== OPERATIONS ==
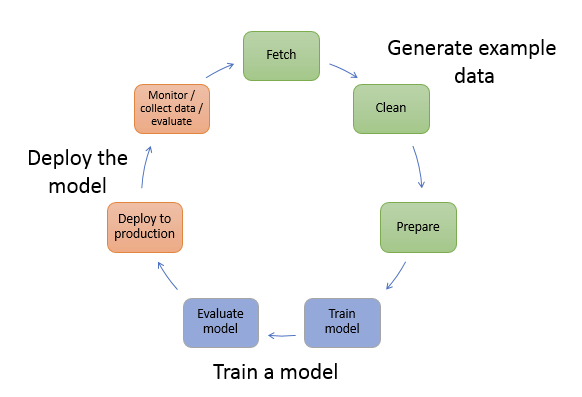
— Prepare Data —
Data prep on SageMaker
- Data Sources
- usually comes from S3
- Ideal format varies with algorithm – often it is RecordIO / Protobuf
- LibSVM is a format for representing data in a simple, text-based, and sparse format, primarily used for support vector machines (SVM).
- RecordIO/Protobuf is a binary data storage format that allows for efficient storage and retrieval of large datasets, commonly used in deep learning and data processing.
- The SageMaker AI Processing job requires specific permissions to access objects in an S3 bucket.
- If the execution role assigned to the job does not have the s3:GetObject permission for the file, it will encounter a 403 Forbidden error when trying to access the file.
- Not “SageMaker Studio”, which primarily is used for tasks within the SageMaker Studio environment.
- Ideal format varies with algorithm – often it is RecordIO / Protobuf
- also ingest from Athena, EMR, Redshift, and Amazon Keyspaces DB
- usually comes from S3
- Apache Spark integrates with SageMaker
- Scikit_learn, numpy, pandas all at your disposal within a notebook
- Processing (example)
- Copy data from S3
- Spin up a processing container
- SageMaker built-in or user provided
- Output processed data to S3
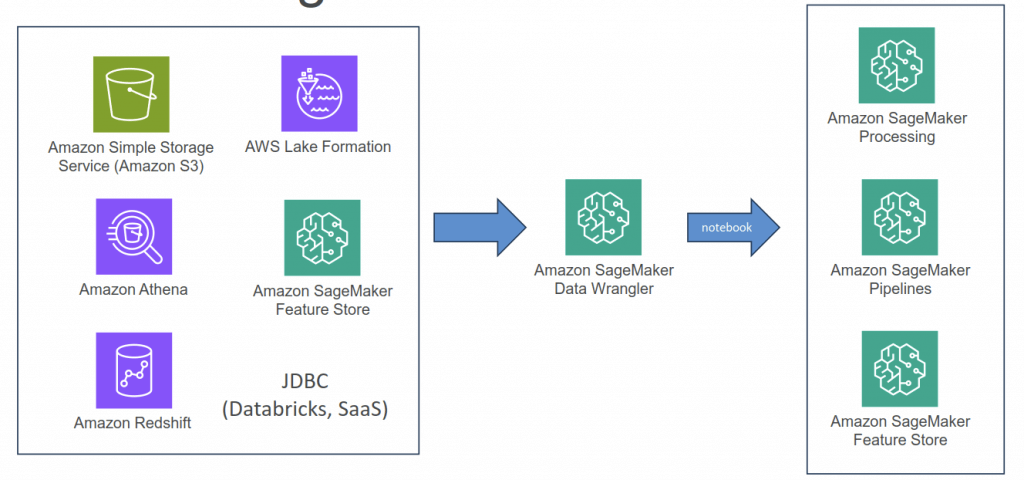
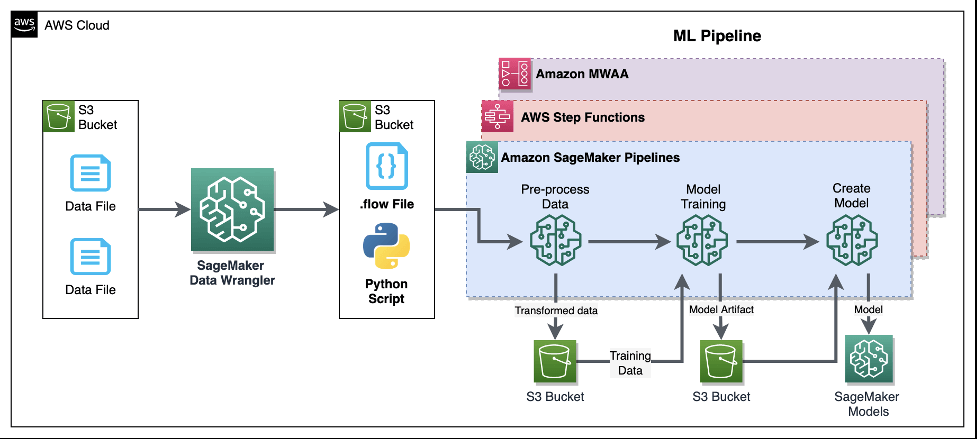
SageMaker Data Wrangler
- Visual interface (in SageMaker Studio) to prepare data for machine learning
- Import data
- Visualize data (Explore and Analysis)
- Transform data (300+ transformations to choose from)
- Or integrate your own custom xforms with pandas, PySpark, PySpark SQL
- Balance Data – create better models for binary classification
- Random oversampling
- Random undersampling
- Synthetic Minority Oversampling Technique (SMOTE)
- Reduce Dimensionality within a Dataset
- Principal Component Analysis (PCA)
- Encode Categorical – creating a numerical representation for categories
- Featurize Text ??
- Character statistics
- Vectorize
- Handle Outliers
- Robust Standard Deviation Numeric Outliers – (Q1/Q3 + n x Standard Deviation)
- Standard Deviation Numeric Outliers – only n x Standard Deviation
- Quantile Numeric Outliers – only Q1/Q3
- Min-Max Numeric Outliers – set upper and lower threshold
- Replace Rare – set a single threshold
- Handle Missing Values
- Fill missing (predefined value)
- Impute missing (mean or median, or most frequent value for categorical data)
- Drop missing (row)
- Process Numeric
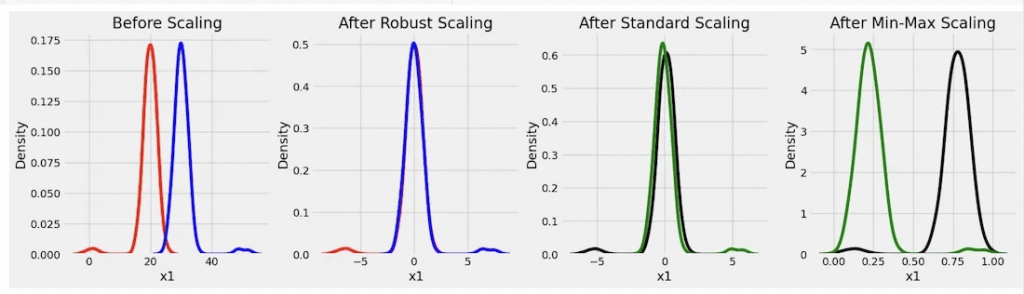
- Standard Scaler
- Robust Scaler
- removes the median and scales the data using the interquartile range (IQR), making it less vulnerable to outliers than the Standard Scaler or Min-Max Scaler
- Min Max Scaler
- Max Absolute Scaler
| Aspect | StandardScaler | Normalizer |
|---|---|---|
| Operation Basis | Feature-wise (across columns) | Sample-wise (across rows) |
| Purpose | Standardizes features to zero mean and unit variance | Scales samples to unit norm (L2 by default) |
| Impact on Data | Alters the mean and variance of each feature | Adjusts the magnitude of each sample vector |
| Common Use Cases | Regression, PCA, algorithms sensitive to variance | Text classification, k-NN, direction-focused tasks |
- preprocessing large text datasets (super on NLP tasks)
- handle various data formats
- supports common NLP preprocessing techniques
- tokenization
- stemming
- stop word removal
- “Quick Model” to train your model with your data and measure its results
- Troubleshooting
- Make sure your Studio user has appropriate IAM roles
- Make sure permissions on your data sources allow Data Wrangler access
- Add AmazonSageMakerFullAccess policy
- EC2 instance limit
- If you get “The following instance type is not available…” errors
- May need to request a quota increase
- Service Quotas / Amazon SageMaker / Studio KernelGateway Apps running on ml.m5.4xlarge instance
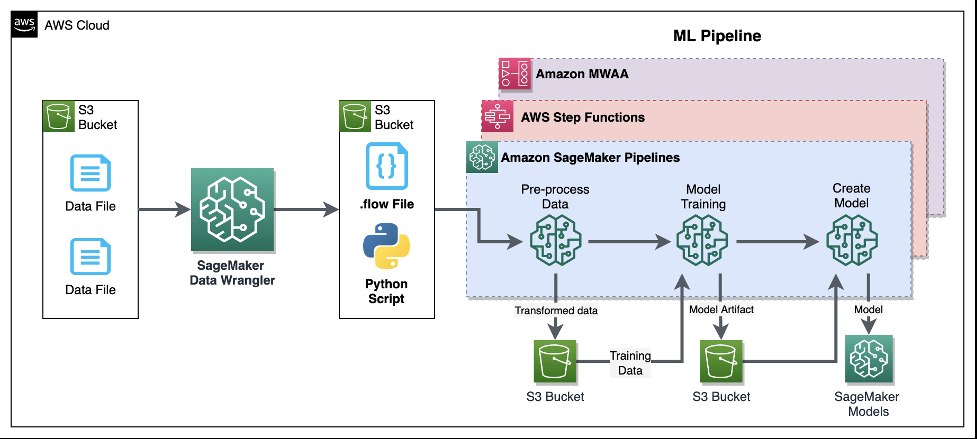
— Processing Job —
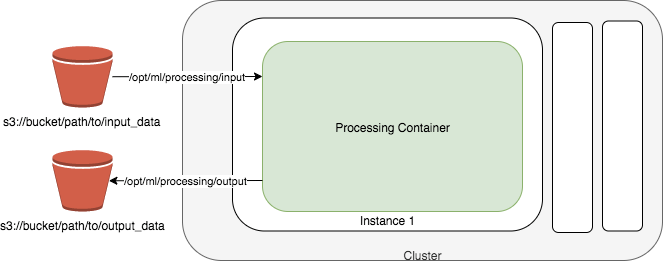
Amazon SageMaker Processing
- a fully managed service that simplifies the process of running data processing and model evaluation jobs
- run data pre and post processing, feature engineering, and model evaluation tasks on SageMaker
- built-in support for TensorFlow and Hugging Face’s Transformers and can directly interact with data stored in Amazon S3
— Feature Creation & Store —
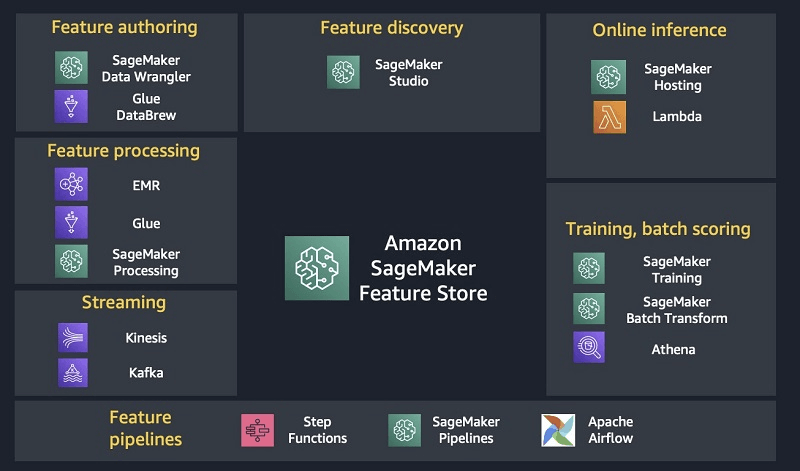
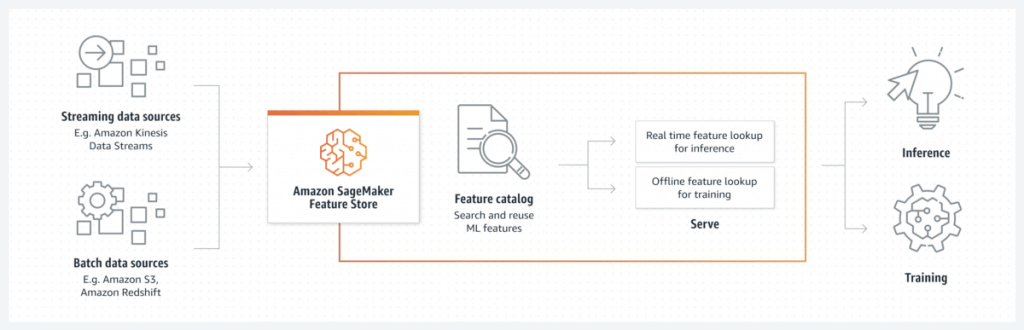
SageMaker Feature Store
- A “feature” is just a property used to train a machine learning model.
- Like, you might predict someone’s political party based on “features” such as their address, income, age, etc.
- Machine learning models require fast, secure access to feature data for training.
- keep it organized and share features across different models
- Find, discover, and share features in Studio
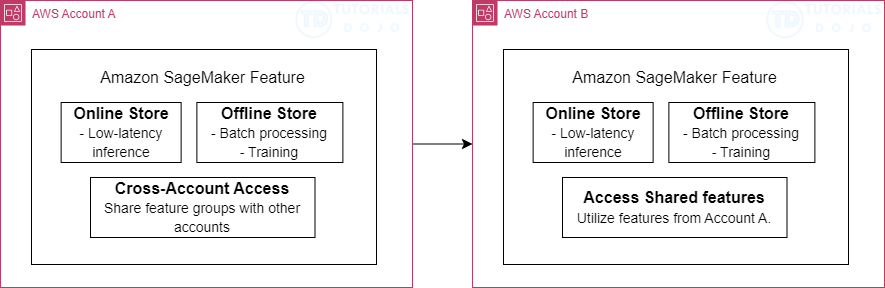
- also allows for cross-account access
- Store modes
- Online stores are typically used for low-latency access during inference
- Offline stores used for training or batch inference
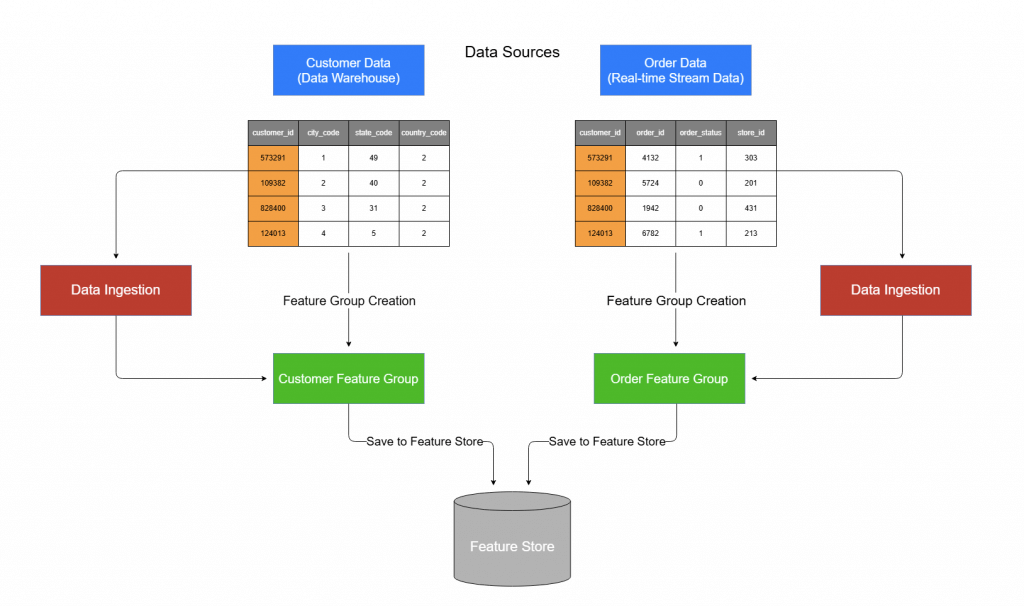
- Features organized into Feature Groups
- the primary resource within Feature Store that holds both the data and metadata used for training or making predictions with an ML model
- A feature group represents a logical collection of features that describe individual records
- Data Ingestion
- STREAMING access via PutRecord / GetRecord API’s
- BATCH access via the offline S3 store (use with anything that hits S3, like Athena, Data Wrangler. Automatically creates a Glue Data Catalog for you.)
- Security
- Encrypted at rest and in transit
- Works with KMS customer master keys
- Fine-grained access control with IAM
- May also be secured with AWS PrivateLink
- Steps
- Setup new feature store
- Define a new feature group
- organizes the features and metadata for model training and inference
- Connect with an offline store to the feature group
- an offline store, which stores historical data in Amazon S3 and supports batch processing
- Load data into the offline store using batch processing
- Define a new feature group
- Add/Update new feature into existing groups
- Utilize the UpdateFeatureGroup command to incorporate the new feature into the feature group. Specify the attribute name and type.
- Apply the PutRecord command to ingest or overwrite records, ensuring that the newly added feature has data populated across both historical and new records
- update the records that are missing data for the new attribute.
- Setup new feature store
- Create an endpoint for feature queries is for querying during inference
- Schedule regular feature updates also is for maintenance, not for new store establishment
— Model Training —
Training/Deployment on SageMaker
- Create a training job
- URL of S3 bucket with training data
- ML compute resources
- URL of S3 bucket for output
- ECR path to training code
- Training options
- Built-in training algorithms
- Spark MLLib
- Custom Python Tensorflow / MXNet code
- PyTorch, Scikit-Learn, RLEstimator
- XGBoost, Hugging Face, Chainer
- …
- Save your trained model to S3
- Can deploy two ways:
- Persistent endpoint for making individual predictions on demand
- SageMaker Batch Transform to get predictions for an entire dataset
- Lots of cool options
- Inference Pipelines for more complex processing
- SageMaker Neo for deploying to edge devices
- Elastic Inference for accelerating deep learning models
- Automatic scaling (increase # of endpoints as needed)
- Shadow Testing evaluates new models again
SageMaker Training Compiler
- Integrated into AWS Deep Learning Containers (DLCs)
- Can’t bring your own container
- Compile & optimize training jobs on GPU instances
- Can accelerate training up to 50%
- Converts models into hardware-optimized instructions
- Tested with Hugging Face transformers library, or bring your own model
- Incompatible with SageMaker distributed training libraries
- Best practices:
- Ensure GPU instances are used (ml.p3, ml.p4)
- PyTorch models must use PyTorch/XLA’s model save function
- Enable debug flag in compiler_config parameter to enable debugging
— Deploy Inference Model —
Inference Model Deployment
- getting predictions, or inferences, from your trained machine learning models
- approches
- Deploy a machine learning model in a low-code or no-code environment
- deploy pre-trained models using Amazon SageMaker JumpStart through the Amazon SageMaker Studio interface
- Use code to deploy machine learning models with more flexibility and control
- deploy their own models with customized settings for their application needs using the ModelBuilder class in the SageMaker AI Python SDK, which provides fine-grained control over various settings, such as instance types, network isolation, and resource allocation.
- Deploy machine learning models at scale
- use the AWS SDK for Python (Boto3) and AWS CloudFormation along with your desired Infrastructure as Code (IaC) and CI/CD tools
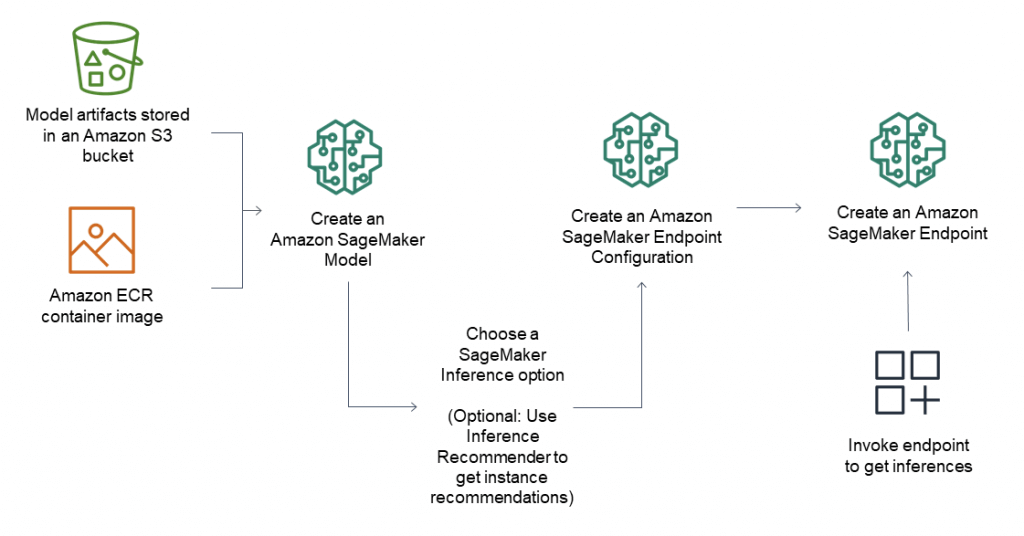
- Deploying a model to an endpoint
- Real-time inference
- ideal for inference workloads where you have interactive, low latency requirements.
- Deploy models with Amazon SageMaker Serverless Inference
- without configuring or managing any of the underlying infrastructure
- ideal for workloads which have idle periods between traffic spurts and can tolerate cold starts.
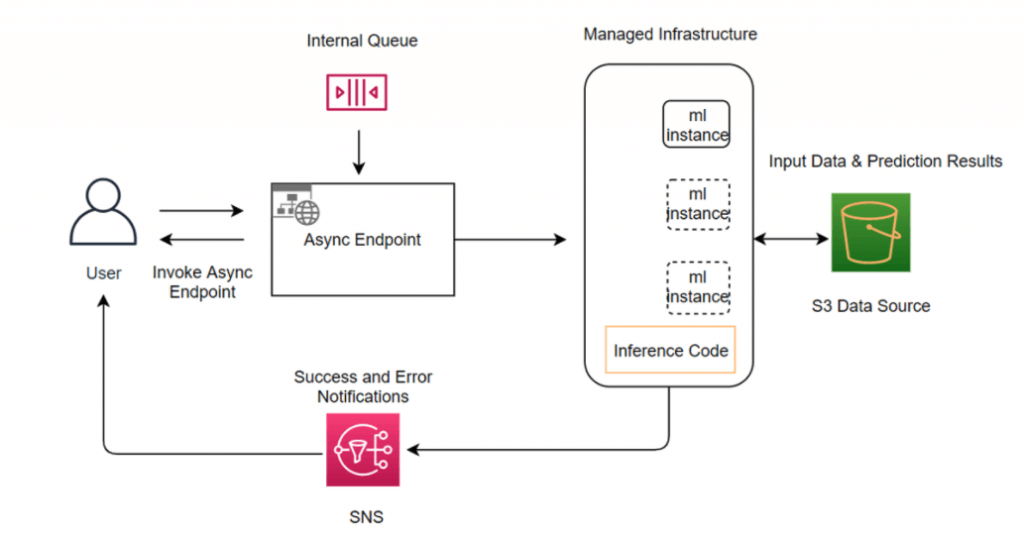
- Asynchronous inference
- queues incoming requests and processes them asynchronously
- ideal for requests with large payload sizes (up to 1GB), long processing times (up toAsynchronous Inference one hour), and near real-time latency requirements
- Real-time inference
- Cost optimization
- Model performance optimization with SageMaker Neo.
- automatically optimizing models to run in environments like AWS Inferentia chips.
- Automatic scaling of Amazon SageMaker AI models.
- Use autoscaling to dynamically adjust the compute resources for your endpoints based on incoming traffic patterns, which helps you optimize costs by only paying for the resources you’re using at a given time.
- Model performance optimization with SageMaker Neo.
- Deploy a machine learning model in a low-code or no-code environment
- Inference Modes
- Real-time inference
- inference workloads where you have real-time, interactive, low latency requirements
- (On-demand) Serverless inference
- workloads which have idle periods between traffic spurts and can tolerate cold starts.
- Asynchronous inference
- queues incoming requests and processes them asynchronously
- requests with large payload sizes (up to 1GB), long processing times (up to one hour), and near real-time latency requirements
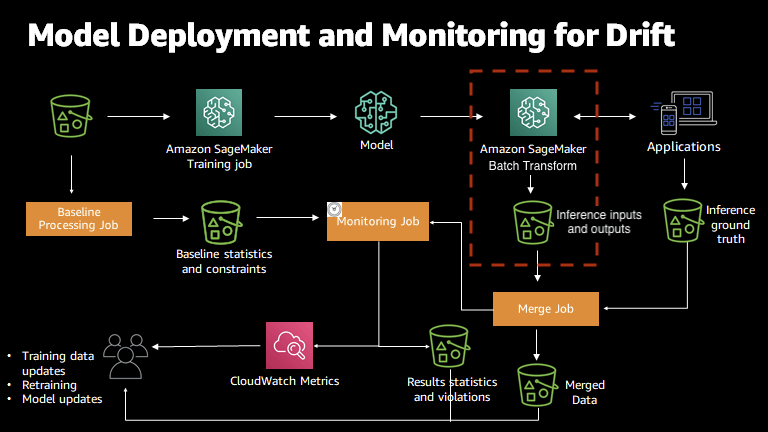
- Batch transform
- Preprocess datasets to remove noise or bias that interferes with training or inference from your dataset.
- Get inferences from large datasets.
- Run inference when you don’t need a persistent endpoint.
- Associate input records with inferences to help with the interpretation of results.
- suitable for long-term monitoring and trend analysis
- Real-time inference
- Deployment Safeguards
- Deployment Guardrails
- For asynchronous or real-time inference endpoints
- Controls shifting traffic to new models
- Blue/Green Deployments
- All at once: shift everything, monitor, terminate blue fleet
- Canary
- allows you to deploy new versions of machine learning models or applications to a small subset of users or traffic
- Linear
- Shift traffic in linearly spaced steps
- does not provide the initial small-scale rollout and evaluation phase that Canary deployment offers
- Auto-rollbacks
- Shadow Tests / Shadow deployment
- just runs the new version alongside the old version for testing without affecting live traffic
- Compare performance of shadow variant to production
- You monitor in SageMaker console and decide when to promote it
- Deployment Guardrails
| Use case 1 | Use case 2 | Use case 3 | |
|---|---|---|---|
| SageMaker AI feature | Use JumpStart in Studio to accelerate your foundational model deployment. | Deploy models using ModelBuilder from the SageMaker Python SDK. | Deploy and manage models at scale with AWS CloudFormation. |
| Description | Use the Studio UI to deploy pre-trained models from a catalog to pre-configured inference endpoints. This option is ideal for citizen data scientists, or for anyone who wants to deploy a model without configuring complex settings. | Use the ModelBuilder class from the Amazon SageMaker AI Python SDK to deploy your own model and configure deployment settings. This option is ideal for experienced data scientists, or for anyone who has their own model to deploy and requires fine-grained control. | Use AWS CloudFormation and Infrastructure as Code (IaC) for programmatic control and automation for deploying and managing SageMaker AI models. This option is ideal for advanced users who require consistent and repeatable deployments. |
| Optimized for | Fast and streamlined deployments of popular open source models | Deploying your own models | Ongoing management of models in production |
| Considerations | Lack of customization for container settings and specific application needs | No UI, requires that you’re comfortable developing and maintaining Python code | Requires infrastructure management and organizational resources, and also requires familiarity with the AWS SDK for Python (Boto3) or with AWS CloudFormation templates. |
| Recommended environment | A SageMaker AI domain | A Python development environment configured with your AWS credentials and the SageMaker Python SDK installed, or a SageMaker AI IDE such as SageMaker JupyterLab | The AWS CLI, a local development environment, and Infrastructure as Code (IaC) and CI/CD tools |
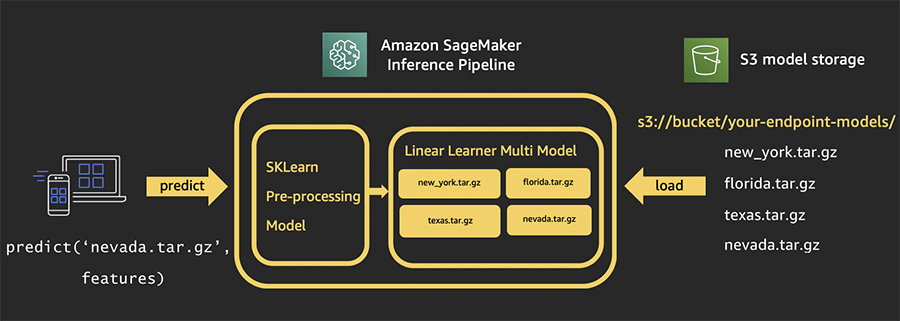
Inference Pipelines
- Linear sequence of 2-15 containers
- Any combination of pre-trained built-in algorithms or your own algorithms in Docker containers
- Combine pre-processing, predictions, post-processing
- Spark ML and scikit-learn containers OK
- Spark ML can be run with Glue or EMR
- Serialized into MLeap format
- Can handle both real-time inference and batch transforms
— Quality Monitor —
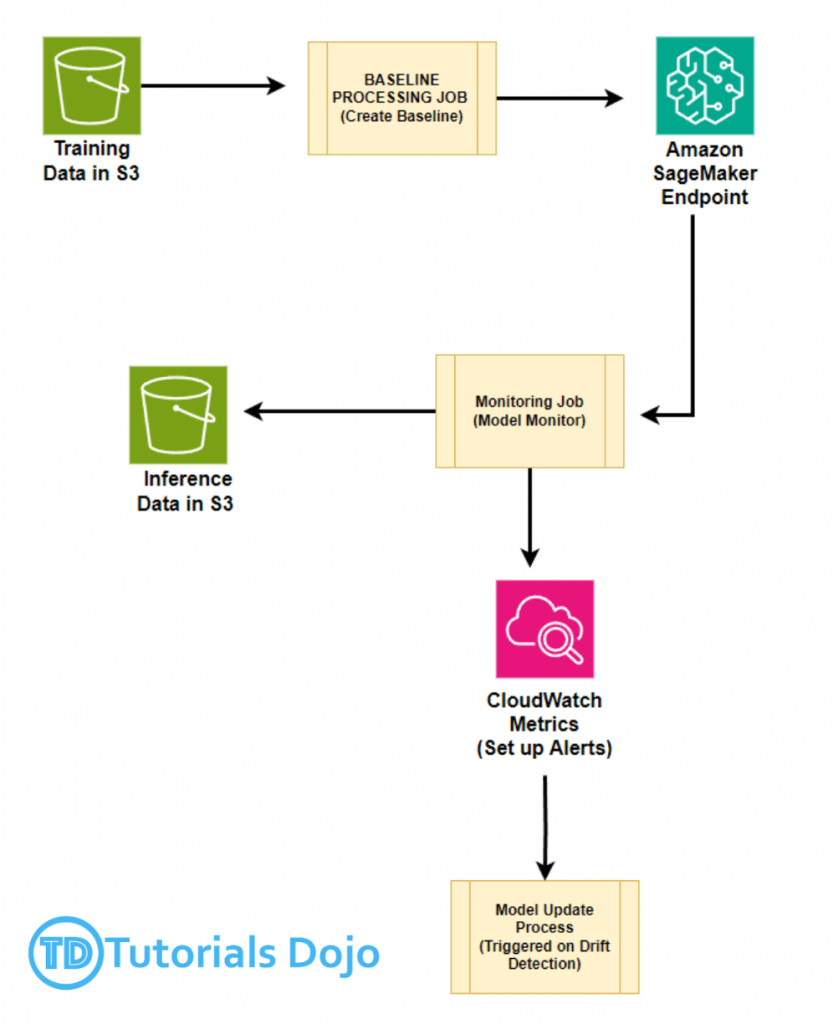
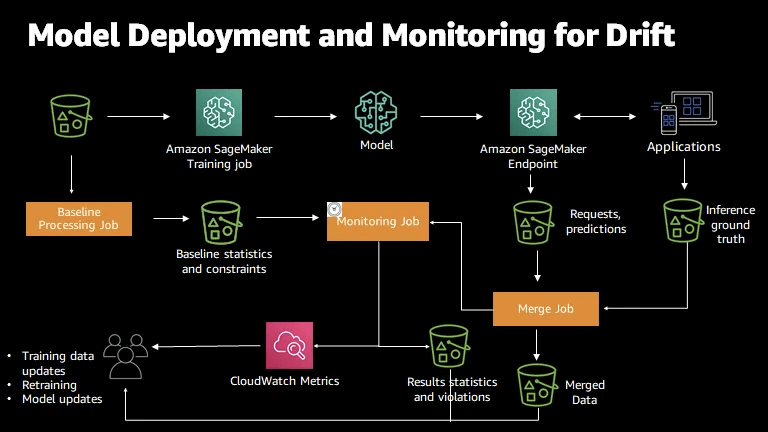
SageMaker Model Monitor
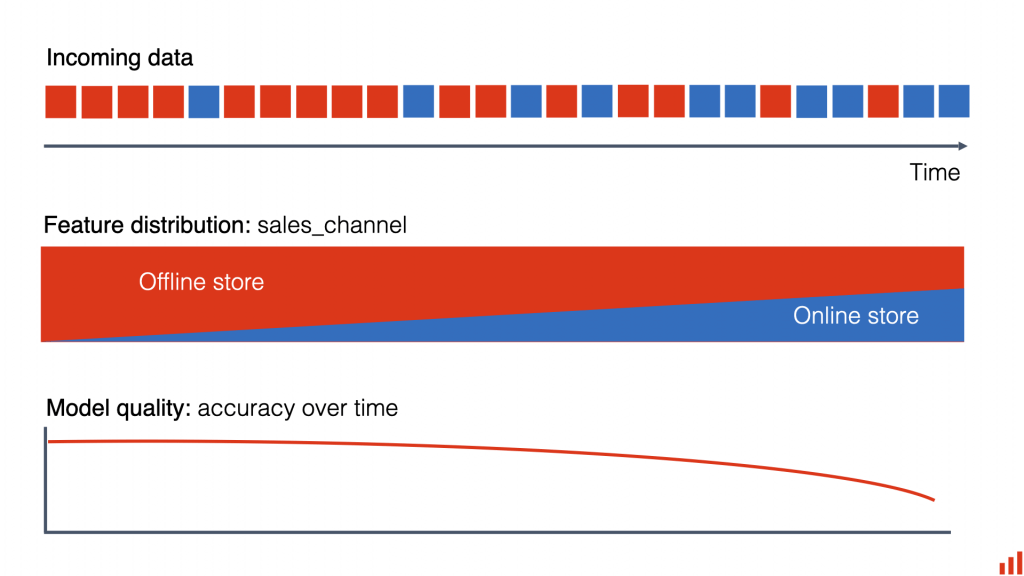
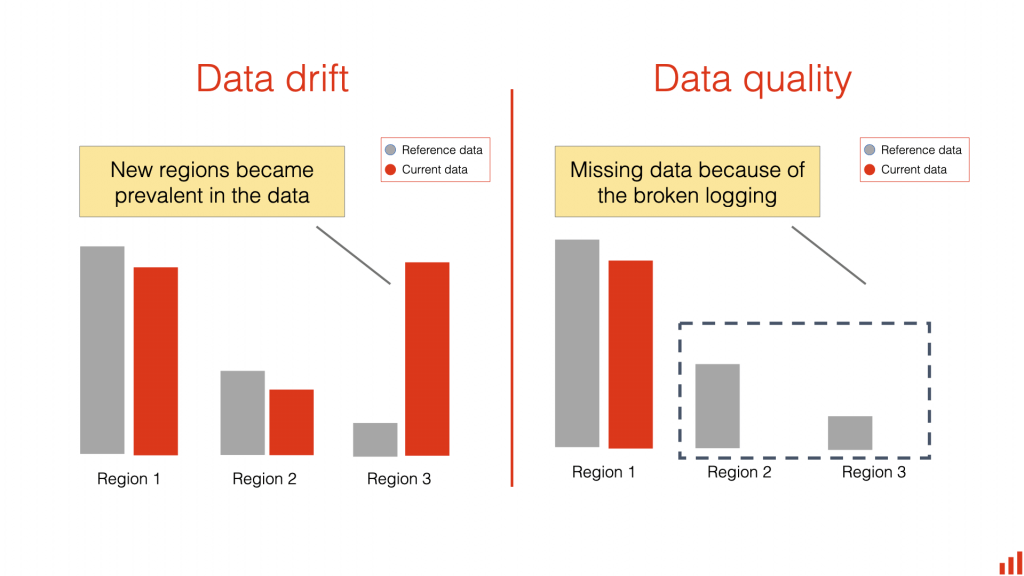
- Data Drift is the phenomenon where the distribution of the input data changes over time, potentially leading to degraded model performance
- Monitors
- Data quality – Monitor drift in data quality.
- the statistical properties of input data change over time, resulting in a decrease in model accuracy.
- for example, changes in patient demographics and conditions reflects a shift in data distribution
- Solution: use Amazon SageMaker Model Monitor, which continuously monitors the data quality of deployed models. This allows data scientists and machine learning engineers to detect drifts in real-time and take corrective actions.
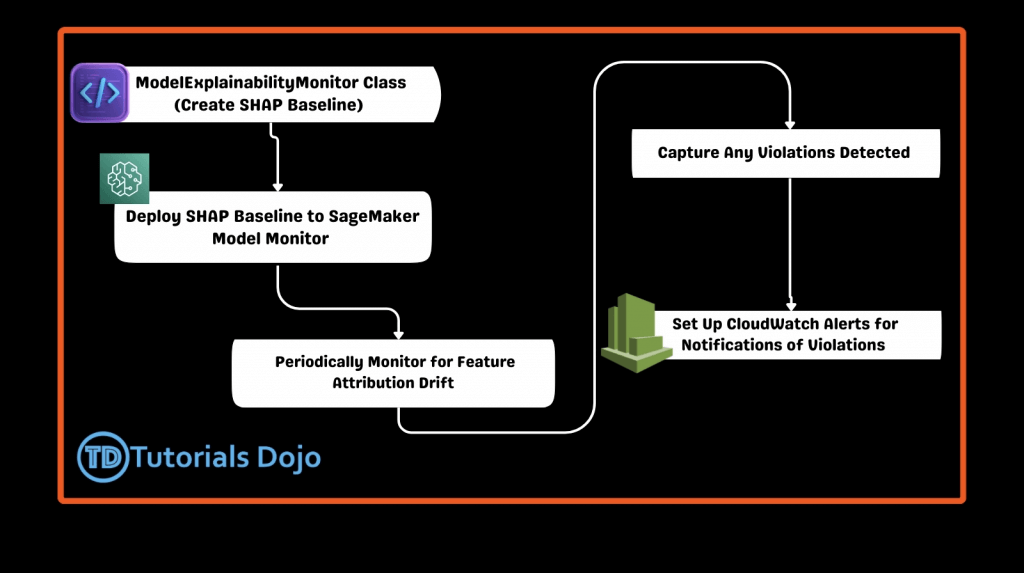
- Use the ModelDataQualityMonitor class to establish a baseline for input data quality. Deploy the baseline to SageMaker Model Monitor to track changes in data patterns and set up notifications in CloudWatch for any detected deviations as primarily used to track the quality of input data and its distribution but does not monitor the importance of features in model predictions
- the statistical properties of input data change over time, resulting in a decrease in model accuracy.
- Model quality – Monitor drift in model quality metrics, such as accuracy.
- Create a performance baseline using the ModelPerformanceMonitor class. Deploy this baseline to SageMaker Model Monitor and configure it to track the model’s prediction accuracy and trigger alerts if any major variations occur as only tracks the overall performance of the model (such as accuracy or precision)
- Bias drift for models in production – Monitor bias in your model’s predictions.
- a predictive model starts to favor specific groups over others because of changes in data distribution or model parameters. This can lead to imbalanced outcomes.
- for example, Disproportionate flagging of certain patient groups indicates bias
- Solution: use Amazon SageMaker Clarify, detect and explain biases in machine learning models. It offers tools to assess and comprehend bias in the data and model predictions, ensuring the model maintains fairness and equality across various demographic groups.
- Create a baseline for monitoring bias using the ModelBiasMonitor class. Deploy this baseline to SageMaker Model Monitor and periodically check for bias drift. Set up Amazon CloudWatch to send alerts when violations are detected; mainly for identifying bias in predictions related to specific attributes such as gender or race, not changes in feature attribution between inputs
- a predictive model starts to favor specific groups over others because of changes in data distribution or model parameters. This can lead to imbalanced outcomes.
- Feature attribution drift for models in production – Monitor drift in feature attribution.
- the significance of various features in a predictive model changes over time. This can happen when the relationships between features and outcomes evolve.
- for example, changing impacts of various health factors
- Explainability includes the ability to detail which features contribute the most to a model prediction for a specific input, or feature attribution. These details can help determine if a particular model input has more influence than expected on overall model behavior.
- Solution: use Amazon SageMaker Clarify, assist in understanding feature attribution by offering feature importance scores. This helps data scientists monitor and handle changes in feature importance over time, ensuring that the model continues to generate accurate and reliable predictions.
- The ModelExplainabilityMonitor leverages SHAP (Shapley Additive Explanations) values to track the contribution of each feature. This feature attribution monitoring ensures that if a model begins to emphasize one input (such as driving history) more than another (like age), it can be detected and trigger alerts in Amazon CloudWatch
- the significance of various features in a predictive model changes over time. This can happen when the relationships between features and outcomes evolve.
- (NOT) Virtual Drift , typically refers to a situation where the model’s performance degrades due to operational issues, such as infrastructure or deployment changes.
- Data quality – Monitor drift in data quality.
- Get alerts on quality deviations on your deployed models (via CloudWatch)
- Visualize data drifts
- Detect anomalies & outliers
- Detect new features
- No code needed
- Could “analyze the training data and generate a baseline of statistics and constraints from processed data”
- Integrates with SageMaker Clarify for bias detection and data drift monitoring
- Data is stored in S3 and secured
- Monitoring jobs are scheduled via a Monitoring Schedule
- Metrics are emitted to CloudWatch
- CloudWatch notifications can be used to trigger alarms
- You’d then take corrective action (retrain the model, audit the data)
- Integrates with Tensorboard, QuickSight, Tableau
- Or just visualize within SageMaker Studio
| Meaning | Activity | |
| Data quality drift | production data distribution differs from that used for training | missing values or errors in the data |
| Model quality drift | predictions that a model makes differ from actual Ground Truth labels that the model attempts to predict | monitor the performance of a model by comparing the predictions that the model makes with the actual ground truth labels that the model attempts to predict |
| Bias drift | introduction of bias due to change in production data distribution or application | statistical changes in the data distribution, even if the data has high quality |
| Feature attribution drift | ranking of individual features changed from training data to live data | detect feature attribution drift by comparing how the ranking of the individual features changed from training data to live data |
SageMaker Clarify
- detects potential bias, i.e., imbalances across different groups / ages / income brackets
- “Biases in the training data can lead to inaccurate predictions”
- works as “diagnostic” tool, could directly address the root cause of inaccuracies in the training data or model
- help you understand why your ML model made a specific prediction
- and whether bias impacted this prediction during training or inference
- Also provides tools to help build less biased and more understandable models
- and can generate model governance reports for risk and compliance teams and external regulators.
- To setup a SageMaker Clarify processing job, for configuring the processing container, job inputs, outputs, resources, and other parameters
- OPTION ONE: use the SageMaker CreateProcessingJob API
- OPTION TWO: the SageMaker Python SDK API, SageMaker ClarifyProcessor
- With Model Monitor, you can monitor for bias and be alerted to new potential bias via CloudWatch
- SageMaker Clarify also helps explain model behavior
- Understand which features contribute the most to your predictions
- analyzes the model’s predictions on inference data and explains
- Pre-training Bias Metrics
- to identify and address potential biases within a dataset before the model is trained
- Class Imbalance (CI)
- One facet (demographic group) has fewer training values than another
- Difference in Proportions of Labels (DPL)
- Imbalance of positive outcomes between facet values
- Kullback-Leibler Divergence (KL), Jensen-Shannon Divergence(JS)
- How much outcome distributions of facets diverge
- Lp-norm (LP)
- P-norm difference between distributions of outcomes from facets
- Total Variation Distance (TVD)
- L1-norm difference between distributions of outcomes from facets
- Kolmogorov-Smirnov (KS)
- Maximum divergence between outcomes in distributions from facets
- Conditional Demographic Disparity (CDD)
- Disparity of outcomes between facets as a whole, and by subgroups
| Bias metric | Description | Example question | Futher Example |
|---|---|---|---|
| Class Imbalance (CI) | Measures the imbalance in the number of members between different facet values. | Could there be age-based biases due to not having enough data for the demographic outside a middle-aged facet? | For instance, if one gender is significantly underrepresented, CI will reveal this imbalance, which could lead to biased predictions that favor the more represented class. Addressing such imbalances is important to ensure that the model learns fairly from all data groups. |
| Difference in Proportions of Labels (DPL) | Measures the imbalance of positive outcomes between different facet values. | Could there be age-based biases in ML predictions due to biased labeling of facet values in the data? | For example, if a model predicts higher success rates for one racial group compared to another, DPL will highlight this discrepancy, indicating a potential bias in outcomes. Analyzing DPL can make adjustments to the model or dataset to reduce such disparities and promote fairness. |
| Kullback-Leibler Divergence (KL) | Measures how much the outcome distributions of different facets diverge from each other entropically. primarily measures the divergence between two probability distributions often used to compare the distribution of outcomes across different groups | How different are the distributions for loan application outcomes for different demographic groups? | typically used in broader contexts of distribution comparisons and might not provide a direct assessment of bias related to demographic attributes. |
| Jensen-Shannon Divergence (JS) | Measures how much the outcome distributions of different facets diverge from each other entropically. primarily measures the divergence between two probability distributions often used to compare the distribution of outcomes across different groups | How different are the distributions for loan application outcomes for different demographic groups? | typically used in broader contexts of distribution comparisons and might not provide a direct assessment of bias related to demographic attributes. |
| Lp-norm (LP) | Measures a p-norm difference between distinct demographic distributions of the outcomes associated with different facets in a dataset. | How different are the distributions for loan application outcomes for different demographics? | It’s a critical metric for identifying how much the predicted outcomes for one group differ from another, thus helping to assess bias in the model’s predictions. |
| Total Variation Distance (TVD) | Measures half of the L1-norm difference between distinct demographic distributions of the outcomes associated with different facets in a dataset. TVD quantifies the divergence in outcome distributions between different demographic groups | How different are the distributions for loan application outcomes for different demographics? | It’s a critical metric for identifying how much the predicted outcomes for one group differ from another, thus helping to assess bias in the model’s predictions. |
| Kolmogorov-Smirnov (KS) | Measures maximum divergence between outcomes in distributions for different facets in a dataset. | Which college application outcomes manifest the greatest disparities by demographic group? | It’s a critical metric for identifying how much the predicted outcomes for one group differ from another, thus helping to assess bias in the model’s predictions. |
| Conditional Demographic Disparity (CDD) | Measures the disparity of outcomes between different facets as a whole, but also by subgroups. | Do some groups have a larger proportion of rejections for college admission outcomes than their proportion of acceptances? | It’s a critical metric for identifying how much the predicted outcomes for one group differ from another, thus helping to assess bias in the model’s predictions. |
== IMPLEMENTATIONS ==
— Docker Container —
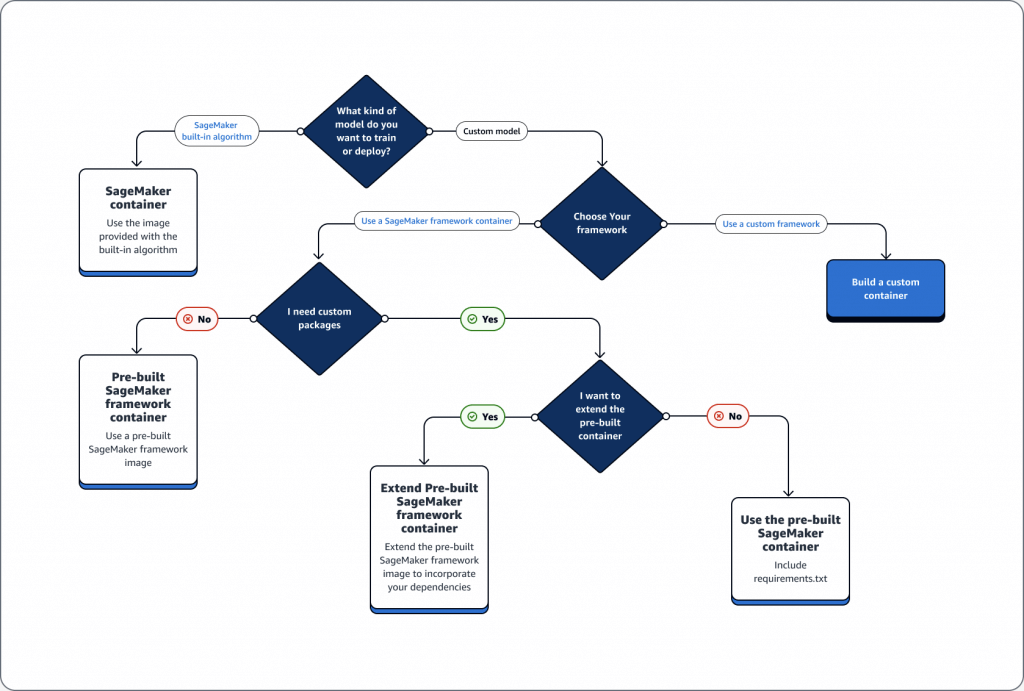
SageMaker and Docker Containers
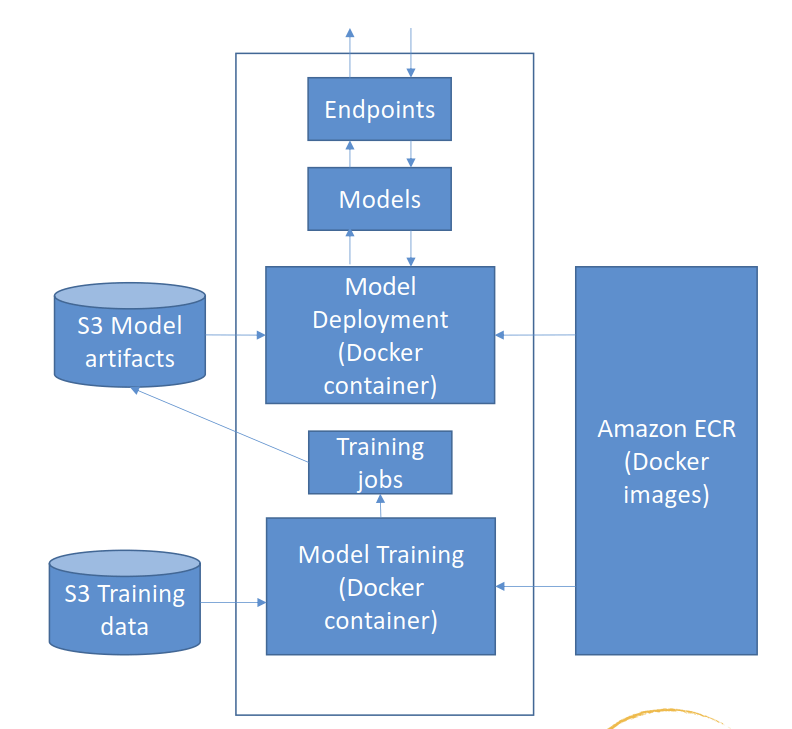
- All models in SageMaker are hosted in Docker containers
- Docker containers are created from images
- Images are built from a Dockerfile
- Images are saved in a repository
- Amazon Elastic Container Registry (ECR)
- Recommended to wrap the custom codes into custom Docker container, push it to the Amazon Elastic Container Registry (Amazon ECR), and use it as a processing container in SageMaker AI
- Amazon SageMaker Containers
- Library for making containers compatible with SageMaker
- RUN
pip install sagemaker-containersin your Dockerfile
- Environment variables
- SAGEMAKER_PROGRAM
- Run a script inside /opt/ml/code
- SAGEMAKER_TRAINING_MODULE
- SAGEMAKER_SERVICE_MODULE
- SM_MODEL_DIR
- SM_CHANNELS / SM_CHANNEL_*
- SM_HPS / SM_HP_*
- SM_USER_ARGS
- SAGEMAKER_PROGRAM
- Production Variants
- test out multiple models on live traffic using Production Variants
- Variant Weights tell SageMaker how to distribute traffic among them
- So, you could roll out a new iteration of your model at say 10% variant weight
- Once you’re confident in its performance, ramp it up to 100%
- do A/B tests, and to validate performance in real-world settings
- Offline validation isn’t always useful
- Shadow Variants
- Deployment Guardrails
- test out multiple models on live traffic using Production Variants
— Machine Learning Operations (MLOps) —
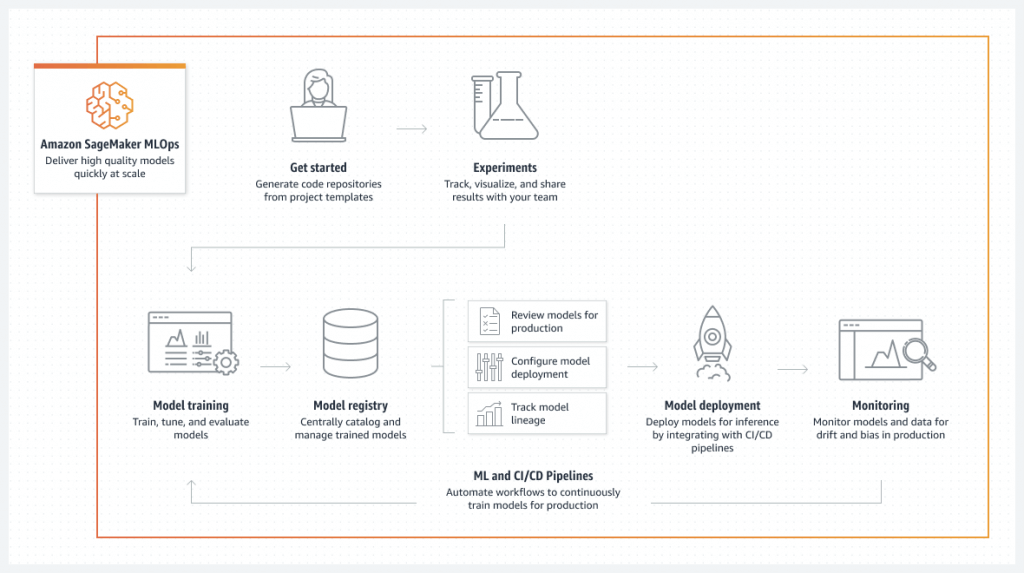
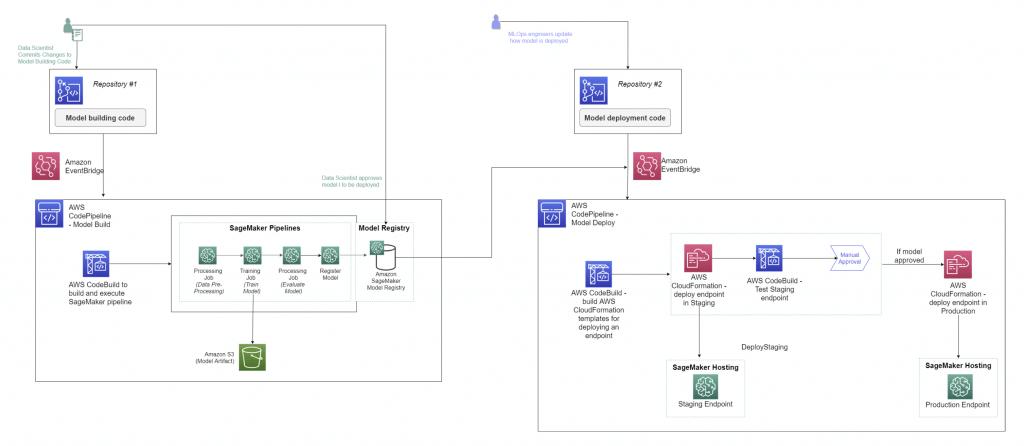
SageMaker Projects
- set up dependency management, code repository management, build reproducibility, and artifact sharing
- SageMaker Studio’s native MLOps solution with CI/CD
- Build images
- Prep data, feature engineering
- Train models
- Evaluate models
- Deploy models
- Monitor & update models
- Uses code repositories for building & deploying ML solutions
- Uses SageMaker Pipelines defining steps

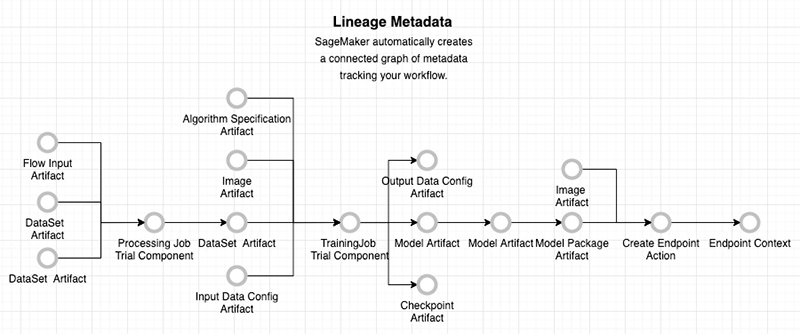
SageMaker ML Lineage Tracking (EOL on 2024/25)
- Model lineage graphs
- Creates & stores your ML workflow (MLOps)
- a visualization of your entire ML workflow from data preparation to deployment
- use entities to represent individual steps in your workflow
- Keep a running history of your models
- Tracking for auditing and compliance
- Automatically or manually-created tracking entities
- Integrates with AWS Resource Access Manager for cross-account lineage
- Entities
- Trial component (processing jobs, training jobs, transform jobs)
- Trial (a model composed of trial components)
- Experiment (a group of Trials for a given use case)
- Context (logical grouping of entities)
- Action (workflow step, model deployment
- Artifact (Object or data, such as an S3 bucket or an image in ECR)
- Association (connects entities together) – has optional AssociationType:
- ContributedTo
- AssociatedWith
- DerivedFrom
- Produced
- SameAs
- Querying
- Use the LineageQuery API from Python
- Part of the Amazon SageMaker SDK for Python
- Do things like find all models / endpoints / etc. that use a given artifact
- Produce a visualization
- Requires external Visualizer helper class
- Use the LineageQuery API from Python
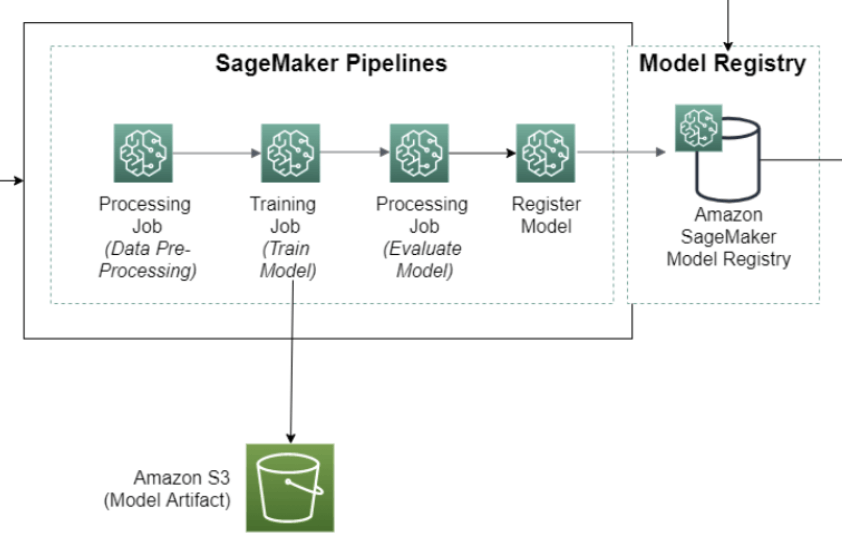
Amazon SageMaker (ML) Pipeline
- allows you to create, automate, and manage end-to-end ML workflows
- consists of multiple steps, each representing a specific task or operation in the ML workflow.
- data processing
- model training
- model evaluation
- model deployment
- series of interconnected steps in directed acyclic graph (DAG)
- UI or can using the pipeline definition JSON schema
- composed of
- name
- parameters
- steps
- A step property is an attribute of a step that represents the output values from a step execution
- For a step that references a SageMaker job, the step property matches the attributes of that SageMaker job
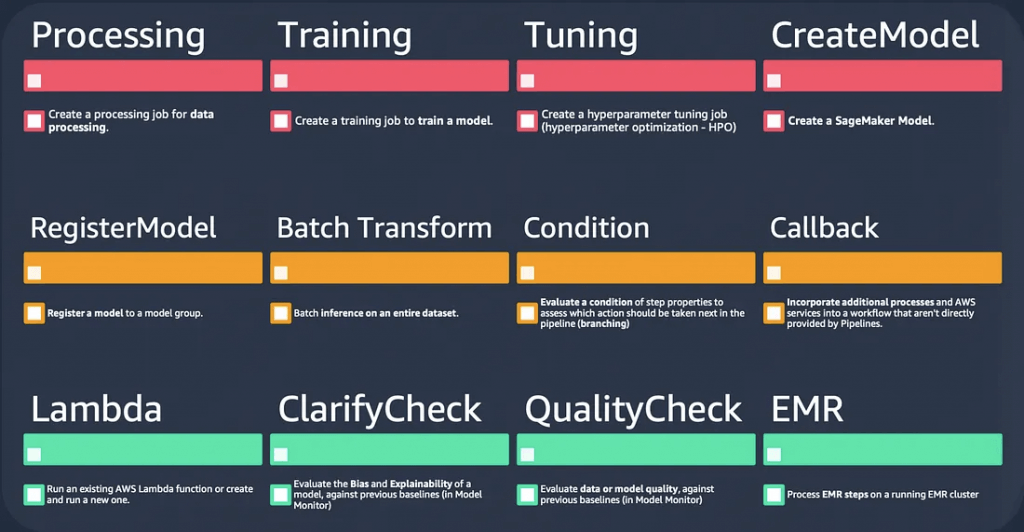
- ProcessingStep
- TrainingStep
- TransformStep
- TuningStep
- AutoMLStep
- ModelStep
- CallbackStep
- LambdaStep
- ClarifyCheckStep
- QualityCheckStep
- EMRStep
- @step decorator : custom ML job
- define custom logic within a pipeline step and ensure it works seamlessly within the workflow
- example, create a simple python function to do data validation
- @remote decorator : remote function calls
- It simplifies the execution of machine learning workflows by allowing you to run code remotely in a SageMaker environment, making it easier to scale your workloads, distribute computations, and leverage SageMaker infrastructure efficiently.

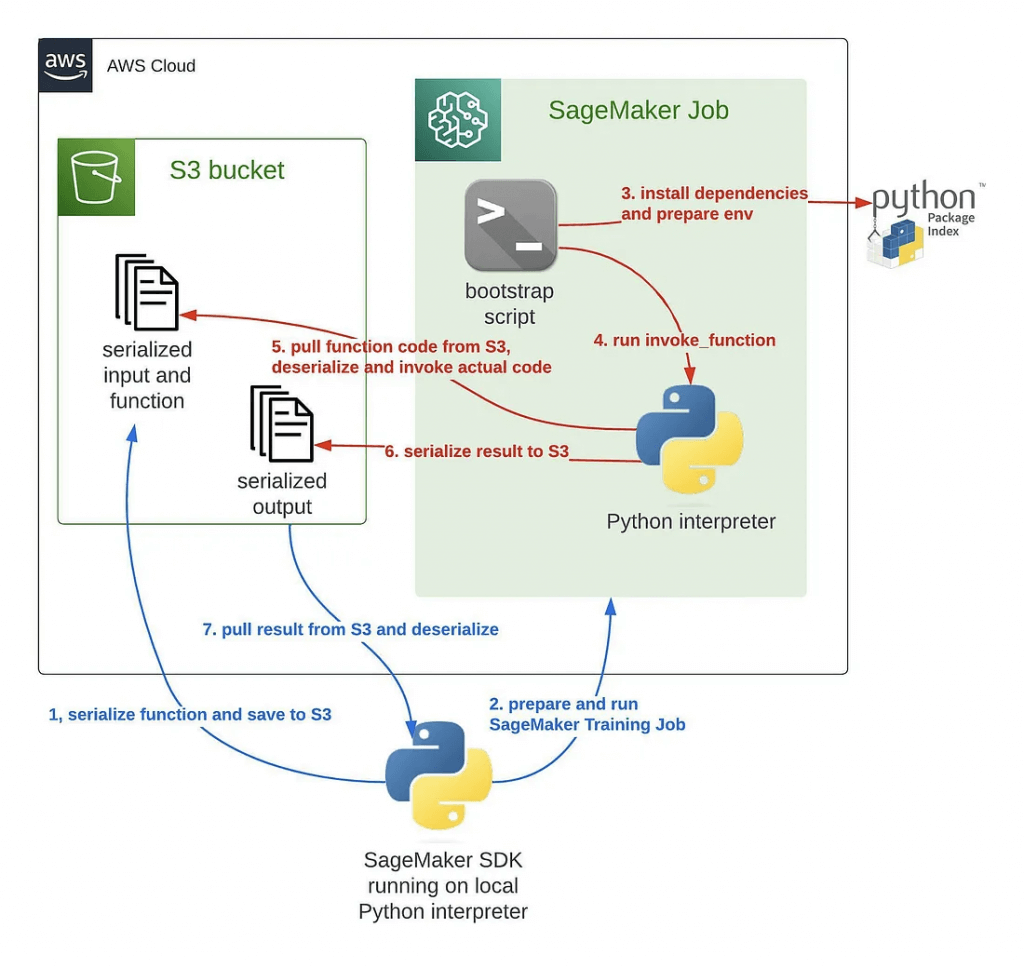
AWS Step Functions
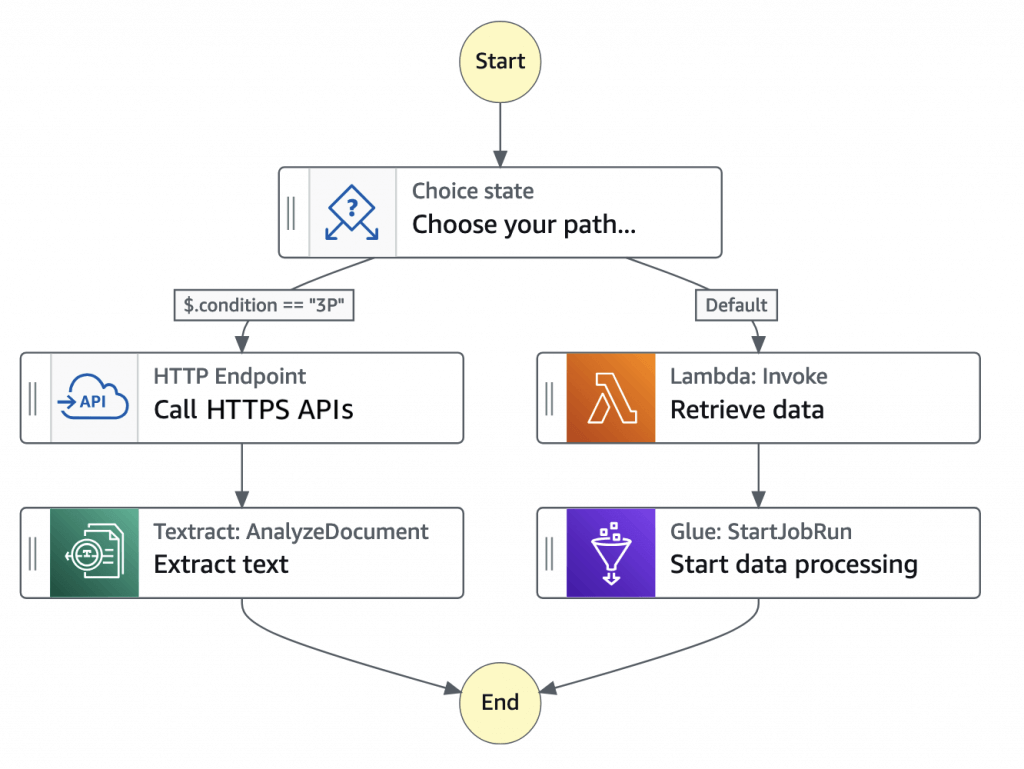
- create workflows, also called State machines, to build distributed applications, automate processes, orchestrate microservices, and create data and machine learning pipelines
- based on state machines and tasks. In Step Functions, state machines are called workflows, which are a series of event-driven steps. Each step in a workflow is called a state. For example, a Task state represents a unit of work that another AWS service performs, such as calling another AWS service or API. Instances of running workflows performing tasks are called executions in Step Functions.
- The work in your state machine tasks can also be done using Activities which are workers that exist outside of Step Functions.
| Integrated service | Request Response | Run a Job – .sync | Wait for Callback – .waitForTaskToken |
|---|---|---|---|
| Amazon API Gateway | Standard & Express | Not supported | Standard |
| Amazon Athena | Standard & Express | Standard | Not supported |
| AWS Batch | Standard & Express | Standard | Not supported |
| Amazon Bedrock | Standard & Express | Standard | Standard |
| AWS CodeBuild | Standard & Express | Standard | Not supported |
| Amazon DynamoDB | Standard & Express | Not supported | Not supported |
| Amazon ECS/Fargate | Standard & Express | Standard | Standard |
| Amazon EKS | Standard & Express | Standard | Standard |
| Amazon EMR | Standard & Express | Standard | Not supported |
| Amazon EMR on EKS | Standard & Express | Standard | Not supported |
| Amazon EMR Serverless | Standard & Express | Standard | Not supported |
| Amazon EventBridge | Standard & Express | Not supported | Standard |
| AWS Glue | Standard & Express | Standard | Not supported |
| AWS Glue DataBrew | Standard & Express | Standard | Not supported |
| AWS Lambda | Standard & Express | Not supported | Standard |
| AWS Elemental MediaConvert | Standard & Express | Standard | Not supported |
| Amazon SageMaker AI | Standard & Express | Standard | Not supported |
| Amazon SNS | Standard & Express | Not supported | Standard |
| Amazon SQS | Standard & Express | Not supported | Standard |
| AWS Step Functions | Standard & Express | Standard | Standard |
— Kubernetes —
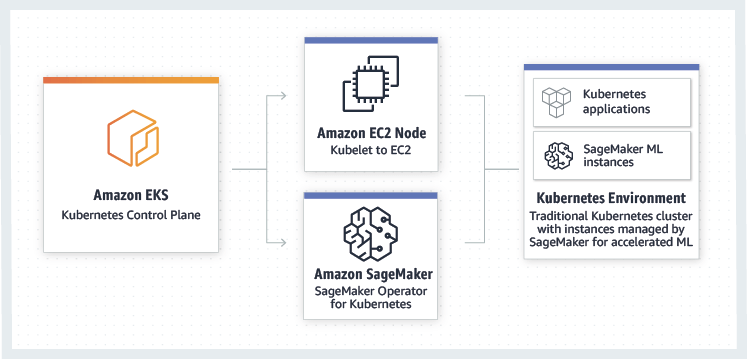
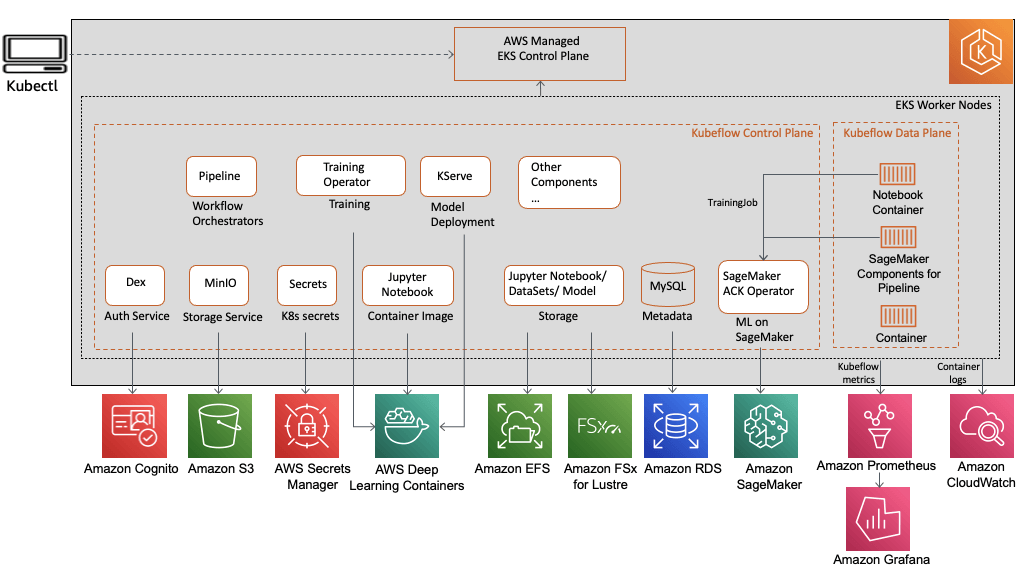
Amazon SageMaker Operators for Kubernetes
- Integrates SageMaker with Kubernetes-based ML infrastructure
- Components for Kubeflow Pipelines
- Enables hybrid ML workflows (on-prem + cloud)
- Enables integration of existing ML platforms built on Kubernetes / Kubeflow
— MISC —
Managing SageMaker Resources
- In general, algorithms that rely on deep learning will benefit from GPU instances (P3, g4dn) for training
- Inference is usually less demanding and you can often get away with compute instances there (C5)
- Can use EC2 Spot instances for training
- Save up to 90% over on-demand instances
- Spot instances can be interrupted!
- Use checkpoints to S3 so training can resume
- Can increase training time as you need to wait for spot instances to become available
- Elastic Inference (EI) / Amazon SageMaker Inference
- attach just the right amount of GPU-powered acceleration to any Amazon EC2 and Amazon SageMaker instance
- Accelerates deep learning inference
- At fraction of cost of using a GPU instance for inference
- EI accelerators may be added alongside a CPU instance
- ml.eia1.medium / large / xlarge
- EI accelerators may also be applied to notebooks
- Works with Tensorflow, PyTorch, and MXNet pre-built containers
- ONNX may be used to export models to MXNet
- Works with custom containers built with EI-enabled Tensorflow, PyTorch, or MXNet
- Works with Image Classification and Object Detection built-in algorithms
- Automatic Scaling
- “Real-time endpoints” typically keep instances running even when there is no traffic; so it’s good to solve the peak traffic, but not the best cost-saving
- Serverless Inference
- Specify your container, memory requirement, concurrency requirements
- Underlying capacity is automatically provisioned and scaled
- Good for infrequent or unpredictable traffic; will scale down to zero when there are no
requests- a cost-effective option for workloads with intermittent or unpredictable traffic
- “Provisioned Concurrency” ensures that the model is always available, with extra cost for the reserved capacity even unused; but this can prevent the “cold-start” issue
- Charged based on usage
- Monitor via CloudWatch
- ModelSetupTime, Invocations, MemoryUtilization
- Amazon SageMaker Inference Recommender
- Availability Zones
- automatically attempts to distribute instances across availability zones
- Deploy multiple instances for each production endpoint
- Configure VPC’s with at least two subnets, each in a different AZ
== SECURITY ==
SageMaker Security
- Use Identity and Access Management (IAM)
- User permissions for:
- CreateTrainingJob
- CreateModel
- CreateEndpointConfig
- CreateTransformJob
- CreateHyperParameterTuningJob
- CreateNotebookInstance
- UpdateNotebookInstance
- Predefined policies:
- AmazonSageMakerReadOnly
- AmazonSageMakerFullAccess
- AdministratorAccess
- DataScientist
- User permissions for:
- Set up user accounts with only the permissions they need
- Use MFA
- Use SSL/TLS when connecting to anything
- Use CloudTrail to log API and user activity
- Use encryption
- AWS Key Management Service (KMS)
- Accepted by notebooks and all SageMaker jobs
- Training, tuning, batch transform, endpoints
- Notebooks and everything under /opt/ml/ and /tmp can be encrypted with a KMS key
- Accepted by notebooks and all SageMaker jobs
- S3
- Can use encrypted S3 buckets for training data and hosting models
- S3 can also use KMS
- Protecting Data in Transit
- All traffic supports TLS / SSL
- IAM roles are assigned to SageMaker to give it permissions to access resources
- Inter-node training communication may be optionally encrypted
- Can increase training time and cost with deep learning
- AKA inter-container traffic encryption
- Enabled via console or API when setting up a training or tuning job
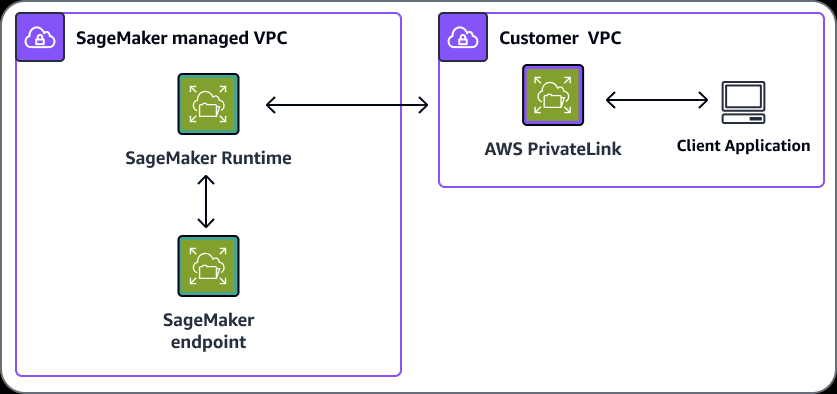
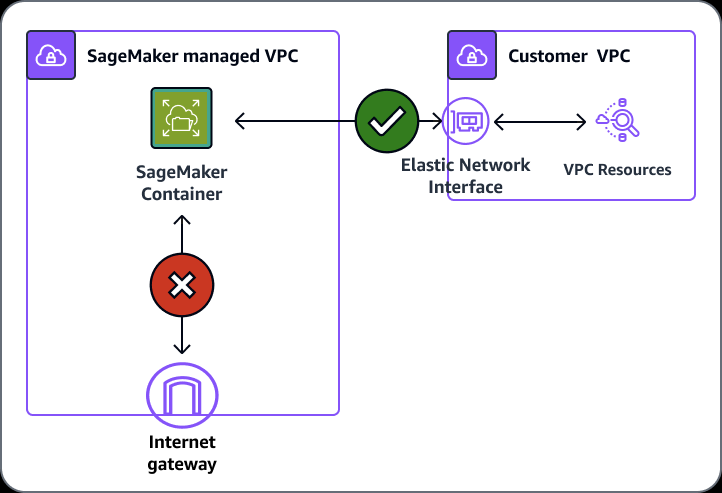
- VPC
- Training jobs run in a Virtual Private Cloud (VPC)
- You can use a private VPC for even more security
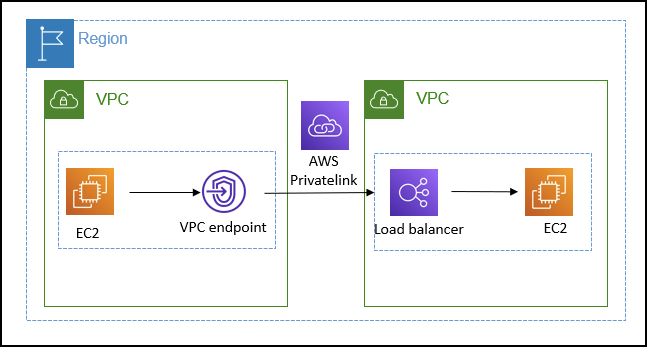
- You’ll need to set up S3 VPC endpoints
- Custom endpoint policies and S3 bucket policies can keep this secure
- Notebooks are Internet-enabled by default
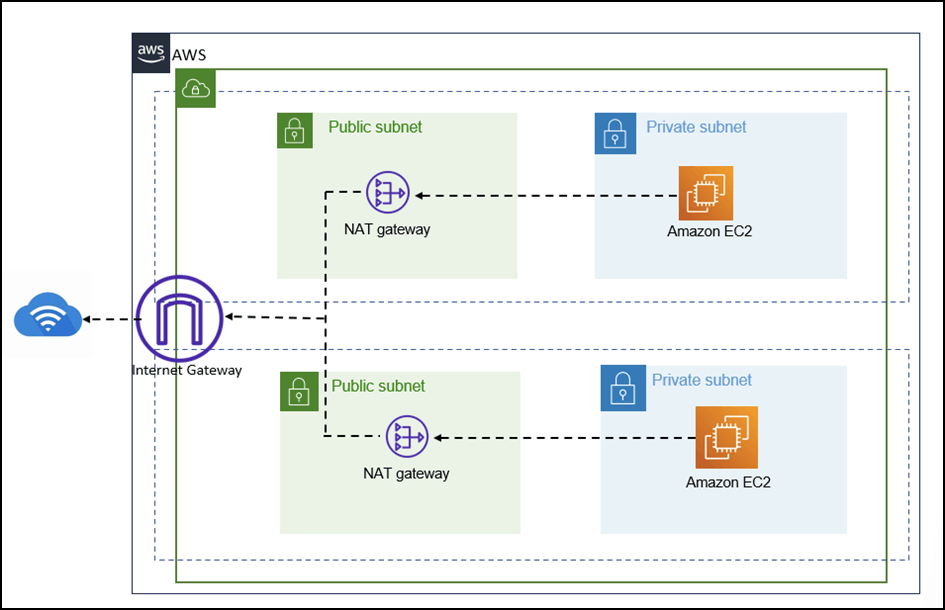
- If disabled, your VPC needs
- an interface endpoint (PrivateLink) and allow outbound connections (to other AWS services, like S3, AWS Comprehend), for training and hosting to work
- or NAT Gateway, and allow outbound connections (to Internet), for training and hosting to work
- If disabled, your VPC needs
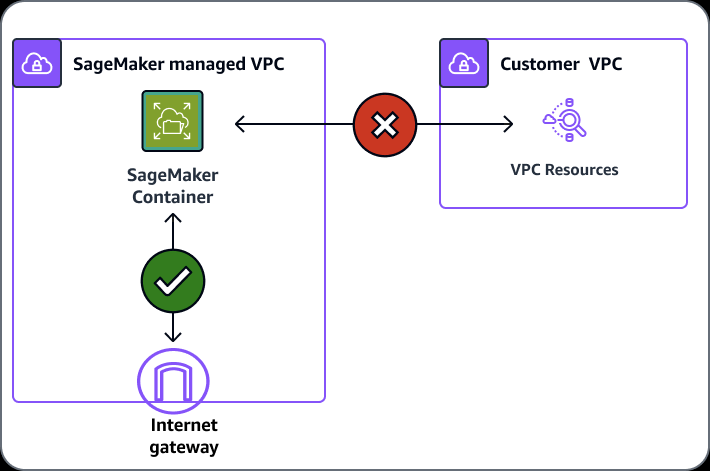
- Training and Inference Containers are also Internet-enabled by default
- Network isolation is an option, but this also prevents S3 access
- Enable the SageMaker parameter EnableNetworkIsolation for the notebook instances; so the instances wouldn’t be accessible from the Internet
- Network isolation is an option, but this also prevents S3 access
- Logging and Monitoring
- CloudWatch can log, monitor and alarm on:
- Invocations and latency of endpoints
- Health of instance nodes (CPU, memory, etc)
- Ground Truth (active workers, how much they are doing)
- CloudTrail records actions from users, roles, and services within SageMaker
- Log files delivered to S3 for auditing
- CloudWatch can log, monitor and alarm on:
== COST OPTIMISATION ==
AWS Cost Management
- Operations for Cost Allocation Tracking/Analysis
- STEP ONE: create user-defined tags with key-value pairs that reflect attributes such as project names or departments to ensure proper categorization of resources
- STEP TWO: apply these tags to the relevant resources to enable tracking
- STEP THREE: enable the cost allocation tags in the Billing console
- (AFTER) STEP FOUR: Configure tag-based cost and usage reports (AWS Cost Allocation Reports) for detailed analysis in Cost Explorer