Fleet & Spot Fleet
- EC2 Fleet and Spot Fleet are designed to be a useful way to launch a fleet of tens, hundreds, or thousands of Amazon EC2 instances in a single operation. Each instance in a fleet is either configured by a launch template or a set of launch parameters that you configure manually at launch.
AWS Nitro Enclaves
- Create isolated execution environments, called enclaves, from Amazon EC2 instances.
- Process highly sensitive data in an isolated compute environment (like Personally Identifiable Information (PII), healthcare, financial, …)
- Fully isolated virtual machines, hardened, and highly constrained (Not a container, not persistent storage, no interactive access, no external networking)
- Helps reduce the attack surface for sensitive data processing apps
- Cryptographic Attestation – only authorized code can be running in your Enclave
- Only Enclaves can access sensitive data (integration with KMS)
EC2 Instance Metadata (IMDS)
- Info about the EC2 instance
- access url is http://169.254.169.254/latest/meta-data, without using an IAM Role needed
- retrieve the IAM Role name from the metadata
- IMDSv2 is more secure, needs 2 steps
- Get Session Token (limited validity) – using headers & PUT
- Use Session Token in IMDSv2 calls – using headers
CLI for instances
- The describe-instances command describes the specified instances or all instances.
- [–dry-run | –no-dry-run]
- [–instance-ids ]
- [–filters ] : get only the details that you like from the output of your command
- [–cli-input-json ]
- [–starting-token ]
- [–page-size ]
- [–max-items ] : defines the total number of items to be returned in the command’s output
- [–generate-cli-skeleton] : generate and display a parameter template that you can customize and use as input on a later command
EC2 Instance Recovery
- Status Check:
- Instance status = check the EC2 VM
- System status = check the underlying hardware
- Attached EBS status = check attached EBS volumes
- Recovery: Same Private, Public, Elastic IP, metadata, placement group
- Automatically Restore Instance Availability
- Simplified Automatic Recovery
- AWS sends one of the following events to your AWS Health Dashboard, depending on the outcome:
- Success event:
AWS_EC2_SIMPLIFIED_AUTO_RECOVERY_SUCCESS - Failure event:
AWS_EC2_SIMPLIFIED_AUTO_RECOVERY_FAILURE - Cannot work with
- Tenancy: Dedicated Host.
- Storage: Instances with instance store volumes
- Networking: Instances using an Elastic Fabric Adapter
- Auto Scaling: Instances that are part of an Auto Scaling group
- Amazon CloudWatch Action Based Recovery
- AWS sends one of the following events to your AWS Health Dashboard, depending on the outcome:
- Success event:
AWS_EC2_INSTANCE_AUTO_RECOVERY_SUCCESS - Failure event:
AWS_EC2_INSTANCE_AUTO_RECOVERY_FAILURE - CloudWatch action based recovery works with the
StatusCheckFailed_Systemmetric. CloudWatch action based recovery provides to-the-minute recovery response time granularity and Amazon Simple Notification Service (Amazon SNS) notifications of recovery actions and outcomes. - Cannot work with
- Tenancy: Dedicated Host.
- Networking: Instances using an Elastic Fabric Adapter
- Auto Scaling: Instances that are part of an Auto Scaling group
- Simplified Automatic Recovery

| Comparison point | Simplified automatic recovery | CloudWatch action based recovery |
|---|---|---|
| Configuration | Enabled by default on supported instances | Requires manual configuration of CloudWatch alarms and actions |
| Flexibility | Fixed recovery behavior managed by AWS | Customizable actions and conditions |
| Notification | Basic notifications through AWS Health Dashboard | Customizable notifications through SNS |
| Metal instance size | Excluded | Included |
| Instance store volumes attached at launch | Not supported for instances that attach instance store volumes at launch | Supported on selected instance types. Note that data on instance store volumes is lost during instance recovery. |
| Recovery time | Standard recovery attempt | Faster recovery attempts than simplified automatic recovery |
| Host problem resolves during migration | Migration might be canceled and the instance stays on the original host | Migration continues to a new host |
| Cost | No additional cost | Might incur CloudWatch charges |
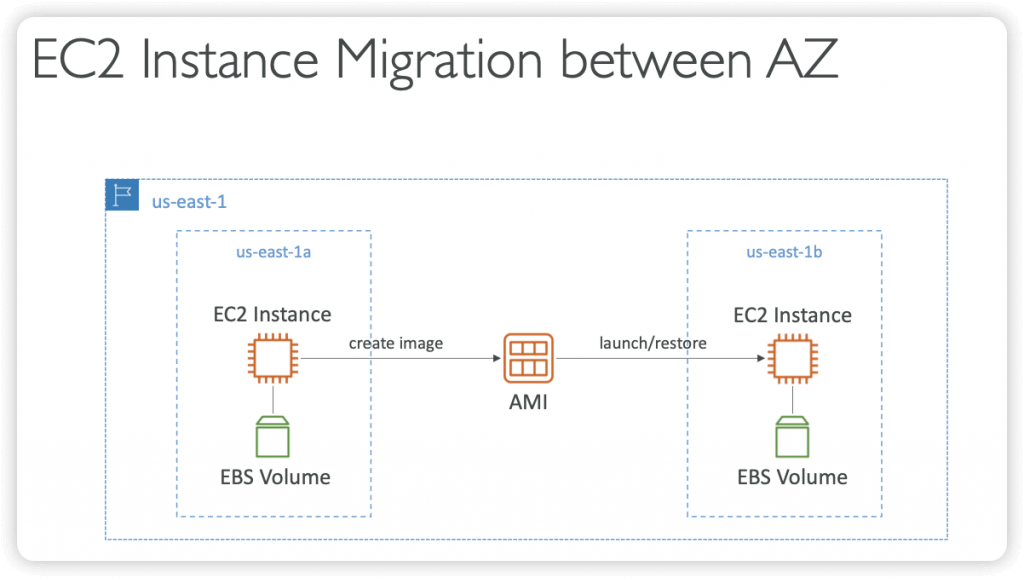
EC2 Instances Migration between AZ
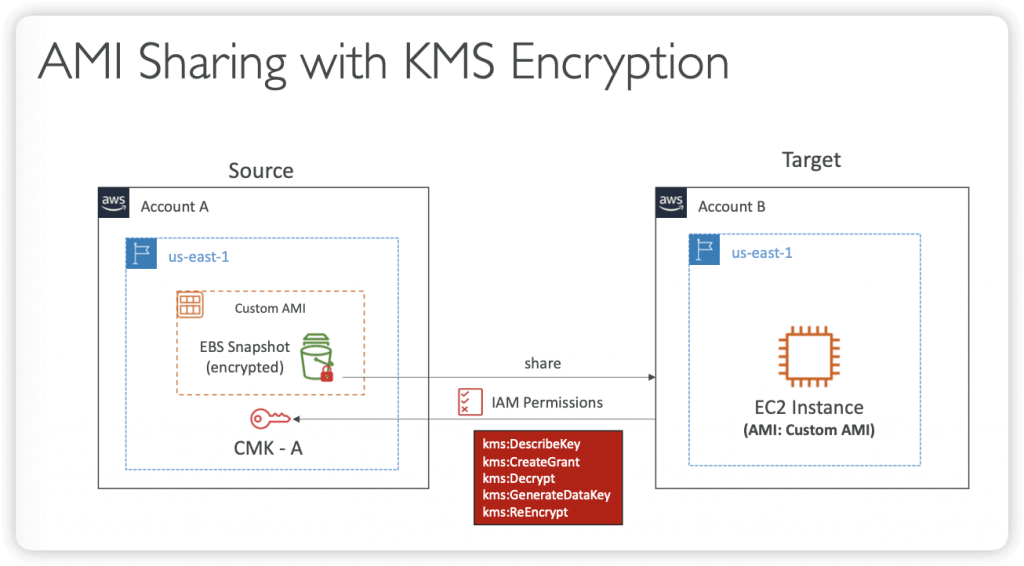
- Cross-Account AMI Sharing
- You can share an AMI with another AWS account
- Sharing an AMI does not affect the ownership of the AMI
- You can only share AMIs that have unencrypted volumes and volumes that are encrypted with a customer managed key
- If you share an AMI with encrypted volumes, you must also share any customer managed keys used to encrypt them
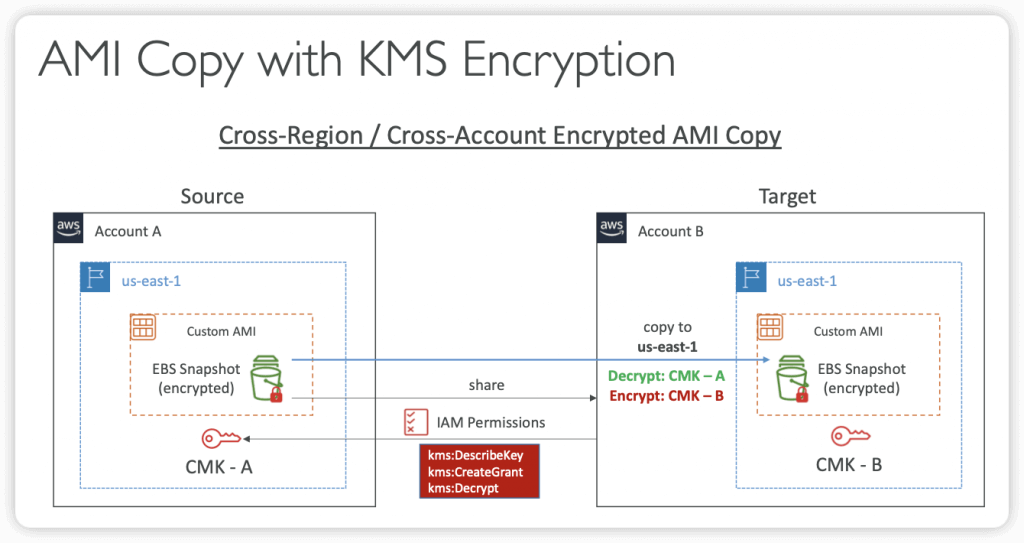
- Cross-Account AMI Copy
- If you copy an AMI that has been shared with your account, you are the owner of the target AMI in your account
- The owner of the source AMI must grant you read permissions for the storage that backs the AMI (EBS Snapshot)
- If the shared AMI has encrypted snapshots, the owner must share the key or keys with you as well
- Can encrypt the AMI with your own CMK while copying
Auto Scaling Groups
- Scaling Policies
- Dynamic Scaling
- Target Tracking Scaling
- Simple to set-up
- Simple / Step Scaling
- When a CloudWatch alarm is triggered (example CPU > 70%), then add 2 units
- When a CloudWatch alarm is triggered (example CPU < 30%), then remove 1
- Scheduled Scaling
- Anticipate a scaling based on known usage patterns
- Predictive Scaling
- continuously forecast load and schedule scaling ahead
- (Good) metrics to scale one
- CPUUtilization: Average CPU utilization across your instances
- RequestCountPerTarget: to make sure the number of requests per EC2 instances is stable
- Average Network In / Out (if you’re application is network bound)
- Any custom metric (that you push using CloudWatch)
- Scaling Cooldowns
- After a scaling activity happens, you are in the cooldown period (default 300 seconds, 5 mins)
- During the cooldown period, the ASG will not launch or terminate additional instances (to allow for metrics to stabilize)
- Advice: Use a ready-to-use AMI to reduce configuration time in order to be serving request fasters and reduce the cooldown period
- Lifecycle Hooks
- By default, as soon as an instance is launched in an ASG it’s in service
- You can perform extra steps before the instance goes in service (Pending state)
- Define a script to run on the instances as they start
- You can perform some actions before the instance is terminated (Terminating state)
- Pause the instances before they’re terminated for troubleshooting
- Use cases: cleanup, log extraction, special health checks
- Integration with EventBridge, SNS, and SQS
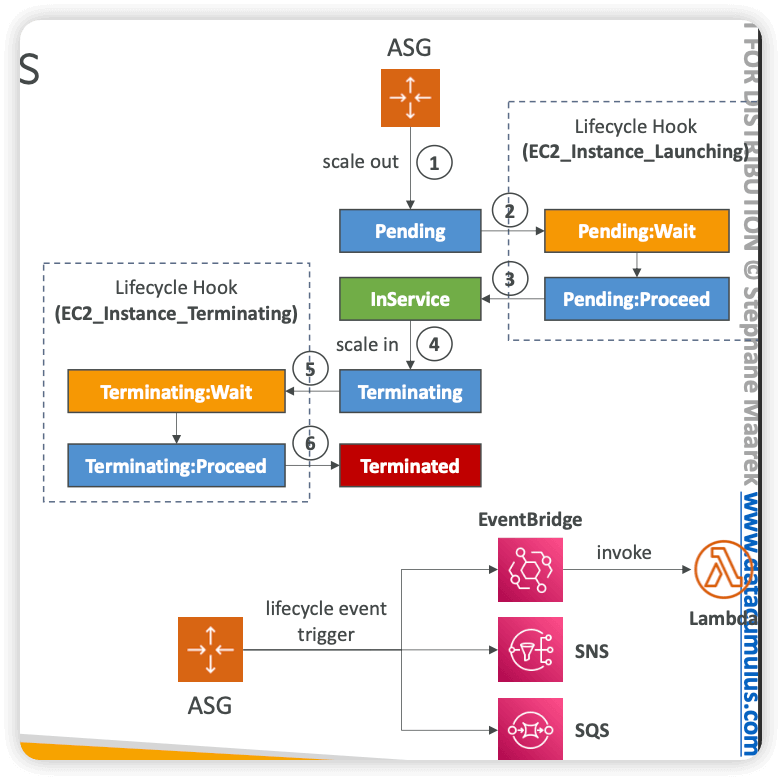
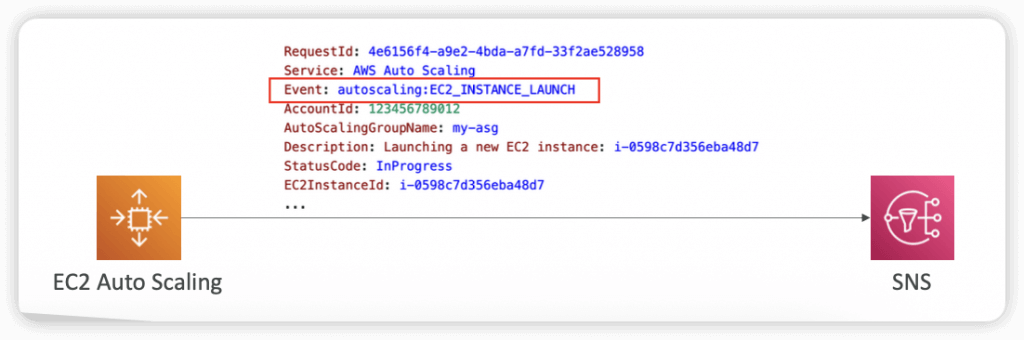
- SNS Notifications
- autoscaling:EC2_INSTANCE_LAUNCH
- autoscaling:EC2_INSTANCE_LAUNCH_ERROR
- autoscaling:EC2_INSTANCE_TERMINATE
- autoscaling:EC2_INSTANCE_TERMINATE_ERROR
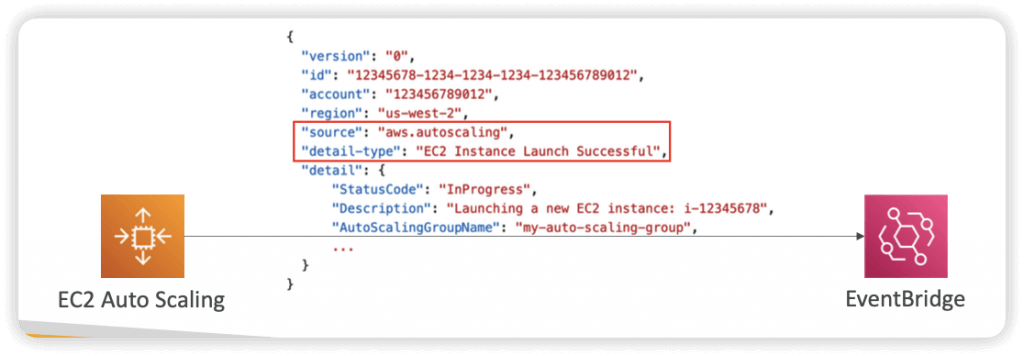
- EventBridge Events
- can create Rules that match the following ASG events:
- EC2 Instance Launching, EC2 Instance Launch Successful/Unsuccessful
- EC2 Instance Terminating, EC2 Instance Terminate Successful/Unsuccessful
- EC2 Auto Scaling Instance Refresh Checkpoint Reached
- EC2 Auto Scaling Instance Refresh Started, Succeeded, Failed, Cancelled
- can create Rules that match the following ASG events:
- Termination Policies
- Determine which instances to terminates first during scale-in events, Instance Refresh, and AZ Rebalancing
- Default Termination Policy
- Select AZ with more instances
- Terminate instance with oldest Launch Template or Launch Configuration
- If instances were launched using the same Launch Template, terminate the instance that is closest to the next billing hour
- AllocationStrategy
- terminates instances to align the remaining instances to the Allocation Strategy (e.g., lowest-price for Spot Instances, or lower priority On-Demand Instances)
- OldestLaunchTemplate
- terminates instances that have the oldest Launch Template
- OldestLaunchConfiguration
- terminates instances that have the oldest Launch Configuration
- ClosestToNextInstanceHour
- terminates instances that are closest to the next billing hour
- NewestInstance
- terminates the newest instance (testing new launch template)
- OldestInstance
- terminates the oldest instance (upgrading instance size, not launch template)
- Note: you can use one or more policies and specify the evaluation order
- Note: can define Custom Termination Policy backed by a Lambda function
| Feature | Launch Configuration | Launch Template |
|---|---|---|
| Mutability | Immutable | Versioned (new versions for edits) |
| Versioning | No | Yes |
| Feature Support | Limited | Extensive – Multiple instance types and purchase options (e.g., combining Spot and On-Demand instances) within a single ASG. – Dedicated Hosts and Capacity Reservations. – Advanced networking configurations. – More granular control over EBS volumes and other instance properties. |
| AWS Recommendation | Legacy, not recommended for new features | Recommended |
- Scale-out Latency
- When an ASG scales out, it tries to launch instances as fast as possible
- Some applications contain a lengthy unavoidable latency that exists at the application initialization/bootstrap layer (several minutes or more)
- Processes that can only happen at initial boot: applying updates, data or state hydration, running configuration scripts…
- Solution was to over-provision compute resources to absorb unexpected demand increases (increased cost) or use Golden Images to try to reduce boot time
- ASG Warm Pools
- Reduces scale-out latency by maintaining a pool of pre-initialized instances
- In a scale-out event, ASG uses the pre-initialized instances from the Warm Pool instead of launching new instances
- Warm Pool Size Settings
- Minimum warm pool size (always in the warm pool)
- Max prepared capacity = Max capacity of ASG (default)
- OR Max prepared capacity = Set number of instances
- Warm Pool Instance State – what state to keep your Warm Pool instances in after initialization (Running, Stopped, Hibernated)
- Warm Pools instances don’t contribute to ASG metrics that affect Scaling Policies
- Instance Reuse Policy
- Instance Reuse Policy allows you to return instances to the Warm Pool when a scale-in event happens; different with default (ASG terminates instances when ASG scales in, then it launches new instances into the Warm Pool)
| Warm Pools – Instance States | Running | Stopped | Hibernated |
|---|---|---|---|
| Scale Out Delay | Faster – immediately available to accept traffic | Slower – need to be started before traffic can be served which adds some delay | Medium – pre-initialized EC2 instances (disk, memory…) |
| Start Up Delay | Lower – EC2 instances are already running | Slower – needs to go through the application startup process which may need some time especially if there are many application components to initialize | Medium – faster startup process than EC2 instances in the Stopped state because components and applications are already initialized in memory |
| Costs | Higher – incur costs for their usage even when they’re not serving traffic | Lower Cost – do not incur running costs, only pay for the attached resources, more cost effective | Lower Cost – do not incur running costs, only pay for the attached resources, more cost effective The hibernation state must be able to fit onto the EBS volume (might need a bigger volume) |


- [ 🧐QUESTION🧐 ] collect EC2 instance log before terminated by ASG
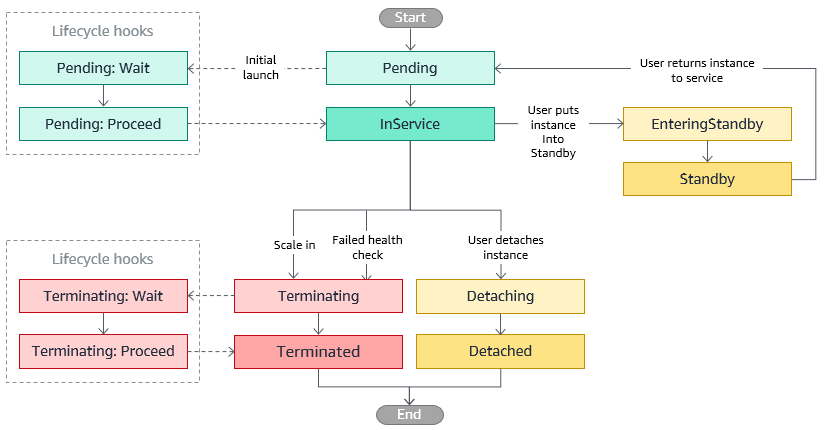
- When Amazon EC2 Auto Scaling responds to a scale out event, it launches one or more instances. These instances start in the
Pendingstate. If you added anautoscaling:EC2_INSTANCE_LAUNCHINGlifecycle hook to your Auto Scaling group, the instances move from thePendingstate to thePending:Waitstate. After you complete the lifecycle action, the instances enter thePending:Proceedstate. When the instances are fully configured, they are attached to the Auto Scaling group and they enter theInServicestate. - When Amazon EC2 Auto Scaling responds to a scale in event, it terminates one or more instances. These instances are detached from the Auto Scaling group and enter the
Terminatingstate. If you added anautoscaling:EC2_INSTANCE_TERMINATINGlifecycle hook to your Auto Scaling group, the instances move from theTerminatingstate to theTerminating:Waitstate. After you complete the lifecycle action, the instances enter theTerminating:Proceedstate. When the instances are fully terminated, they enter theTerminatedstate. - Using CloudWatch agent is the most suitable tool to use to collect the logs. The unified CloudWatch agent enables you to do the following:
- Collect more system-level metrics from Amazon EC2 instances across operating systems. The metrics can include in-guest metrics, in addition to the metrics for EC2 instances. The additional metrics that can be collected are listed in Metrics Collected by the CloudWatch Agent.
- Collect system-level metrics from on-premises servers. These can include servers in a hybrid environment as well as servers not managed by AWS.
- Retrieve custom metrics from your applications or services using the
StatsDandcollectdprotocols.StatsDis supported on both Linux servers and servers running Windows Server. On the other hand,collectdis supported only on Linux servers. - Collect logs from Amazon EC2 instances and on-premises servers, running either Linux or Windows Server.
- You can store and view the metrics that you collect with the CloudWatch agent in CloudWatch just as you can with any other CloudWatch metrics. The default namespace for metrics collected by the CloudWatch agent is
CWAgent, although you can specify a different namespace when you configure the agent.
- When Amazon EC2 Auto Scaling responds to a scale out event, it launches one or more instances. These instances start in the
Plenty Instance Types across 5 Instance Families
- AWS offers over 300 EC2 instance types across 5 instance families (general purpose family, memory-optimized, storage-optimized, compute-optimized, and accelerated computing), each with varying resource and performance focuses
- For example, within the compute-optimized family, you have C4 instance types (running on Haswell chips) and more recent C5 instance types (running on Skylake with Nitro system).
Instance Purchasing Options
- On-Demand Instances – the default option, for short-term ad-hoc requirements where the job can’t be interrupted
- On-Demand Capacity Reservations – the only way to reserve capacity for blocks of time such as 9am-5pm daily
- Spot instance – highest discount potential (50-90%) but no commitment from AWS, could be terminated with 2min notice. Could use for grid and high-performance computing.
- Reserved Instances – for long-term workloads, 1 or 3 year commitment in exchange for 40-60% discount
- Dedicated Instances – run on hardware dedicated to 1 customer (more $$)
- Dedicated Host – fully dedicated and physically isolated server. Allows you to use your server-bound software licenses (e.g. IBM, Oracle) and addresses compliance and regulatory requirements and potentially reduce cost (note: billing is per-hour not per-instance)
- Bare metal EC2 instance – for when the workload needs access to the hardware feature set (e.g. Intel hardware)
Launching Instances
- Configurations / Launch Templates used to create new EC2 instances using stored parameters such as instance family, instance type, AMI, key pair and security groups. Auto-scaling groups can launch instances using config templates. You can’t edit a launch config, but you can create a new one and point to it.
- User data – pass up to 16KB of user data at launch that the instance can run on startup such as config scripts
- Instance metadata (e.g. instance ID, hostname, events, security groups, public keys, network interfaces,) can be accessed via a direct URI or by using the Instance Metadata Query Tool
- When you launch an EC2 instance into a default VPC, it has a public and private DNS hostname and IP address. When you launch in a non-default VPC, it may not have a public hostname depending on the DNS and VPC configs.
- Errors when launching include InsufficientInstanceCapacity, InstanceLimitExceeded
- Instances terminate with no error if there are EBS problems (EBS volume limit, EBS snapshot is corrupt), or if the AMI you’re launching from is missing a required part
- Each EC2 instance that you launch has an associated root device volume, either EBS volume or an Instance Store volume (more these under Storage section below). You can use block device mapping to specify additional EBS volumes or instance store volumes to attach to a live instance, attach additional EBS volumes to a running instance, but can’t directly add additional Instance Store volumes.
- Run Command – run from the AWS Management Console, CLI or SDK, to install software, execute Powershell commands and scripts, configuring Windows settings, on live EC2 instances
Placement Groups
- Cluster placement group = packs instances close together inside an AZ to achieve low latency, high throughput – use for HPC
- Partition placement group = separate instances into logical partitions such that instances in one partition do not share hardware with instances in another partition. Gives you control and visibility into instance placement, but not great for performance. Used by large distributed workloads such as Hadoop.
- Spread placement group = place 1 or few instances each in distinct hardware to reduce correlated failures. Not great for performance
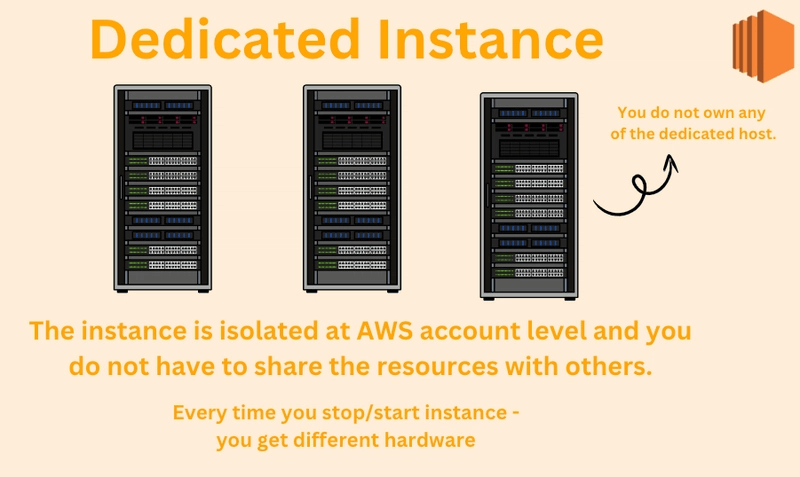
EC2 Dedicated Instances
- An AWS EC2 Dedicated Instance is a virtual machine running on hardware that is dedicated to a single customer, offering physical isolation from other AWS accounts.
- However, AWS may place other instances from the same account on the same physical hardware.
- An EC2 Dedicated Host is a physical server fully dedicated to a single customer, giving you full control over the server and the ability to run multiple EC2 instances on it for the duration of the host’s availability.
- Dedicated Hosts are often used for specific compliance or per-socket/per-core licensing needs.
| Dedicated Host | Dedicated Instance | |
|---|---|---|
| Dedicated physical server | Physical server with instance capacity fully dedicated to your use. | Physical server that’s dedicated to a single customer account. |
| Instance capacity sharing | Can share instance capacity with other accounts. | Not supported |
| Billing | Per-host billing | Per-instance billing |
| Visibility of sockets, cores, and host ID | Provides visibility of the number of sockets and physical cores | No visibility |
| Host and instance affinity | Allows you to consistently deploy your instances to the same physical server over time | Not supported |
| Targeted instance placement | Provides additional visibility and control over how instances are placed on a physical server | Not supported |
| Automatic instance recovery | Supported. | Supported |
| Bring Your Own License (BYOL) | Supported | Partial support |
| Capacity Reservations | Not supported | Supported |