Training is the first phase for an AI model. Training may involve a process of trial and error, or a process of showing the model examples of the desired inputs and outputs, or both.
Inference is the process that follows AI training. The better trained a model is, and the more fine-tuned it is, the better its inferences will be — although they are never guaranteed to be perfect.
The core of reasoning/inference is to apply a trained AI model to new data and make decisions based on the model’s predictions.
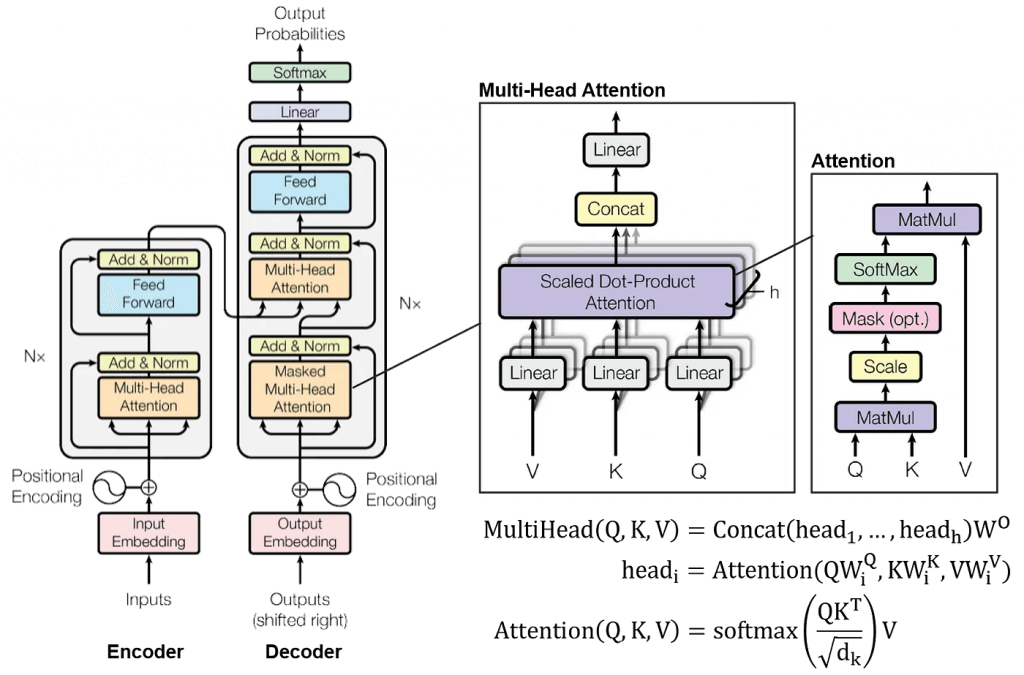
Transformer Architecture
used in Natural Language Processing (NLP)
Meaning is a result of relationships between things, and self-attention is a general way of learning relationships
A transformer is a type of artificial intelligence model that learns to understand and generate human-like text by analyzing patterns in large amounts of text data.
They are specifically designed to comprehend context and meaning by analyzing the relationship between different elements, and they rely almost entirely on a mathematical technique called attention to do so.
Adopts mechanism of “self-attention”
Weighs significance of each part of the input data
Processes sequential data (like words, like an RNN), but processes entire input all at once.
The attention mechanism provides context, so no need to process one word at a time.
With FFNN, it becomes parallel processing
Model zoos such as Hugging Face offer pre-trained models to start from
Integrated with Sagemaker via Hugging Face Deep Learning Containers (DLC)
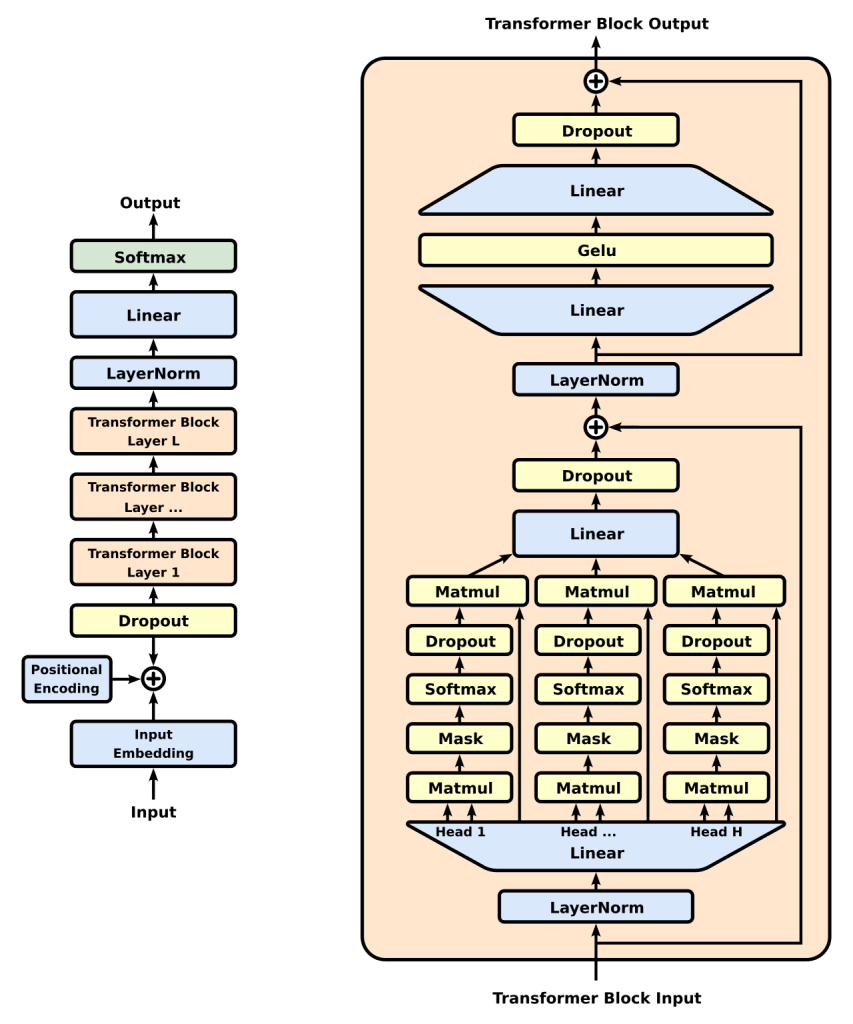
Components
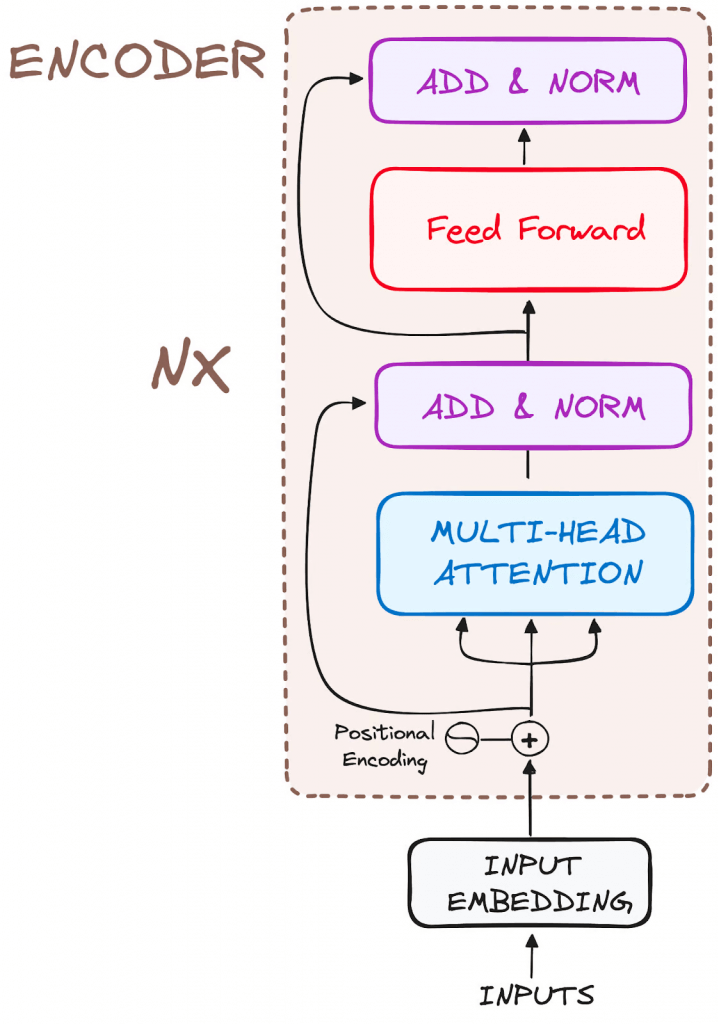
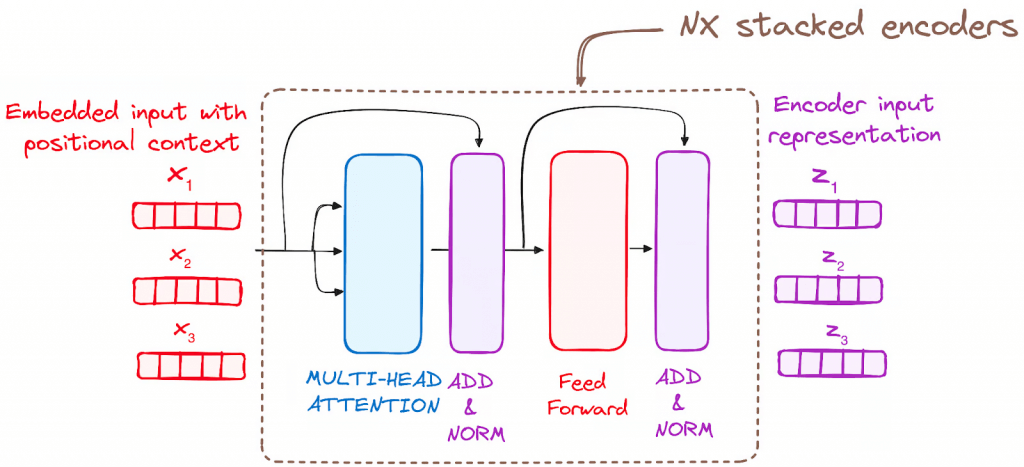
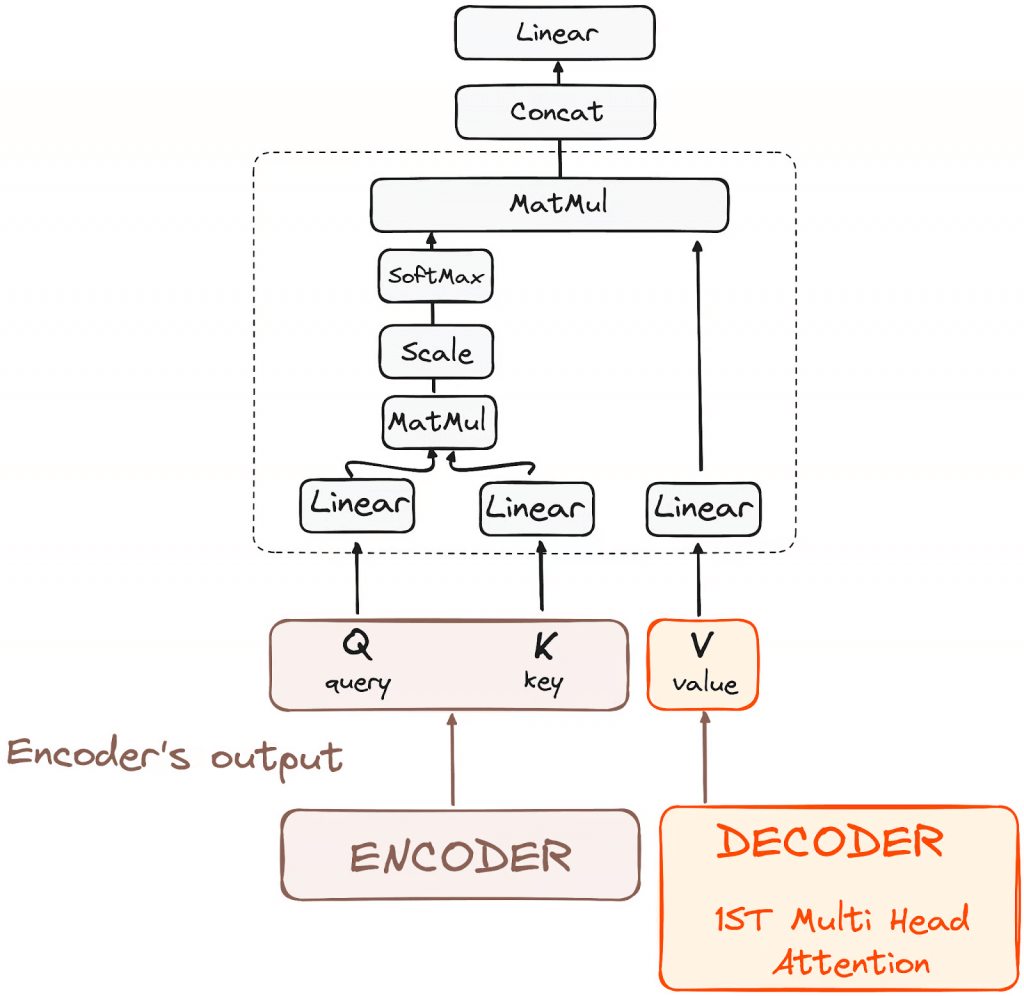
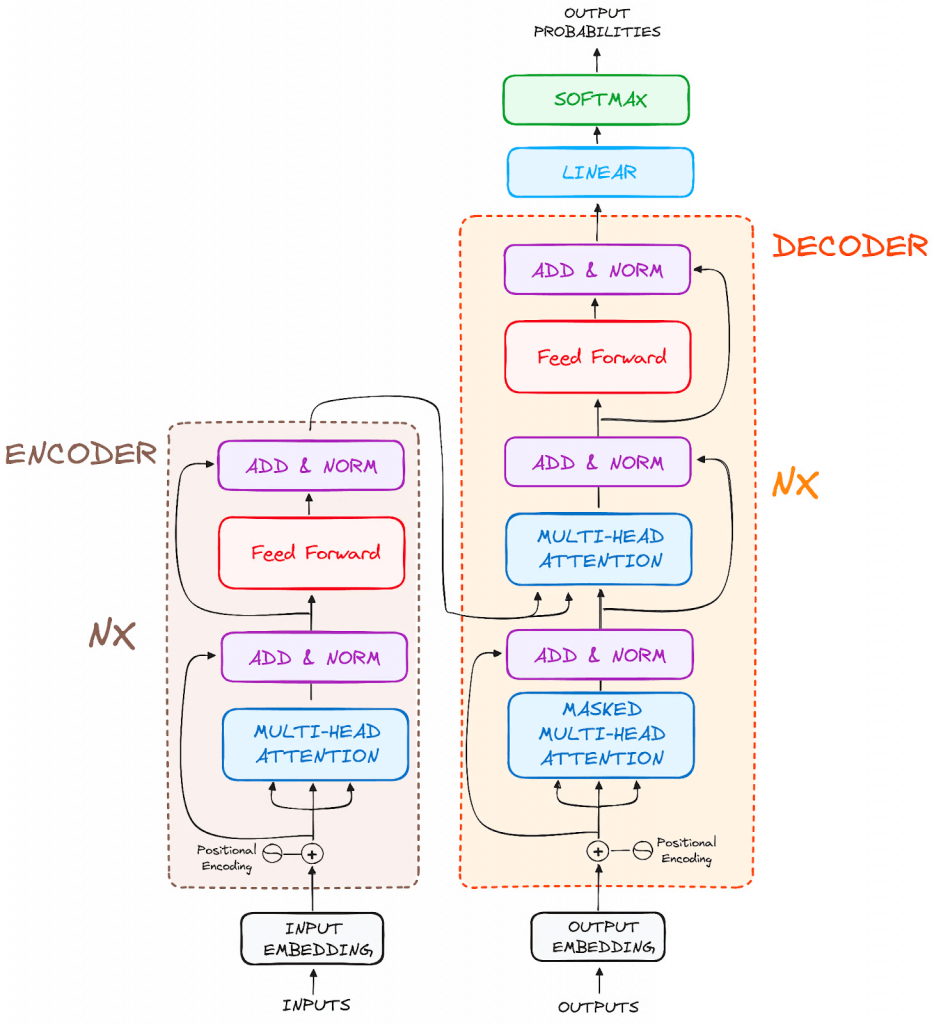
Encoder
to transform the input tokens into contextualized representations. Unlike earlier models that processed tokens independently, the Transformer encoder captures the context of each token with respect to the entire sequence.
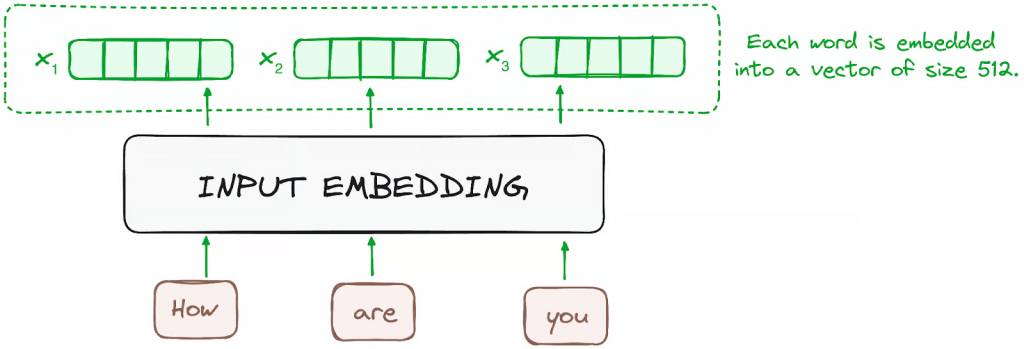
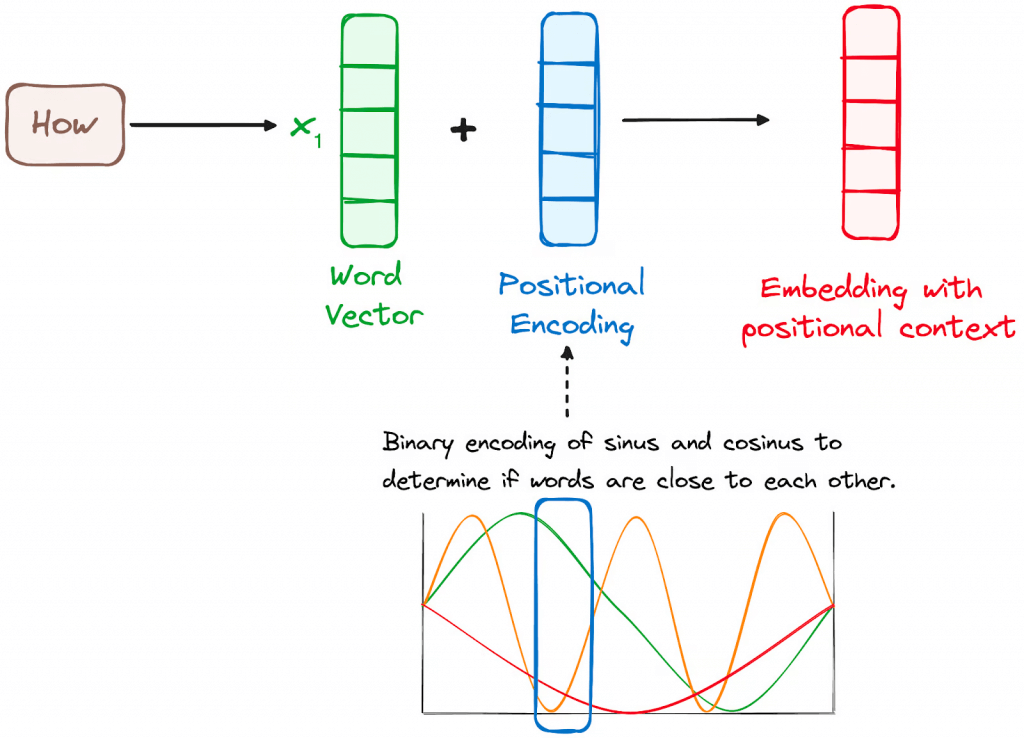
Input Embeddings
converting input tokens – words or subwords – into vectors using embedding layers. These embeddings capture the semantic meaning of the tokens and convert them into numerical vectors.
Positional Encoding
use positional encodings added to the input embeddings to provide information about the position of each token in the sequence.
Stack of Encoder Layers
The encoder layer serves to transform all input sequences into a continuous, abstract representation that encapsulates the learned information from the entire sequence.
Multi-headed attention mechanism.
enables the models to relate each word in the input with other words
Normalization and Residual Connections
Feed-Forward Neural Network
Output of the Encoder
Additionally, it incorporates residual connections around each sublayer, which are then followed by layer normalization.
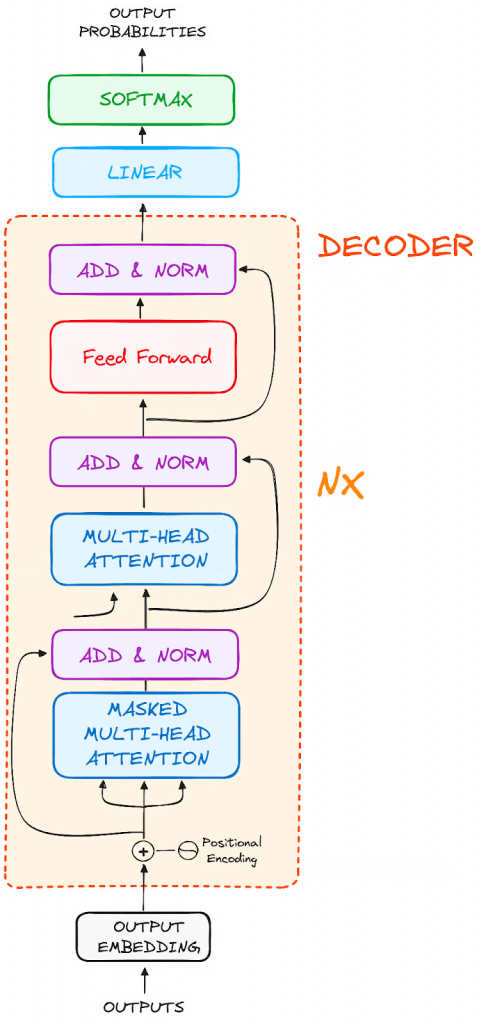
Decoder
Output Embeddings (mimic the Input Embeddings in Encoder)
Positional Encoding
Masked Self-Attention Mechanism
Similiar with Self-Attention Mechanism in Encoder
But, prevents positions from attending to subsequent positions, which means that each word in the sequence isn’t influenced by future tokens.
the predictions for a particular position can only depend on known outputs at positions before it.
Encoder-Decoder Multi-Head Attention or Cross Attention
Feed-Forward Neural Network
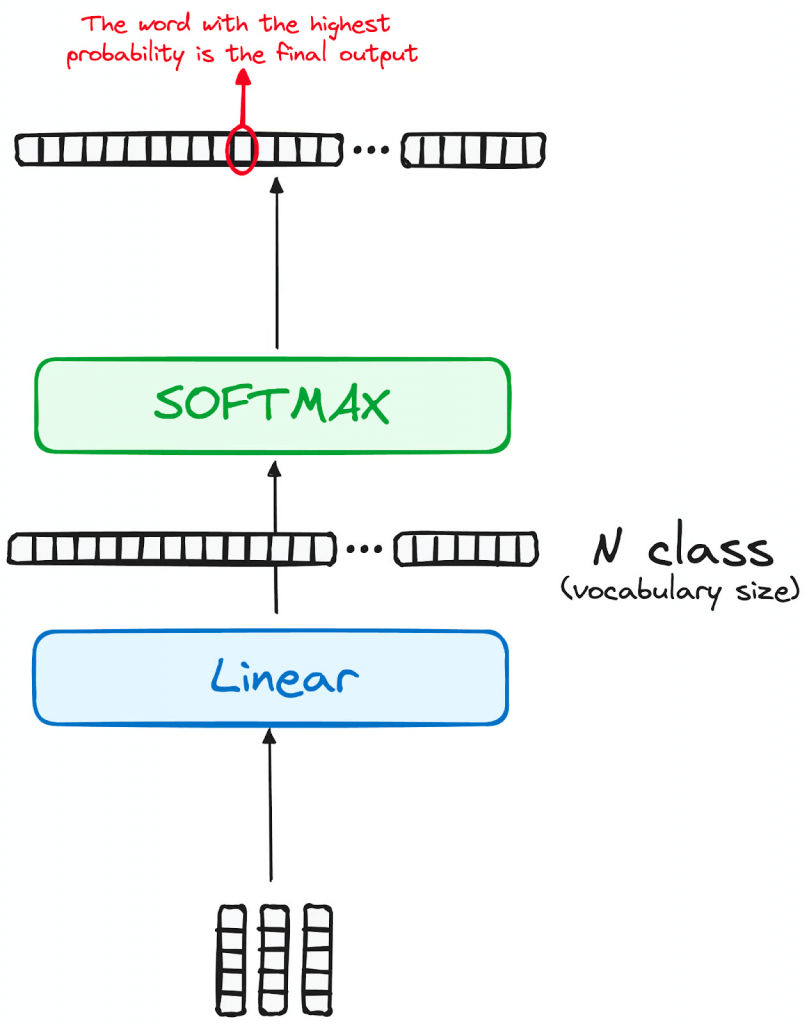
Linear Classifier and Softmax for Generating Output Probabilities
The journey of data through the transformer model culminates in its passage through a final linear layer, which functions as a classifier.
The size of this classifier corresponds to the total number of classes involved (number of words contained in the vocabulary). For instance, in a scenario with 1000 distinct classes representing 1000 different words, the classifier’s output will be an array with 1000 elements.
This output is then introduced to a softmax layer, which transforms it into a range of probability scores, each lying between 0 and 1. The highest of these probability scores is key, its corresponding index directly points to the word that the model predicts as the next in the sequence.
BERT: Bi-directional Encoder Representations from Transformers
enables the model to have more context-informed predictions about what the next word should be
DistilBERT: uses knowledge distillation to reduce model size by 40%
fine-tune BERT (or DistilBERT etc) with your own additional training data through transfer learning
GPT: Generative Pre-trained Transformer (only use Decoder)
Feature
GPT (Generative Pre-trained Transformer)
BERT (Bidirectional Encoder Representations from Transformers)
Core Architecture
Autoregressive, generative
Bidirectional, context-based
Training Approach
Predicts the next word in a sequence
Uses masked language modeling to predict words from context
Direction of Context
Unidirectional (forward)
Bidirectional (both forward and backward)
Primary Usage
Text generation
Text analysis and understanding
Generative Capabilities
Yes, designed to generate coherent text
No, focuses on understanding text not generating
Pre-training
Trained on large text corpora
Trained on large text corpora with masked words
Fine-tuning
Necessary for specific tasks
Necessary, but effective with fewer training examples
Output
Generates new text sequences
Provides contextual embeddings for various NLP tasks
Transfer Learning
Continue training a pre-trained model (fine-tuning)
Add new trainable layers to the top of a frozen model Learns to turn old features into predictions on new data
Can do both: add new layers, then fine tune as well
Retrain from scratch
If you have large amounts of training data, and it’s fundamentally different from what the model was pre-trained with
Use it as-is
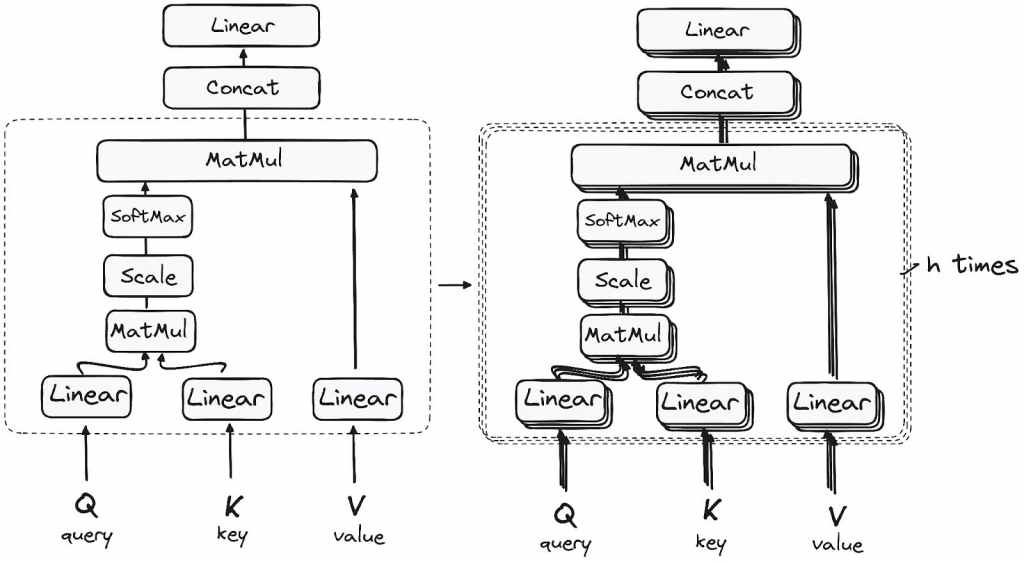
Self-Attention
Each encoder or decoder has a list of embeddings (vectors) for each token
Self-attention produces a weighted average of all token embeddings. The magic is in computing the attention weights.
This results in tokens being tied to other tokens that are important for it
Three matrices of weights are learned through back-propagation ???
Query (Wq)
Key (Wk)
Value (Wv)
Every token gets a query (q), key (k), and value (v) vector by multiplying its embedding against these matrices
Compute a score for each token by multiplying (dot product) its query with each key
“Scaled dot-product attention”
Dot product is just one similarity function we can use.
In practice, softmax is then applied to the scores to normalize them.
Generative Pre-Trained Transformer (GPT)
Leverages a “decoder-only” Transformer architecture.
GPT uses a special kind of attention called “masked self-attention”. This allows it to focus on the preceding words of a sentence while generating new text, preventing it from ‘seeing’ future words and ensuring the output is coherent and flows naturally.
Benefits
Unsupervised Learning: the decoder-only setup lets it predict the next word given the preceding ones
Efficiency, especially text generation
Input Processing
Tokenization
Token embedding
Captures semantic relationships between tokens, token similarities
Position embedding
Captures the position of the token in the input relative to other nearby tokens
Output Processing
Vector from the decorder stacks
Multiply with the token embeddings
Logits is the probabilities of each token being the right next token (word) in the sequence
(optional) Randomize/temperature, instead of always picking the highest probability
Foundation Models
GPT-n (OpenAI, Microsoft)
BERT (Google)
DALL-E (OpenAI, Microsoft)
LLaMa (Meta)
Segment Anything (Meta)
Jurassic-2 (AI21labs)
Multilingual LLMs for text generation
Claude (Anthropic)
LLM’s for conversations
Question answering
Workflow automation
Stable Diffusion (stability.ai)
Image, art, logo, design generation
Amazon Titan
Text summarization
Text generation
Q&A
Embeddings (Personalization, Search)
Aspect
BERT
GPT
Architecture
Utilizes a bidirectional Transformer architecture, meaning it processes the input text in both directions simultaneously. This allows BERT to capture the context around each word, considering all the words in the sentence.
Employs a unidirectional Transformer architecture, processing the text from left to right. This design enables GPT to predict the next word in a sequence but limits its understanding of the context to the left of a given word.
Training Objective
Trained using a masked language model (MLM) task, where random words in a sentence are masked, and the model predicts masked words based on the surrounding context. This helps in understanding the relationships between words.
Trained using a causal language model(CLM) task, where the model predicts the next word in a sequence. This objective helps GPT in generating coherent and contextually relevant text.
Pre-training
Captures the context from both the left and right of a word, providing a more comprehensive understanding of the sentence structure and semantics.
Pre-trained solely on a causal language model task, focusing on understanding the sequential nature of the text.
Fine-tuning
Can be fine-tuned for various specific NLP tasks like question answering, named entity recognition, etc., by adding task-specific layers on top of the pre-trained model.
Can be fine-tuned for specific tasks like text generation and translation by adapting the pre-trained model to the particular task.
Bidirectional Understanding
Captures the context from both left and right of a word, providing a more comprehensive understanding of the sentence structure and semantics.
Understands context only from the left of a word, which may limit its ability to fully grasp the relationships between words in some cases.
Use Cases
BERT is very good at solving sentence and token-level classification tasks. Extensions of BERT (e.g., sBERT) can be used for semantic search, making BERT applicable to retrieval tasks as well. Finetuning BERT to solve classification tasks is oftentimes preferable to performing few-shot prompting via an LLM.
Encoder-only models such as BERT cannot generate text. This is where we need decoder-only models such as GPT. They are suitable for tasks like text generation, translation, etc.
Real-World Example
Used in Google Search to understand the context of search queries, enhancing the relevance and accuracy of search results.
Models like GPT-3 are employed to generate human-like text responses in various applications, including chatbots, content creation, and more.
Amazon Bedrock
a fully managed service that makes high-performing foundation models (FMs) from leading AI companies and Amazon available for your use through a unified API
An API for Foundation Models (FM)
AI21 Labs
Amazon Titan
Amazon Titan Text: text generation (open-ended and context-based question answering, code generation, and summarization)
Amazon Titan Text Embeddings: Text embeddings represent meaningful vector representations of unstructured text such as documents, paragraphs, and sentences.
Amazon Titan Multimodal Embeddings
Amazon Titan Image Generator: image generation
Anthropic
Cohere
DeepSeek
Luma AI
Meta
Mistral AI
Stability AI
Serverless / Fully managed (customer do not need to handle the underlying infrastructure)
Fine-tuning API
Provide labeled examples in S3
Data is only used in your copy of the FM
Data is encrypted and does not leave your VPC
Also support private customization of foundation models
Use cases
Text generation
Virtual assistants (chatbots)
Text and image search
Text summarization
Image generation
Implement cases
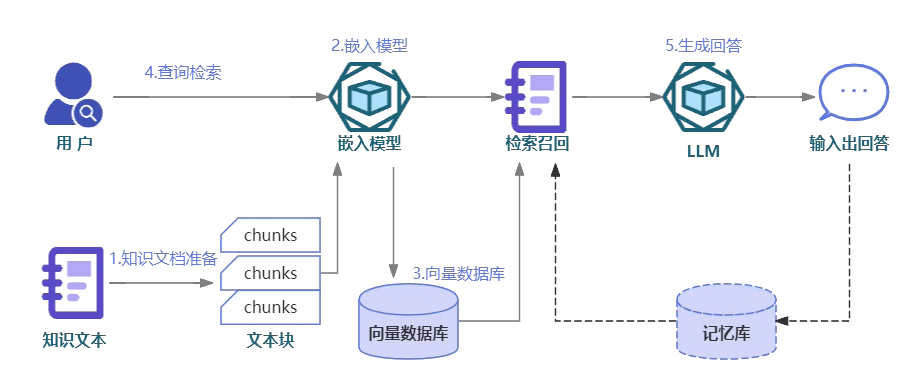
Knowledge Base: By creating and configuring a knowledge base in Amazon Bedrock, you can ensure that the data stored in the S3 bucket is utilized effectively as the foundation for the chatbot’s knowledge base.
Step 1: Set up an Amazon S3 bucket.
Step 2: Configure a knowledge base in Amazon Bedrock and link it to the Amazon S3 bucket as the data source.
Step 3: Load the information into the knowledge base.
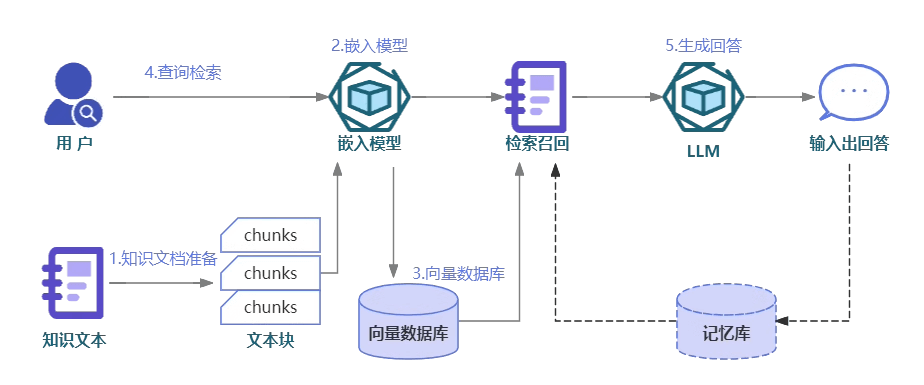
In a RAG setup, the retrieval process involves querying the Amazon OpenSearch Service vector database with a natural language query, using vector similarity search to find the most relevant sections of documents. These retrieved document vectors are then passed to a large language model (LLM) for generating the final response. Similarly, the knowledge base created in Amazon Bedrock can be queried by the retrieval component to identify the most relevant operational procedures, which are then used by the LLM to craft a response.
To setup RAG
the retrieval process involves querying the Amazon OpenSearch Service vector database with a natural language query, using vector similarity search to find the most relevant sections of documents. These retrieved document vectors are then passed to a large language model (LLM) for generating the final response. Similarly, the knowledge base created in Amazon Bedrock can be queried by the retrieval component to identify the most relevant operational procedures, which are then used by the LLM to craft a response
Model customization: the process of providing training data to a model in order to improve its performance for specific use-cases
Step 1: Prepare a labeled dataset and, if needed, a validation dataset. Ensure the training data is in the required format, such as JSON Lines (JSONL), for structured input and output pairs.
Step 2: Configure IAM permissions to access the S3 buckets containing your data. You can either use an existing IAM role or let the console create a new one with the necessary permissions.
Step 3: Optionally set up KMS keys and/or a VPC for additional security to protect your data and secure communication.
Step 4: Start a training job by either fine-tuning a model on your dataset or continuing pre-training with additional data. Adjust hyperparameters to optimize performance.
Step 5: After the fine-tuning job is complete, analyze the results by reviewing the training or validation metrics to evaluate the model’s performance.
Step 6: Buy Provisioned Throughput for the fine-tuned model to support high-throughput deployment and handle the expected load.
Step 7: Deploy the customized model and use it for inference tasks in Amazon Bedrock. The model will now have enhanced capabilities tailored to your specific needs.
Amazon Q Developer (previous CodeWhisperer)
AI coding assistant
Real-time code suggestions
Write a comment of what you want
It suggests blocks of code into your IDE
Based on LLM’s trained on Amazon’s code and open source code
Security scans
Analyzes code for vulnerabilities
Reference tracker
Flags suggestions that are similar to open source code
Provides annotations for proper attribution
Security
All content transmitted with TLS
Encrypted in transit
Encrypted at rest
However – Amazon is allowed to mine your data for individual plans
AWS HealthScribe
Automatically create clinical notes from patient-clinician conversations using generative AI
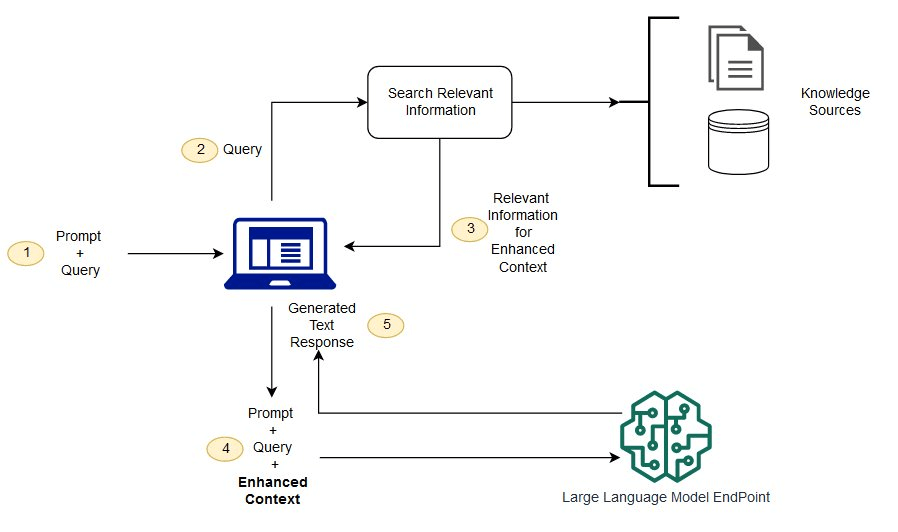
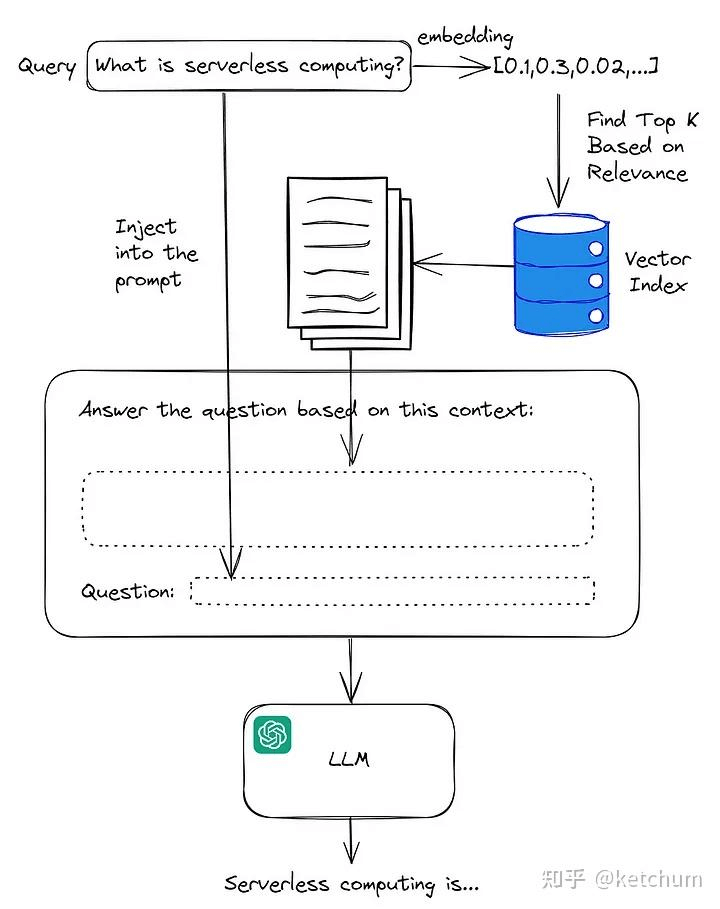
Retrieval-Augmented Generation (RAG)
the process of optimizing the output of a large language model, so it references an authoritative knowledge base outside of its training data sources before generating a response
a technique used in natural language processing (NLP) that combines the strengths of retrieval-based and generation-based models. It involves retrieving relevant information from a knowledge base and then using a language model to generate a response based on the retrieved information.
Vector databases are suitable to store information for RAG use cases.