AI inference vs. training
- Training is the first phase for an AI model. Training may involve a process of trial and error, or a process of showing the model examples of the desired inputs and outputs, or both.
- Inference is the process that follows AI training. The better trained a model is, and the more fine-tuned it is, the better its inferences will be — although they are never guaranteed to be perfect.
- The core of reasoning/inference is to apply a trained AI model to new data and make decisions based on the model’s predictions.
Transformer Architecture
- used in Natural Language Processing (NLP)
- Meaning is a result of relationships between things, and self-attention is a general way of learning relationships
- A transformer is a type of artificial intelligence model that learns to understand and generate human-like text by analyzing patterns in large amounts of text data.
- They are specifically designed to comprehend context and meaning by analyzing the relationship between different elements, and they rely almost entirely on a mathematical technique called attention to do so.
- Adopts mechanism of “self-attention”
- Weighs significance of each part of the input data
- Processes sequential data (like words, like an RNN), but processes entire input all at once.
- The attention mechanism provides context, so no need to process one word at a time.
- With FFNN, it becomes parallel processing
- Model zoos such as Hugging Face offer pre-trained models to start from
- Integrated with Sagemaker via Hugging Face Deep Learning Containers (DLC)
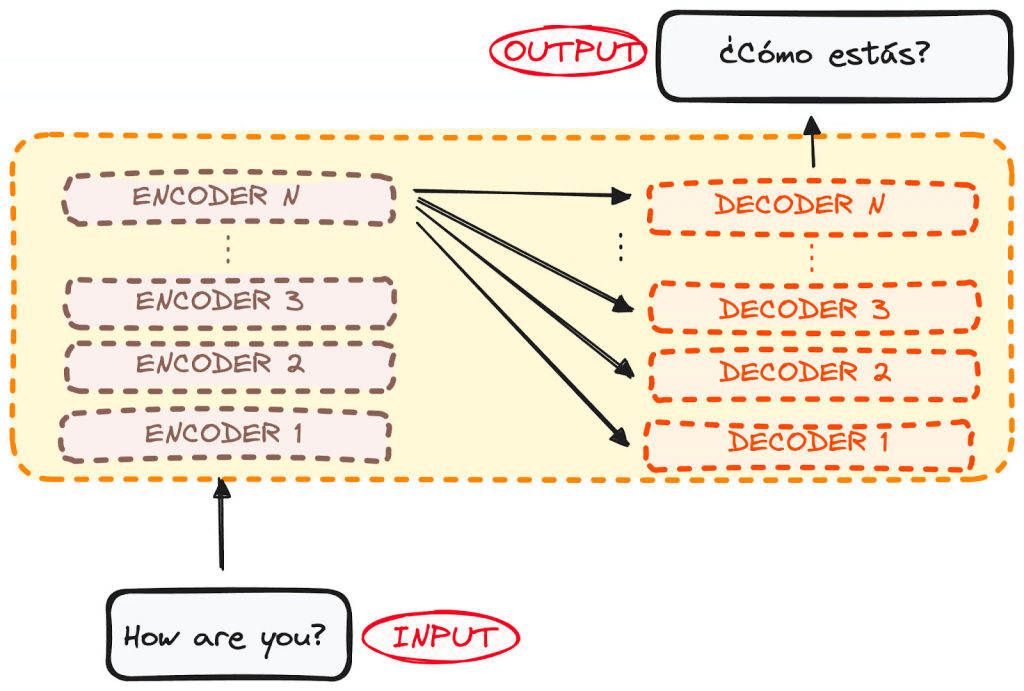
- Components
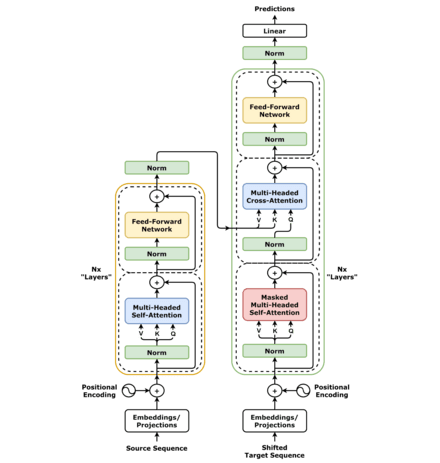
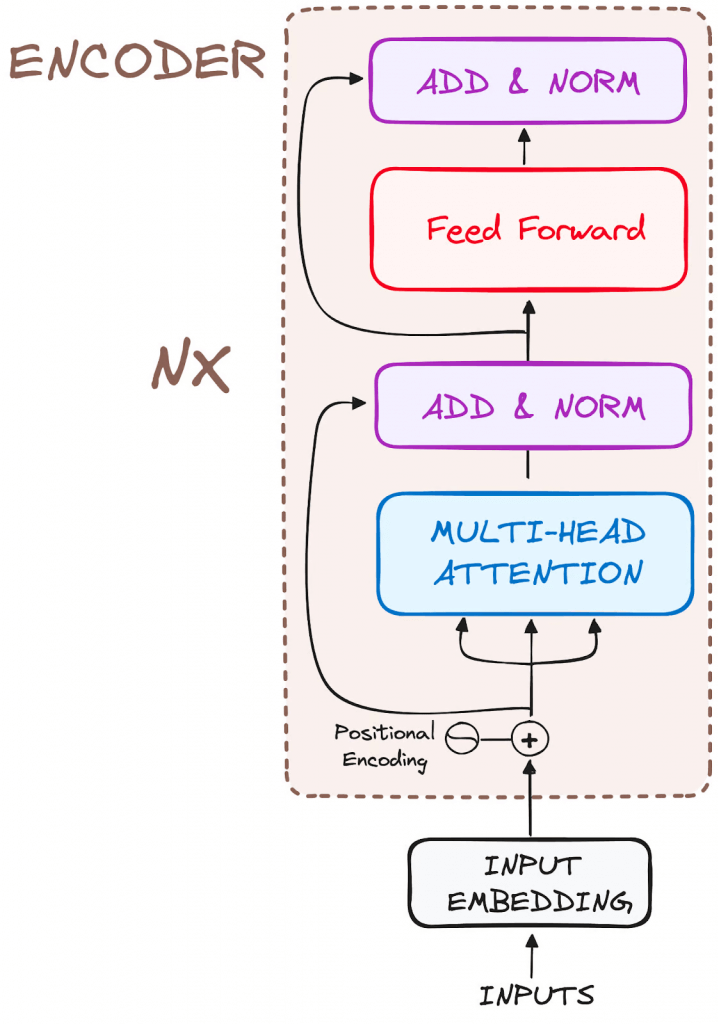
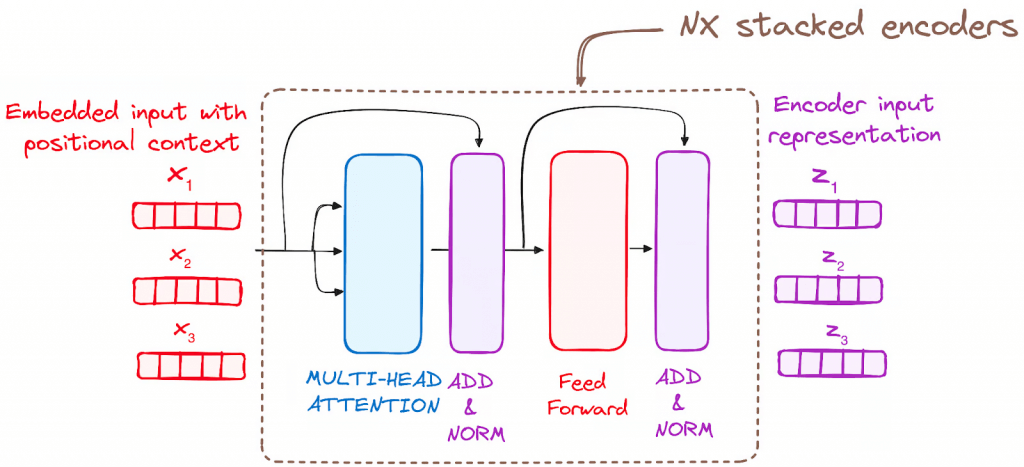
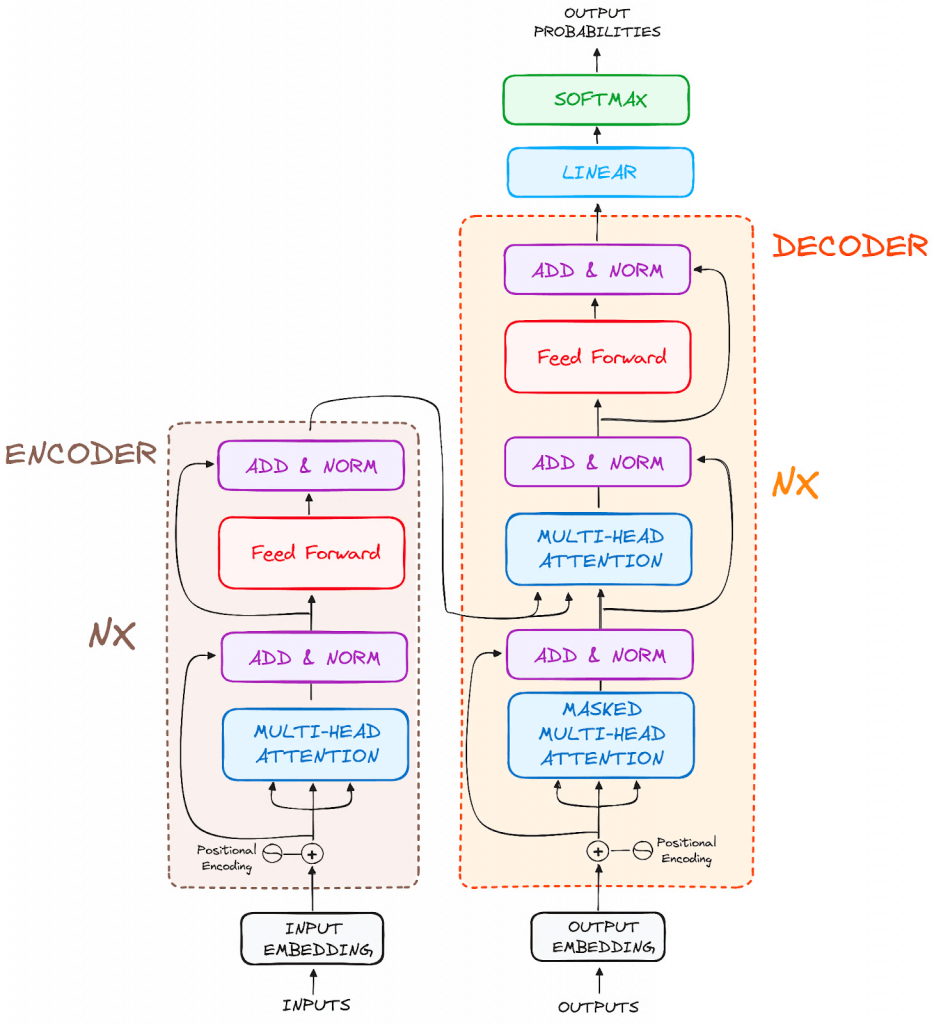
- Encoder
- to transform the input tokens into contextualized representations. Unlike earlier models that processed tokens independently, the Transformer encoder captures the context of each token with respect to the entire sequence.
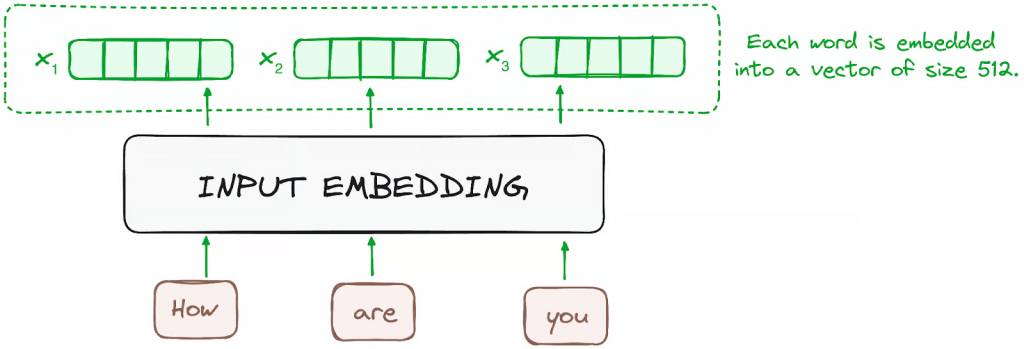
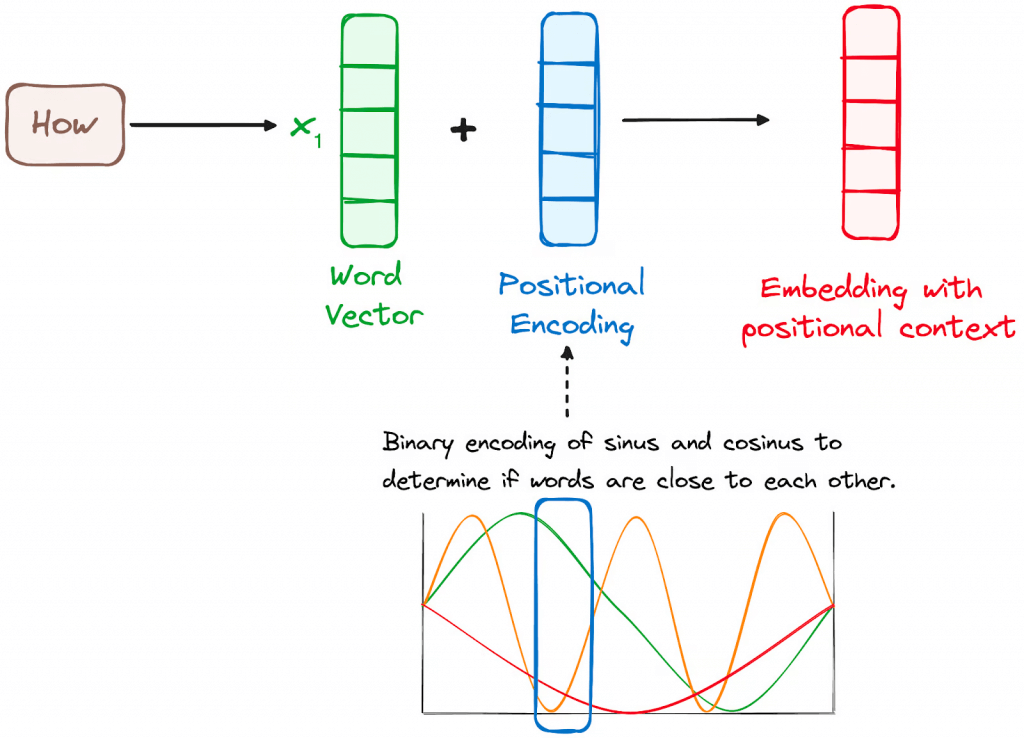
- Input Embeddings
- converting input tokens – words or subwords – into vectors using embedding layers. These embeddings capture the semantic meaning of the tokens and convert them into numerical vectors.
- Positional Encoding
- use positional encodings added to the input embeddings to provide information about the position of each token in the sequence.
- Stack of Encoder Layers
- The encoder layer serves to transform all input sequences into a continuous, abstract representation that encapsulates the learned information from the entire sequence.
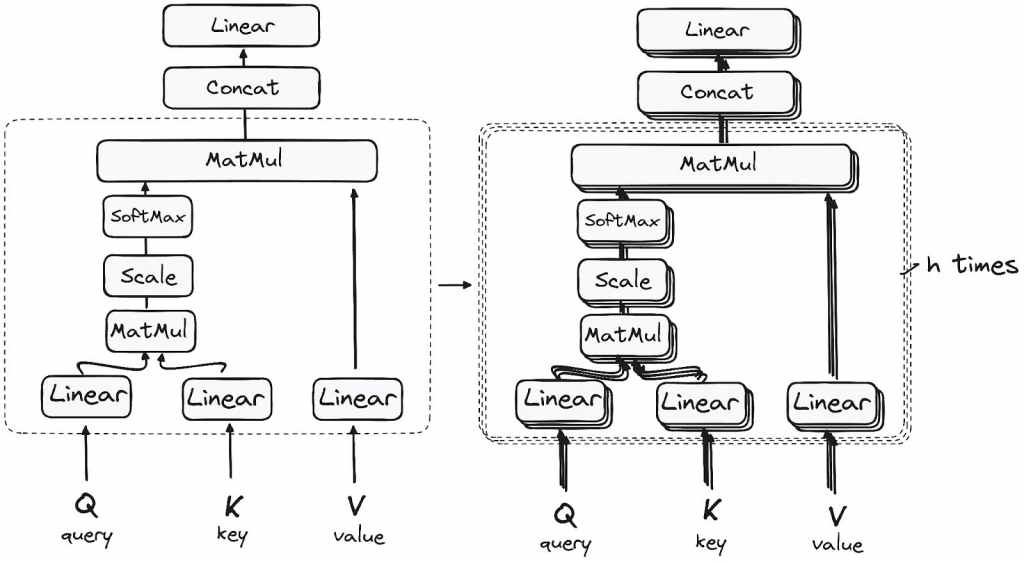
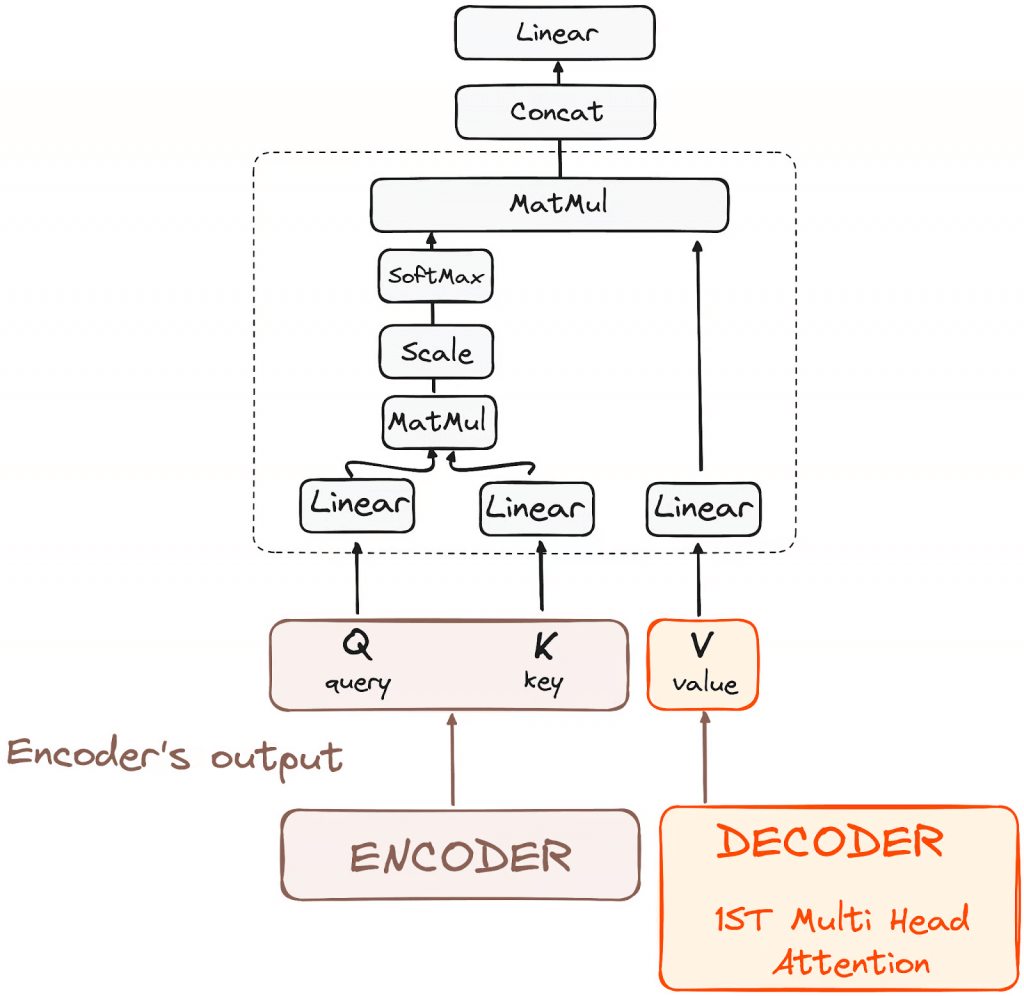
- Multi-headed attention mechanism.
- enables the models to relate each word in the input with other words
- Normalization and Residual Connections
- Feed-Forward Neural Network
- Output of the Encoder
- Multi-headed attention mechanism.
- Additionally, it incorporates residual connections around each sublayer, which are then followed by layer normalization.
- The encoder layer serves to transform all input sequences into a continuous, abstract representation that encapsulates the learned information from the entire sequence.
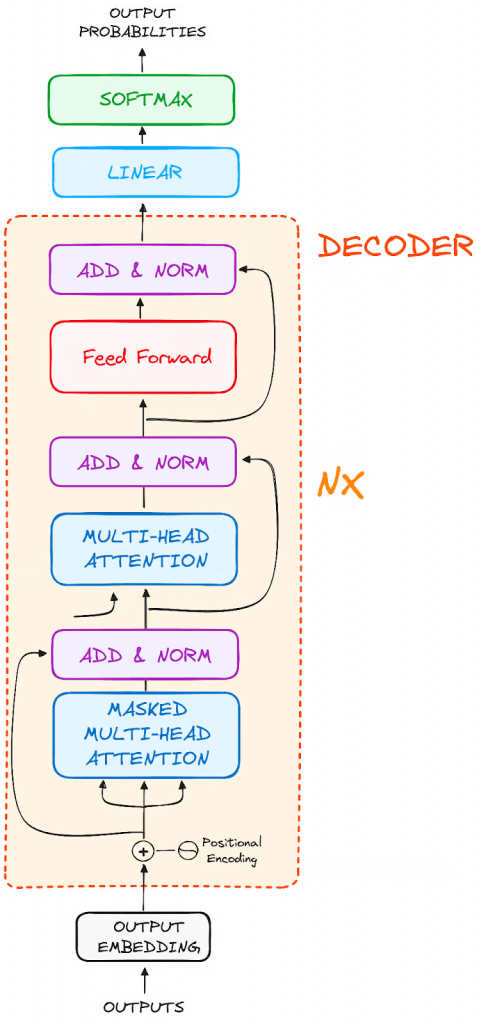
- Decoder
- Output Embeddings (mimic the Input Embeddings in Encoder)
- Positional Encoding
- Masked Self-Attention Mechanism
- Similiar with Self-Attention Mechanism in Encoder
- But, prevents positions from attending to subsequent positions, which means that each word in the sequence isn’t influenced by future tokens.
- the predictions for a particular position can only depend on known outputs at positions before it.
- Encoder-Decoder Multi-Head Attention or Cross Attention
- Feed-Forward Neural Network
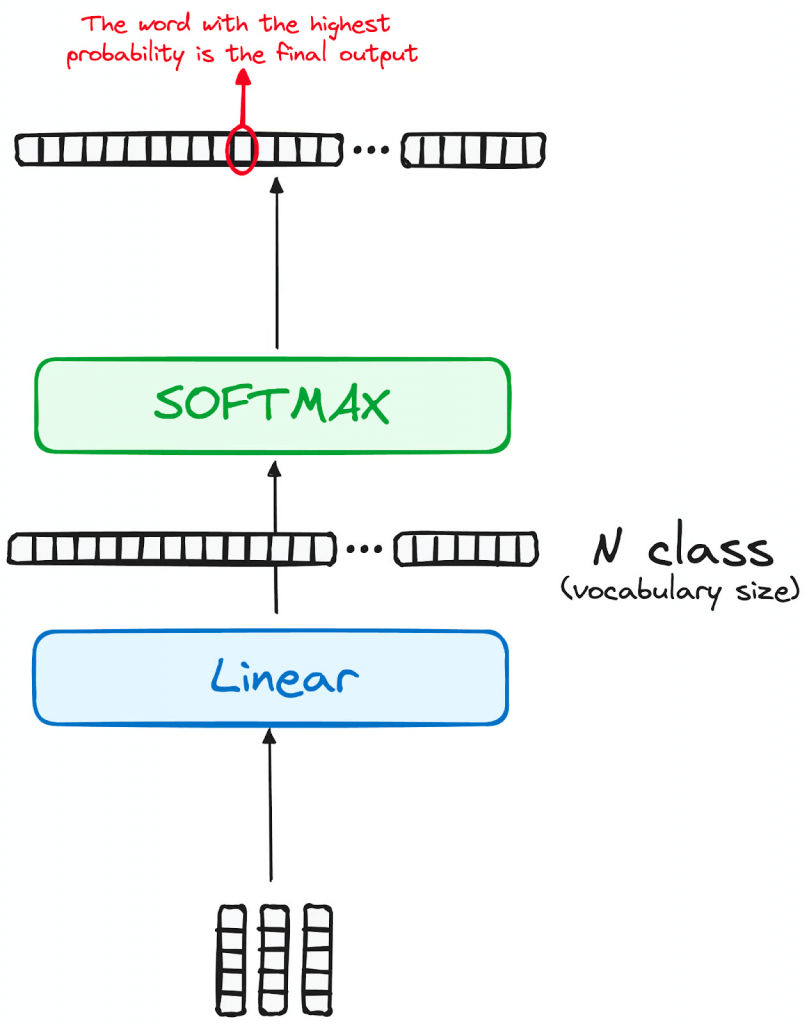
- Linear Classifier and Softmax for Generating Output Probabilities
- The journey of data through the transformer model culminates in its passage through a final linear layer, which functions as a classifier.
- The size of this classifier corresponds to the total number of classes involved (number of words contained in the vocabulary). For instance, in a scenario with 1000 distinct classes representing 1000 different words, the classifier’s output will be an array with 1000 elements.
- This output is then introduced to a softmax layer, which transforms it into a range of probability scores, each lying between 0 and 1. The highest of these probability scores is key, its corresponding index directly points to the word that the model predicts as the next in the sequence.
- Encoder
- BERT: Bi-directional Encoder Representations from Transformers
- enables the model to have more context-informed predictions about what the next word should be
- DistilBERT: uses knowledge distillation to reduce model size by 40%
- fine-tune BERT (or DistilBERT etc) with your own additional training data through transfer learning
- GPT: Generative Pre-trained Transformer
| Feature | GPT (Generative Pre-trained Transformer) | BERT (Bidirectional Encoder Representations from Transformers) |
|---|---|---|
| Core Architecture | Autoregressive, generative | Bidirectional, context-based |
| Training Approach | Predicts the next word in a sequence | Uses masked language modeling to predict words from context |
| Direction of Context | Unidirectional (forward) | Bidirectional (both forward and backward) |
| Primary Usage | Text generation | Text analysis and understanding |
| Generative Capabilities | Yes, designed to generate coherent text | No, focuses on understanding text not generating |
| Pre-training | Trained on large text corpora | Trained on large text corpora with masked words |
| Fine-tuning | Necessary for specific tasks | Necessary, but effective with fewer training examples |
| Output | Generates new text sequences | Provides contextual embeddings for various NLP tasks |
- Transfer Learning
- Continue training a pre-trained model (fine-tuning)
- Add new trainable layers to the top of a frozen model Learns to turn old features into predictions on new data
- Can do both: add new layers, then fine tune as well
- Retrain from scratch
- If you have large amounts of training data, and it’s fundamentally different from what the model was pre-trained with
- Use it as-is
- Continue training a pre-trained model (fine-tuning)
Self-Attention
- Each encoder or decoder has a list of embeddings (vectors) for each token
- Self-attention produces a weighted average of all token embeddings. The magic is in computing the attention weights.
- This results in tokens being tied to other tokens that are important for it
- Three matrices of weights are learned through back-propagation
- Query (Wq)
- Key (Wk)
- Value (Wv)
- Every token gets a query (q), key (k), and value (v) vector by multiplying its embedding against these matrices
- Compute a score for each token by multiplying (dot product) its query with each key
- “Scaled dot-product attention”
- Dot product is just one similarity function we can use.
- In practice, softmax is then applied to the scores to normalize them.