a best practice is to enable versioning and MFA Delete on S3 buckets
S3 lifecycle 2 types of actions:
transition actions (define when to transition to another storage class)
expiration actions (objects expire, then S3 deletes them on your behalf)
objects have to be in S3 for > 30 days before lifecycle policy can take effect and move to a different storage class.
Intelligent Tiering automatically moves data to the most cost-effective storage
Standard-IA is multi-AZ whereas One Zone-IA is not
A pre-signed URL gives you access to the object identified in the URL (URL is made up of bucket name, object key, HTTP method, expiration timestamp). If you want to provide an outside partner with an object in S3, providing a pre-signed URL is a more secure (and easier) option than creating an AWS account for them and providing the login, which is more work to then manage and error-prone if you didn’t lock down the account properly.
You can’t send long-term storage data directly to Glacier, it has to pass through an S3 first
Accessed via API, if you want to access S3 directly it can require modifying the app to use the API which is extra effort
Can host a static website but not over HTTPS. For HTTPS use CloudFront+S3 instead.
Best practice: use IAM policies to grant users fine-grained control to your S3 buckets rather than using bucket ACLs
Can use multi-part upload to speed up uploads of large files to S3 (>100MB)
Amazon S3 Transfer Acceleration – leverages Amazon CloudFront’s globally distributed AWS Edge Locations. As data arrives at an AWS Edge Location, data is routed to your Amazon S3 bucket over an optimized network path.
The name of the bucket used for Transfer Acceleration must be DNS-compliant and must not contain periods (“.”).
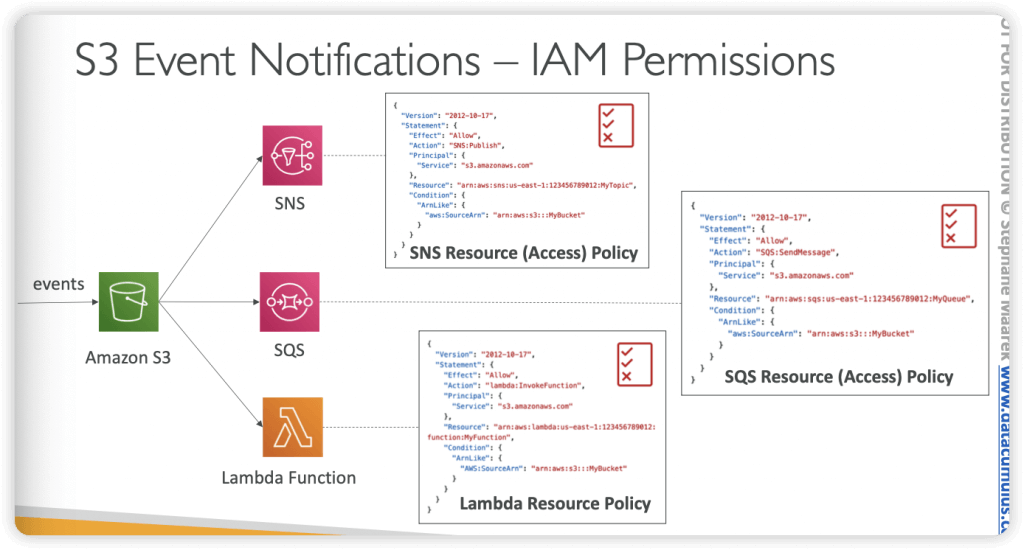
S3 Event Notifications – trigger Lambda functions to do pre-process, like “ObjectCreated:Put” event
S3 Storage Lens – provide visibility into storage usage and activity trends
S3 Object Lambda – only trigger on “object – retrieving”;
so it’s not ideal for waterproofing unless we want keep S3 objects as untouched as original.
but it’s good to “redact PII” before sending to application.
Cross-origin resource sharing (CORS)
AllowedOrigin – Specifies domain origins that you allow to make cross-domain requests.
AllowedMethod – Specifies a type of request you allow (GET, PUT, POST, DELETE, HEAD) in cross-domain requests.
AllowedHeader – Specifies the headers allowed in a preflight request.
MaxAgeSeconds – Specifies the amount of time in seconds that the browser caches an Amazon S3 response to a preflight OPTIONS request for the specified resource. By caching the response, the browser does not have to send preflight requests to Amazon S3 if the original request will be repeated.
ExposeHeader – Identifies the response headers that customers are able to access from their applications (for example, from a JavaScript XMLHttpRequest object).
To upload an object to the S3 bucket, which uses SSE-KMS
send a request with an x-amz-server-side-encryption header with the value of aws:kms.
Only with “aws:kms”, it would be SSE-KMS (AWS KMS keys)
else it may be using (Amazon S3 managed keys), with value “AES256”
(optional) x-amz-server-side-encryption-aws-kms-key-id header, which specifies the ID of the AWS KMS master encryption key
If the header is not present in the request, Amazon S3 assumes the default KMS key.
Regardless, the KMS key ID that Amazon S3 uses for object encryption must match the KMS key ID in the policy, otherwise, Amazon S3 denies the request.
(optional) supports encryption context with the x-amz-server-side-encryption-context header.
For a large file uploading (which would use “multipart”)
The kms:GenerateDataKey permission allows you to initiate the upload.
The kms:Decrypt permission allows you to encrypt newly uploaded parts with the key that you used for previous parts of the same object.
Using server-side encryption with customer-provided encryption keys (SSE-C) allows you to set your own encryption keys. With the encryption key you provide as part of your request, Amazon S3 manages both the encryption, as it writes to disks, and decryption, when you access your objects.
Amazon S3 does not store the encryption key you provide
only a randomly salted HMAC value of the encryption key in order to validate future requests, which cannot be used to derive the value of the encryption key or to decrypt the contents of the encrypted object
That means, if you lose the encryption key, you lose the object.
Headers
x-amz-server-side-encryption-customer-algorithm – This header specifies the encryption algorithm. The header value must be “AES256”.
x-amz-server-side-encryption-customer-key – This header provides the 256-bit, base64-encoded encryption key for Amazon S3 to use to encrypt or decrypt your data.
x-amz-server-side-encryption-customer-key-MD5 – This header provides the base64-encoded 128-bit MD5 digest of the encryption key according to RFC 1321. Amazon S3 uses this header for a message integrity check to ensure the encryption key was transmitted without error.
Object Integrity
S3 uses checksum to validate the integrity of uploaded objects
MD5, MD5 & ETag, SHA-1, SHA-256, CRC32, CRC32C
ETag – represents a specific version of the object, ETag = MD5 (if SSE-S3)
Glacier
slow to retrieve, but you can use Expedited Retrieval to bring it down to just 1-5min.
Time To Live (TTL) for DynamoDB allows you to define when items in a table expire so that they can be automatically deleted from the database.
DynamoDB returns all of the item attributes by default. To get just some, rather than all of the attributes, use a projection expression
condition expressions – is used to determine which items should be modified for data manipulation operations such as PutItem, UpdateItem, and DeleteItem calls
expression attribute names – a placeholder that you use in a projection expression as an alternative to an actual attribute name
filter expressions – determines which items (and not the attributes) within the Query results should be returned
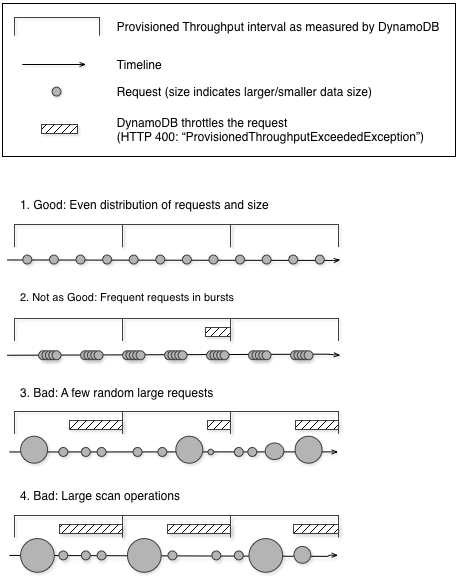
Throughput Capacity
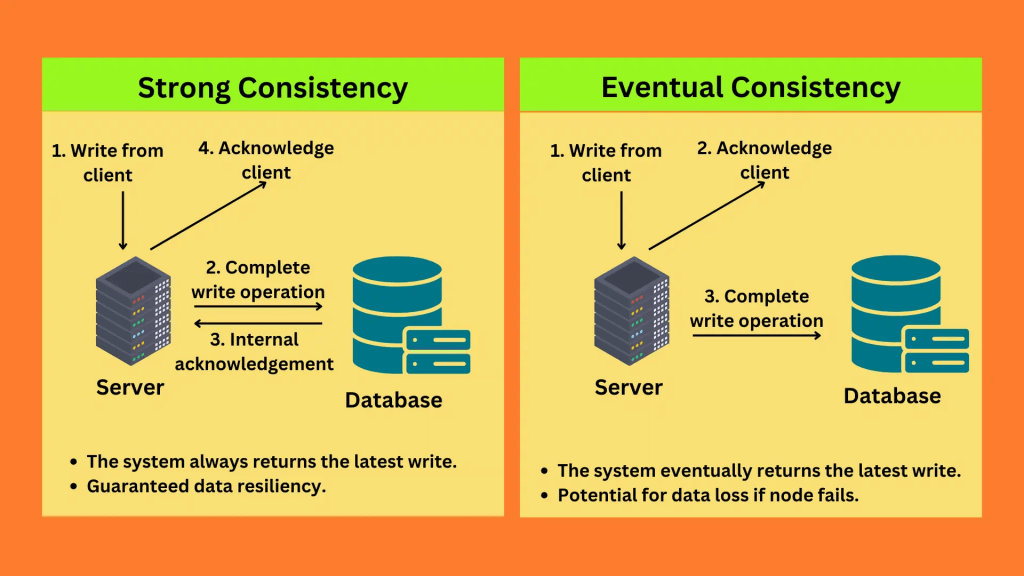
One read request unit represents one strongly consistent read operation per second, or two eventually consistent read operations per second, for an item up to 4 KB in size.
One write request unit represents one write operation per second, for an item up to 1 KB in size.
For any “transactional” operation (read or write), double the request units needed.
Partitions throttled
Increase the amount of read or write capacity (RCU and WCU) for your table to anticipate short-term spikes or bursts in read or write operations.
Cons: manual config, also expensive
Implement error retries and exponential backoff.
Distribute your read operations and write operations as evenly as possible across your table.
Implement a caching solution, such as DynamoDB Accelerator (DAX) or Amazon ElastiCache.
Cons: only works for massive read; also expensive
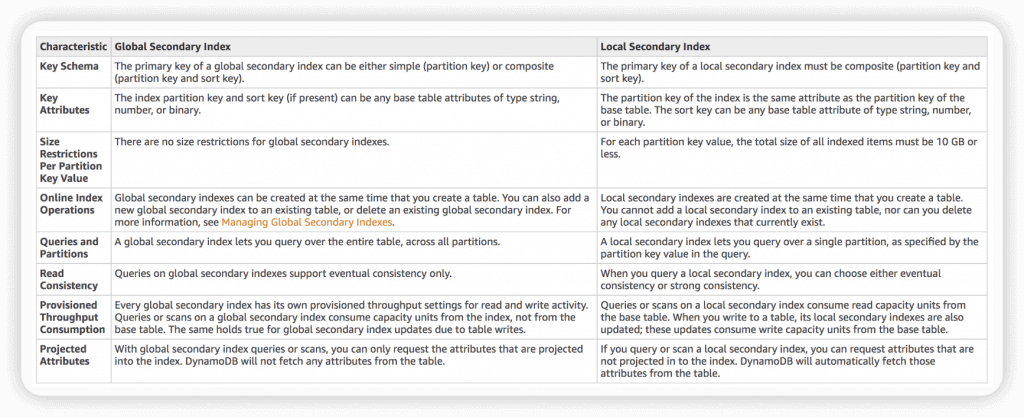
Global Secondary Index is an index with a partition key and a sort key that can be different from those on the base table.
To speed up queries on non-key attributes
Can span all of the data in the base table, across all partitions.
“CreateTable” operation with the “GlobalSecondaryIndexes” parameter
20 global secondary indexes (default limit) per table
only “eventual consistency”
Local Secondary Index cannot add into existing table; but Global Secondary Index can.
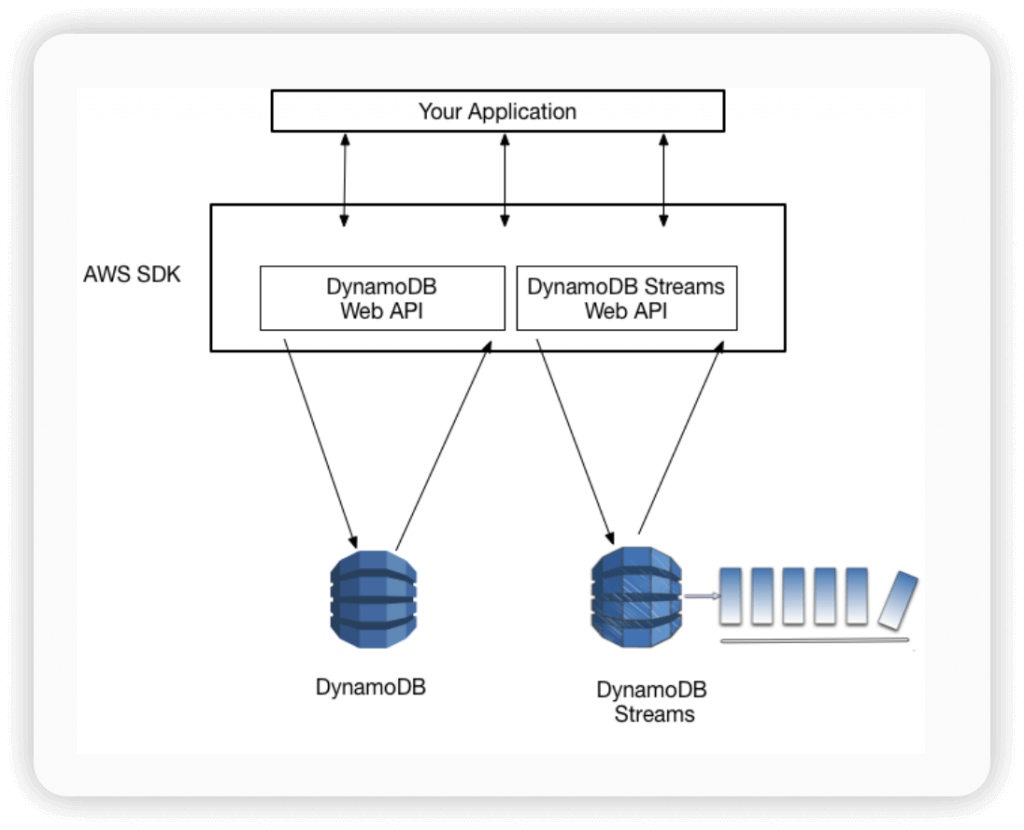
Amazon DynamoDB Streams
integrated with AWS Lambda so that you can create triggers
All data in DynamoDB Streams is subject to a 24-hour lifetime.
StreamEnabled (Boolean)
StreamViewType (string)
KEYS_ONLY – Only the key attributes of the modified items are written to the stream.
NEW_IMAGE – The entire item, as it appears after it was modified, is written to the stream.
OLD_IMAGE – The entire item, as it appeared before it was modified, is written to the stream.
NEW_AND_OLD_IMAGES – Both the new and the old item images of the items are written to the stream.
Amazon DynamoDB Accelerator (DAX) is a fully managed, highly available, in-memory cache for DynamoDB
key benefits of using DAX is that it works transparently with existing DynamoDB API calls, and the application code does not need to be modified to take advantage of the caching layer.
ProvisionedThroughputExceededException means that your request rate is too high. The AWS SDKs for DynamoDB automatically retries requests that receive this exception.
Reduce the frequency of requests using error retries and exponential backoff
—–
Use when the question talks about key/value storage, near-real time performance, millisecond responsiveness, and very high requests per second
Not compatible with relational data such as what would be stored in a MySQL or RDS DB
DynamoDB measures RCUs (read capacity units, basically reads per second) and WCUs (write capacity units)
DynamoDB auto scaling uses the AWS Application Auto Scaling service to dynamically adjust throughput capacity based on traffic.
Best practices:
keep item sizes small (<400kb) otherwise store in S3 and use pointers from DynamoDB
store more frequently and less frequently accessed data in different tables
if storing data that will be accessed by timestamp, use separate tables for days, weeks, months
RDS
Transactional DB (OLTP)
If too much read traffic is clogging up write requests, create an RDS read replica and direct read traffic to the replica. The read replica is updated asynchronously. Multi-AZ creates a read replica in another AZ and synchronously replicates to it
RDS is a managed database, not a data store. Careful in some questions if they ask about migrating a data store to AWS, RDS would not be suitable.
To encrypt an existing RDS database, take a snapshot, encrypt a copy of the snapshot, then restore the snapshot to the RDS instance. Since there may have been data changed during the snapshot/encrypt/load operation, use the AWS DMS (Database Migration Service) to sync the data.
RDS can be restored to a backup taken as recent as 5min ago using point-in-time restore (PITR). When you restore, a new instance is created from the DB snapshot and you need to point to the new instance.
RDS Enhanced Monitoring metrics – get the specific percentage of the CPU bandwidth and total memory consumed by each database process
Amazon RDS supports using Transparent Data Encryption (TDE) to encrypt stored data on your DB instances running Microsoft SQL Server. TDE automatically encrypts data before it is written to storage, and automatically decrypts data when the data is read from storage.
RDS encryption uses the industry standard AES-256 encryption algorithm to encrypt your data on the server that hosts your RDS instance. With TDE, the database server automatically encrypts data before it is written to storage and automatically decrypts data when it is read from storage.
RDS Proxy helps you manage a large number of connections from Lambda to an RDS database by establishing a warm connection pool to the database.
AWS DataSync
on-premises -> AWS storage services
A DataSync Agent is deployed as a VM and connects to your internal storage (NFS, SMB, HDFS)
Encryption and data validation
Amazon FSx
to replace Microsoft Windows file server
can be multi-AZ
supports DFS (distributed file system) protocol
integrates with AD
FSx for Lustre is for high-performance computing (HPC) and machine learning workloads – does not support Windows
efficiently handles the high I/O operations required for processing high-resolution videos
optimized for both sequential and random access workloads
AWS Snowball
a data transfer service designed for moving large amounts of data into and out of AWS using physical storage devices
ideal in situations where there is limited or no internet connectivity, or where network bandwidth is insufficient for large data transfers.
AWS Database Migration Service (AWS DMS)
a managed migration and replication service
Homogeneous data migrations are serverless and enable you to transfer data between identical database engines
primarily better suited for one-time migrations, ensuring consistency during the transition
But also supports real-time data replication using change data capture (CDC) from source to target
Continuous synchronization can introduce latency and potential data consistency issues
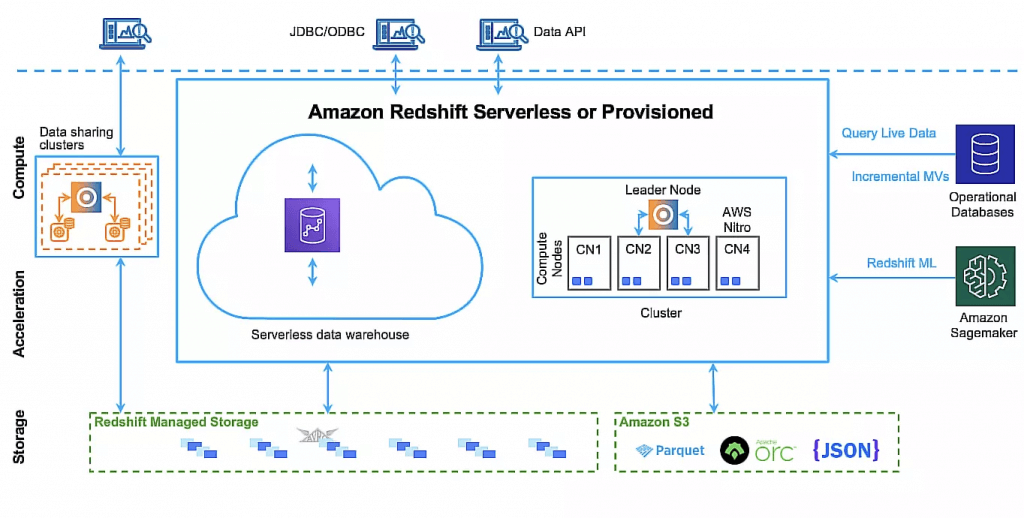
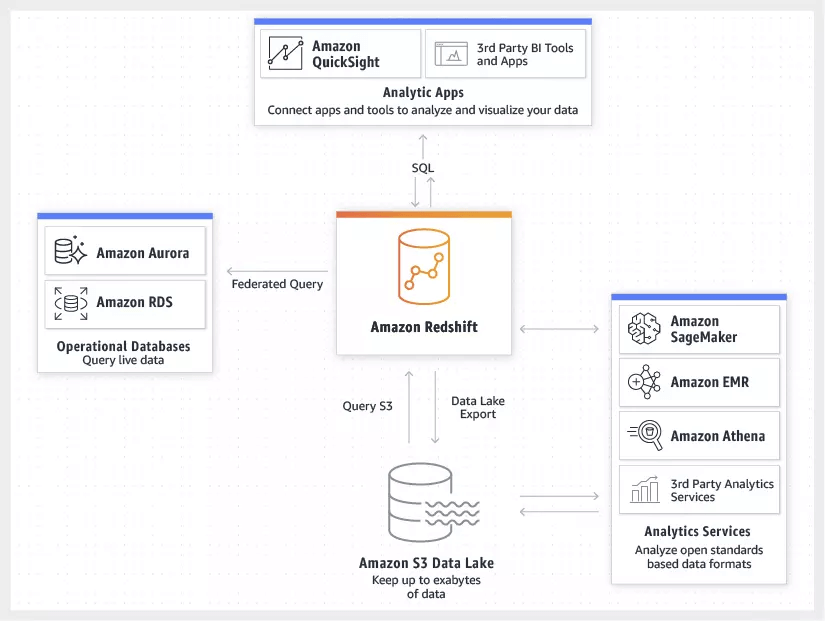
Amazon Redshift
a fast, fully managed, petabyte-scale data warehouse service that makes it simple and cost-effective to efficiently analyze all your data
uses Massively Parallel Processing (MPP) technology to process massive volumes of data at lightning speeds
Instance Store
Block-level storage (with EBS disk that is physically attached to the host computer)
Temporary/ephemeral, ideal for
temp info that changes frequently such as caches, buffers, scratch data,
data that is replicated across a fleet of instances where you can afford to lose a copy once in a while and the data is still replicated across other instances
Very high performance and low latency
Can be cost effective since the cost is included in the instance cost
You can hibernate the instance to keep what’s in memory and in the EBS, but if you stop or terminate the instance then you lose everything in memory and in the EBS storage.
EBS
General Purpose SSD (gp2, gp3) – for low-latency interactive apps, dev&test environments.
Can have bursts of CPU performance but not sustained.
Be sure to distinguish: IOPS solves I/O aka disk wait time, not CPU performance
IOPS is related to volume size, specifically per GB.
These are more $
In contrast to SSD volumes, EBS also offers HDD volumes:
EBS Cold HDD (sc1) lowest cost option for infrequently accessed data and use cases like sequential data access
EBS Throughput Optimized HDD (st1) which is for frequent access and throughput intensive workloads such as MapReduce, Kafka, log processing, data warehouse and ETL workloads. Higher $ than sc1.
however note that the HDD volumes have no IOPS SLA.
EBS can’t attach to multiple AZs (there is a new EBS multi-attach feature but it’s only single AZ, and only certain SSD volumes such as iop1, iop2). EBS is considered a “single point of failure”.
To implement a shared storage layer of files, you could replace multiple EBS with a single EFS
Not fully managed, doesn’t auto-scale (as opposed to EFS)
Use EBS Data Lifecycle Manager (DLM) to manage backup snapshots. Backup snapshots are incremental, but the deletion process is design so that you only need to retain the most recent snapshot.
iSCSI is block protocol, whereas NFS is a file protocol
EBS supports encryption of data at rest and encryption of data in transit between the instance and the EBS volume.
EFS
can attach to many instances across multiple AZ, whereas EBS cannot (there is a new EBS multi-attach feature but it’s only single AZ, and only certain SSD volumes such as iop1, iop2)
fully managed, auto-scales (whereas EBS is not)
Linux only, not Windows!
Since it is Linux, use POSIX permissions to restrict access to files
After a period up to 90 days, you can transition unused data to EFS IA
Protected by EFS Security Groups to control network traffic and act as firewall
Amazon Aurora Global Database
for globally distributed applications. 1 DB can span multiple regions
If too much read traffic is clogging up write requests, create an Aurora replica and direct read traffic to the replica. The replica serves as both standby instance and target for read traffic.
“Amazon Aurora Serverless” is different from “Amazon Aurora” – it automatically scales capacity and is ideal for infrequently used applications.
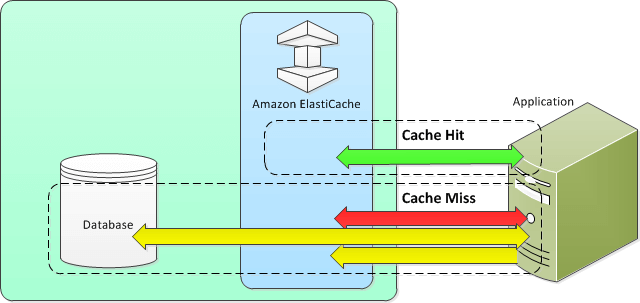
ElastiCache
Database cache. Put in front of DBs such as RDS or Redshift, or in front of certain types of DB data in S3, to improve performance
As a cache, it is an in-memory key/value store database (more OLAP than OLTP)
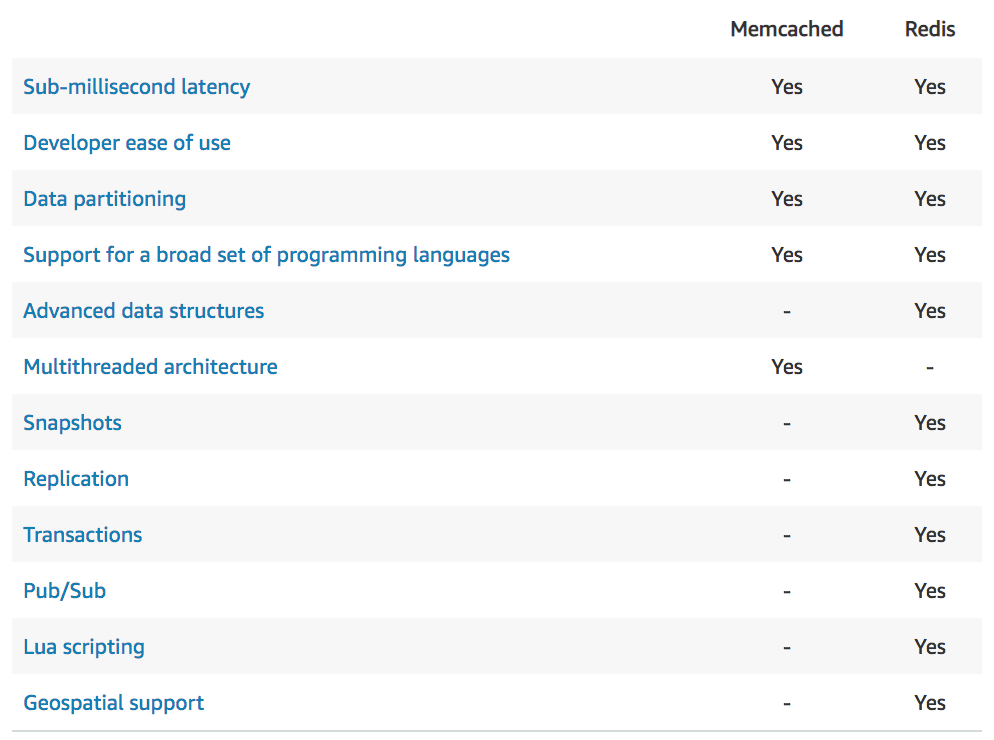
Redis vs. Memcached
Redis has replication and high availability, whereas Memcached does not. Memcached allows multi-core multi-thread however.
Redis can be token-protected (i.e. require a password). Use the AUTH command when you create the Redis instance, and in all subsequent commands.
For Redis, ElastiCache in-transit encryption is an optional feature to increase security of data in transit as it is being replicated (with performance trade-off)
Use case: accelerate autocomplete in a web page form
AWS Storage Gateway
Connect on-premises environments to AWS storage services; replace on-prem without changing workflow
primary use case is for data backup, archiving, and hybrid cloud storage scenarios
Stores data in S3 (e.g. for file gateway type, it stores files as objects in S3)
Provides a cache that can be accessed at low latency, whereas EFS and EBS do not have a cache
Copying and Converting
Use AWS Schema Conversion Tool (SCT) to convert a DB schema from one type of DB to another, e.g. from Oracle to Redshift
Use Database Migration Service (DMS) to copy database. Sometimes you do SCT convert, then DMS copy.
Use AWS DataSync to copy large amount of data from on-prem to S3, EFS, FSx, NFS shares, SMB shares, AWS Snowcone (via Direct Connect). For copying data, not databases.
Analytics (OLAP)
Redshift is a columnar data warehouse that you can use for complex querying across petabytes of structured data. It’s not serverless, it uses EC2 instances that must be running. Use Amazon RedShift Spectrum to query data from S3 using a RedShift cluster for massive parallelism
Athena is a serverless (aka inexpensive) solution to do SQL queries on S3 data and write results back. Works natively with client-side and server-side encryption. Not the same as QuickSight which is just a BI dashboard.
Amazon S3 Select – analyze and process large amounts of data faster with SQL, without moving it to a data warehouse
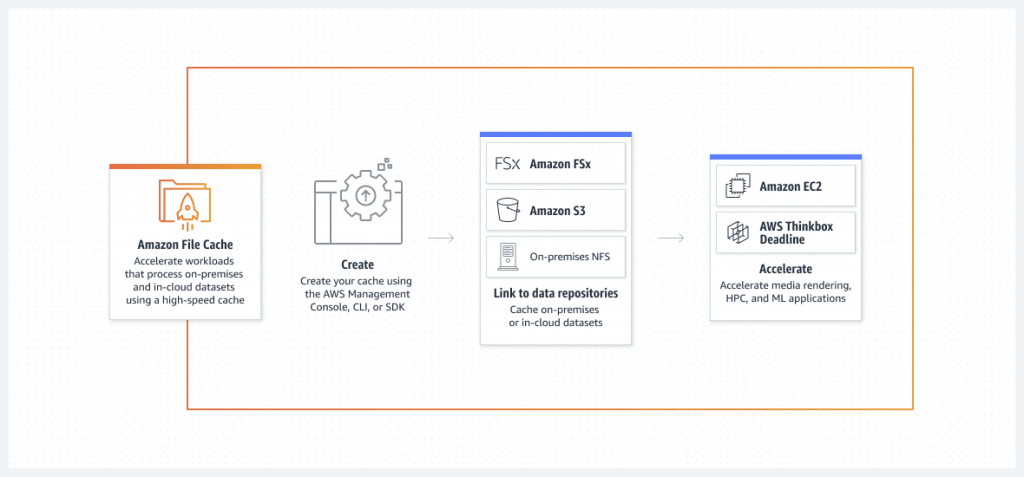
Amazon File Cache
provides a high-speed cache on AWS that makes it easier to process file data, regardless of where it’s stored