human corrections to produce accurate training data.
- Focus:
- Cases:
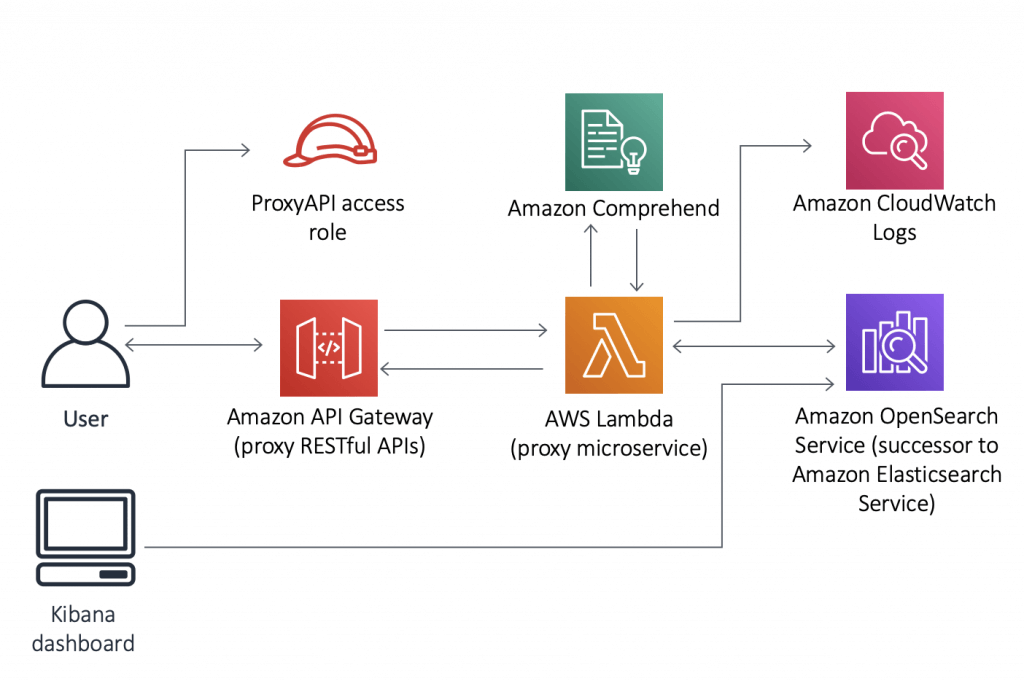
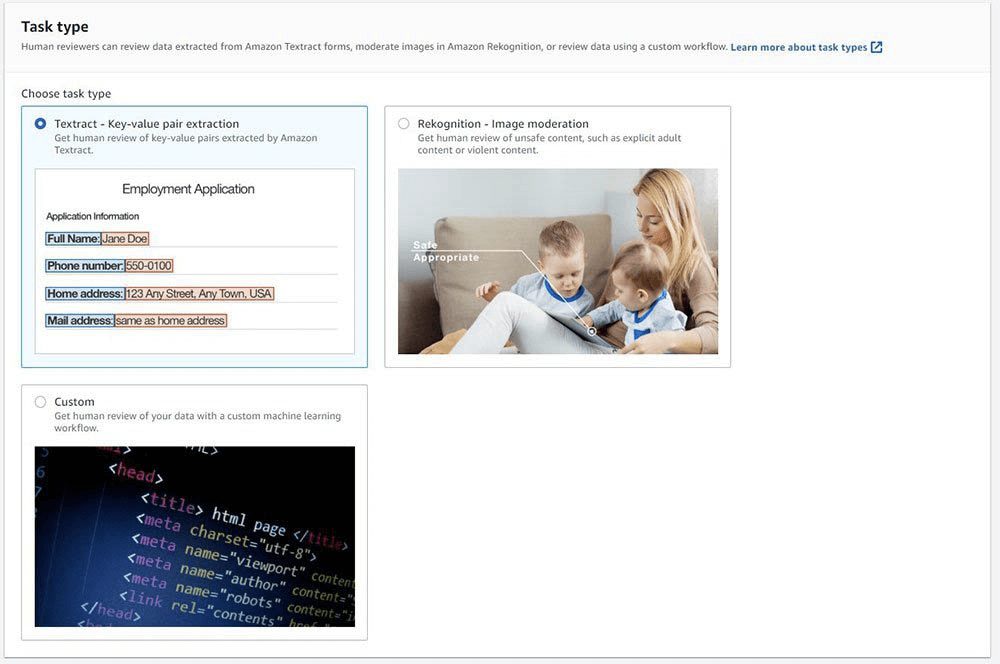
- use Amazon Textract’s
AnalyzeDocumentAPI for form data extraction and the Amazon A2I console to specify the conditions under which Amazon A2I routes predictions to reviewers. The conditions are set based on the confidence threshold of important form keys. For example, you can send a document to a human to review if the key “Name” or its associated value “Jane Doe” was detected with low confidence.
- use Amazon Textract’s
Amazon Athena
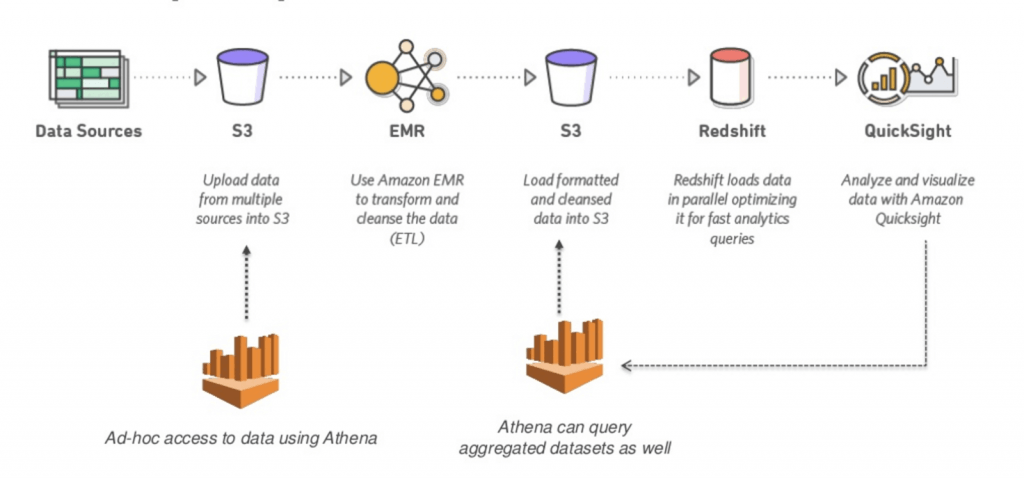
- an interactive query service that enables users to run SQL-based queries directly on data stored in Amazon S3 without complex ETL processes
- supports many file formats, including JSON and Parquet, making it ideal for querying structured and semi-structured data
- Parquet and ORC file formats both support predicate pushdown (also called predicate filtering). Parquet and ORC both have blocks of data that represent column values. Each block holds statistics for the block, such as max/min values. When a query is being executed, these statistics determine whether the block should be read or skipped.
- Apache Parquet is an open-source columnar storage format that is 2x faster to unload and takes up 6x less storage in Amazon S3 as compared to other text formats. One can
COPYApache Parquet and Apache ORC file formats from Amazon S3 to your Amazon Redshift cluster. Using AWS Glue, one can configure and run a job to transform CSV data to Parquet. Parquet is a columnar format that is well suited for AWS analytics services like Amazon Athena and Amazon Redshift Spectrum.
- Serverless

Amazon QuickSight
- a business intelligence service typically used to create visualizations and dashboards
- ML Insights
- uses machine learning to uncover hidden insights and trends, helping organizations identify key drivers and forecast business metrics
- ML-powered anomaly detection
- leverages Amazon’s Random Cut Forest algorithm to detect outliers and identify the top contributors to any significant changes, such as spikes in sales or dips in website traffic
- ML-powered forecasting
- forecast metrics by handling complex scenarios like seasonality and outliers
- Autonarratives
- enhance dashboards with plain language descriptions, enabling users to quickly interpret data and make faster, informed decisions
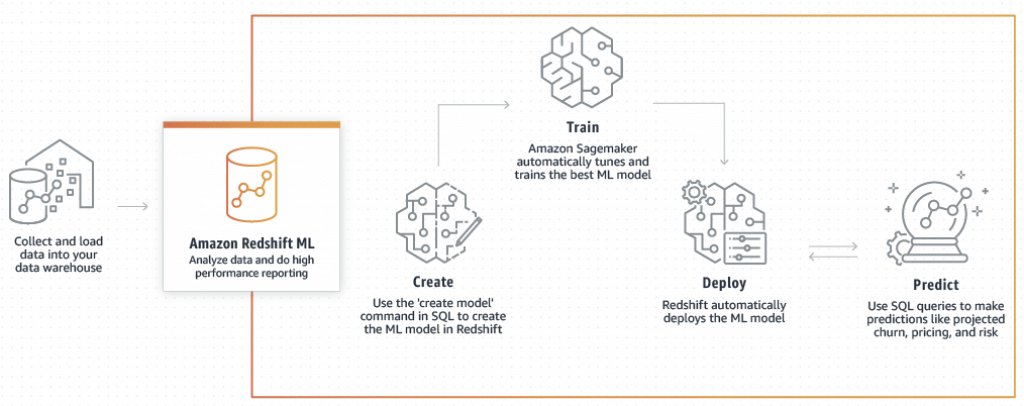
Amazon Redshift ML
- Create, train, and deploy machine learning (ML) models using familiar SQL commands, using your Redshift data and then use these models to make predictions
- Suitable for
- fraud detection
- risk scoring
- churn prediction